 |
To match how I have chosen to cover sorting in 302/307 I have divided Dr. Plank's notes into two sections. Loosely, these are the following simple O(n^2) methods, which will be compared to more complex/recursive methods next week. These notes have sample code, and sample runs, that we hope help with your submitted Reading (Reading02) this week.
#include <iostream>
#include <vector>
using namespace std;
#include "sorting.h"
void sort_doubles(vector <double> &v, int print)
{
int j;
if (print) {
for (j = 0; j < v.size(); j++) printf("%4.2lf ", v[j]);
cout << endl;
}
return;
}
|
Since it doesn't sort at all, the code above could be useful as a base case for timing other algorithms that do sort elements.
Bubble sort works with the following inner loop:
2 4 3 1Then, when you perform an iteration of bubble sort, you'll skip over the value 2, but you'll swap 3 and 4. Next, you'll be looking at 4 again, and it's greater than 1, so you'll swap them. Since 4 is now at the last element, you're done. The vector is now:
2 3 1 4You'll note that after an iteration, the largest element will always be at the last index. That's good, because if you want to do another iteration, you don't have to worry about that last element -- it's already where it belongs.
You'll also note that whenever an element moves to a smaller index, it can only do that once per iteration. Thus, if the smallest value starts at the highest index, you'll have do do n-1 iterations to get it to the beginning. Such is bubble sort. You iterate n-1 times, and at each iteration, you perform the "inner loop" above. Each time you perform it, you can skip an additional element at the end of the vector, because the previous iteration has already placed that element where it belongs. Here's bubble_sort.cpp, without the code to print the vector, and without the headers:
void sort_doubles(vector <double> &v, int print)
{
int i, j, n;
double tmp;
// The vector is printed here, but I've omitted the code.
n = v.size();
for (i = 0; i < n-1; i++) {
/* This is the inner loop. Each time you perform it, you can stop
one step closer to the beginning of the vector, because the previous
iteration has placed the element where it belongs. */
for (j = 0; j < n-i-1; j++) {
if (v[j] > v[j+1]) {
tmp = v[j];
v[j] = v[j+1];
v[j+1] = tmp;
}
}
// The vector is printed here, but I've omitted the code.
}
}
|
Suppose we run this on an 8-element vector. You'll see that we need all 7 iterations to get the smallest element from the right side to the left side. This is colored so that you can more clearly see the elements that are inspected in each loop.
| UNIX> ./bubble_sort 8
Before the loop: | 3.62 6.14 4.35 3.88 4.12 8.09 6.28 0.72
i = 0 | 3.62 4.35 3.88 4.12 6.14 6.28 0.72 8.09
i = 1 | 3.62 3.88 4.12 4.35 6.14 0.72 6.28 8.09
i = 2 | 3.62 3.88 4.12 4.35 0.72 6.14 6.28 8.09
i = 3 | 3.62 3.88 4.12 0.72 4.35 6.14 6.28 8.09
i = 4 | 3.62 3.88 0.72 4.12 4.35 6.14 6.28 8.09
i = 5 | 3.62 0.72 3.88 4.12 4.35 6.14 6.28 8.09
i = 6 | 0.72 3.62 3.88 4.12 4.35 6.14 6.28 8.09
| UNIX>
|
If you count the number of elements that are inspected over the course of the algorithm, that is:
That is equal to n(n-1)/2 - 1, which is clearly O(n2). For that reason, bubble sort is a really slow algorithm (we can always sort in O(n log(n)) time, which is much faster). And for that reason, we never use bubble sort.
Selection sort is pretty straightforward:
Before looking at any code, let's look at the output to make sure we know what's going on:
| UNIX> ./selection_sort 8
Before the loop: | 4.91 9.10 6.96 9.22 4.24 5.93 1.32 4.50
i = 0 | 1.32 9.10 6.96 9.22 4.24 5.93 4.91 4.50
i = 1 | 1.32 4.24 6.96 9.22 9.10 5.93 4.91 4.50
i = 2 | 1.32 4.24 4.50 9.22 9.10 5.93 4.91 6.96
i = 3 | 1.32 4.24 4.50 4.91 9.10 5.93 9.22 6.96
i = 4 | 1.32 4.24 4.50 4.91 5.93 9.10 9.22 6.96
i = 5 | 1.32 4.24 4.50 4.91 5.93 6.96 9.22 9.10
i = 6 | 1.32 4.24 4.50 4.91 5.93 6.96 9.10 9.22
| UNIX>
|
What you see above is that in iteration i, we find the smallest value from indices i to the end of the vector, and then we swap that value with the value in index i. Those values are the ones in light blue. The values in yellow are those that are checked in that iteration. The number of colored elements are exactly the same as in bubble sort, which means that selection sort is O(n2) as well. Typically, it is faster than bubble sort, because it involves fewer swaps.
Here's the code (in selection_sort.cpp):
#include <iostream>
#include <vector>
using namespace std;
#include "sorting.h"
void sort_doubles(vector <double> &v, int print)
{
int i, j, k, n;
double tmp;
int minindex;
n = v.size();
/* Optionally print the vector before sorting */
if (print) {
for (k = 0; k < n; k++) printf("%4.2lf ", v[k]);
cout << endl;
}
/* Outer loop. At each of these iterations, we
are going to find the smallest element from
index i to the end, and swap it with the
element in index i. */
|
for (i = 0; i < n-1; i++) {
/* Put the index of the smallest element
starting at index i in minindex. */
minindex = i;
for (j = i+1; j < n; j++) {
if (v[j] < v[minindex]) {
minindex = j;
}
}
/* Now swap v[minindex] with v[i] */
tmp = v[i];
v[i] = v[minindex];
v[minindex] = tmp;
/* Optionally print the vector. */
if (print) {
for (k = 0; k < n; k++) printf("%4.2lf ", v[k]);
cout << endl;
}
}
}
|
| UNIX> ./insertion_1_sort 8
Before the loop. The first element is sorted. | 6.54 5.68 0.50 7.33 5.30 6.50 6.74 8.55
Iteration 0: The first 2 elements are sorted. | 5.68 6.54 0.50 7.33 5.30 6.50 6.74 8.55
Iteration 1: The first 3 elements are sorted. | 0.50 5.68 6.54 7.33 5.30 6.50 6.74 8.55
Iteration 2: The first 4 elements are sorted. | 0.50 5.68 6.54 7.33 5.30 6.50 6.74 8.55
Iteration 3: The first 5 elements are sorted. | 0.50 5.30 5.68 6.54 7.33 6.50 6.74 8.55
Iteration 4: The first 6 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 7.33 6.74 8.55
Iteration 5: The first 7 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 6.74 7.33 8.55
Iteration 6: All 8 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 6.74 7.33 8.55
| UNIX>
|
Now, think about how to implement this. At iteration i, the first i+1 elements are already sorted. The only element out of place is element i+2. For example, in the output above, when iteration 0 starts, the first element (6.54) is already sorted, and the element that is out of place is 5.68. Similarly, when iteration 1 starts, the first two elements (5.68 6.54) are already sorted, and the element that is out of place is 0.50.
So, our inner loop of insertion sort is going to look at the one element that is out place, and then put it in its proper place. To do so, it will insert it into its proper place, but it will have to move all of the elements greater than it over one, so that it can make room. Let's annotate the output on seed 4 a little more. What I'll do is show the element that is inserted in blue, and the elements that have to be "moved over" in yellow:
| UNIX> ./insertion_1_sort 8 1 4 yes yes
Before the loop. The first element is sorted. | 6.54 5.68 0.50 7.33 5.30 6.50 6.74 8.55
Iteration 0: The first 2 elements are sorted. | 5.68 6.54 0.50 7.33 5.30 6.50 6.74 8.55
Iteration 1: The first 3 elements are sorted. | 0.50 5.68 6.54 7.33 5.30 6.50 6.74 8.55
Iteration 2: The first 4 elements are sorted. | 0.50 5.68 6.54 7.33 5.30 6.50 6.74 8.55
Iteration 3: The first 5 elements are sorted. | 0.50 5.30 5.68 6.54 7.33 6.50 6.74 8.55
Iteration 4: The first 6 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 7.33 6.74 8.55
Iteration 5: The first 7 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 6.74 7.33 8.55
Iteration 6: All 8 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 6.74 7.33 8.55
| UNIX>
|
What makes insertion sort different than selection and bubble sort is that the number of operations that insertion sort takes in each inner loop is dependent on the element to be "inserted," and how many elements have to move to accomodate it. In the worst case, that element will go to the beginning of the vector, which will make insertion sort's running time be just like selection and bubble sort. In the "average" case, the element will have to go into the middle of the elements that precede it, which is still O(n2). But what makes insertion sort interesting is what happens when the element to be inserted is close to where it belongs. Then, insertion sort is much faster.
Before we think about that any more, let's look at implementations. Dr. Plank has three implementations that vary in their details. The first is insertion_1_sort.cpp, which is included in its entirety. Note, it works pretty much straight from the definition of insertion sort -- assume you have a sorted list of size i-1 and look at the ith element. Start at the right-hand side of the sorted list, and as long as the ith element is less than that element, swap the two. When you're done, the element will be in its proper place, and you have a sorted list of size i.
#include <iostream>
#include <vector>
#include "sorting.h"
using namespace std;
void sort_doubles(vector <double> &v, int print)
{
int i, j, k;
double tmp;
/* Optionally print the vector */
if (print) {
for (j = 0; j < v.size(); j++) printf("%.2lf ", v[j]);
cout << endl;
}
for (i = 1; i < v.size(); i++) {
|
/* Inner loop -- while element i is out of place,
swap it with the element in front of it. */
for (j = i; j >= 1 && v[j] < v[j-1]; j--) {
tmp = v[j-1];
v[j-1] = v[j];
v[j] = tmp;
}
/* Optionally print the vector */
if (print) {
for (j = 0; j < v.size(); j++) printf("%.2lf ", v[j]);
cout << endl;
}
}
}
|
Let's reconsider what makes insertion sort an interesting algorithm: When the input is already sorted, or "nearly" sorted, then it sorts in linear time rather than quadratic. That's because at each iteration, the element to be inserted is "close" to where it belongs. To see this, Dr. Plank has implemented a second driver program called sort_sorted.cpp which generates "nearly" sorted input and sorts it. Instead of simply inserting random numbers between 0 and 10, this program inserts i*0.1+drand48() into index i. This means that the vector contains the numbers from 0 to roughly v.size()/10.0, where each number is within 10 vector slots of its final sorted position.
To help you think about this, consider the element at index zero. Its value will be randomly distributed between 0 and 1. The element in index one will be randomly distributed between 0.1 and 1.1. And so on -- element zero has to be less than element 10, so you know that element zero is within 10 slots of its final resting place. Now, let's take a look at insertion sort sorting a specific instance of this "nearly" sorted vector as shown below:
UNIX> ./insertion_1_sorted 20 0.17 0.85 0.30 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.85 0.30 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.17 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.17 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.17 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.65 1.67 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.65 1.67 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.65 1.67 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.65 1.67 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.93 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.28 2.45 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.28 2.45 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 1.98 2.28 2.28 2.45 2.52 UNIX> |
Because each element is "near" where it should be, insertion sort takes very few operations.
To explore it further -- take a look at sorting 50,000 random elements, and 50,000 "nearly" sorted elements with insertion sort (all timings in this writeup are done on a Dell Linux workstation in 2009). The additional parameters are used by Dr. Plank to enable these experiments and are defined in the code we are using throughout these notes.
UNIX> time ./insertion_1_sort 50000 1 0 no no 3.768u 0.000s 0:03.76 100.0% 0+0k 0+0io 0pf+0w UNIX> time ./insertion_1_sorted 50000 1 0 no no 0.004u 0.008s 0:00.00 0.0% 0+0k 32+0io 0pf+0w UNIX>
The "user time" is the first word printed -- 3.768 seconds for unsorted input as opposed to 0.004 seconds for sorted input. The difference is stunning!
We can speed up our first implementation of insertion sort if we observe that the implementation above performs too much data movement. Think about the following output:
UNIX> ./insertion_1_sort 6 1 1 no yes 0.42 4.54 8.35 3.36 5.65 0.02 0.42 4.54 8.35 3.36 5.65 0.02 0.42 4.54 8.35 3.36 5.65 0.02 0.42 3.36 4.54 8.35 5.65 0.02 0.42 3.36 4.54 5.65 8.35 0.02 0.02 0.42 3.36 4.54 5.65 8.35 UNIX> |
Specifically, look at the two highlighted lines. When we perform the insertion of 0.02, think about what happens:
for (i = 1; i < v.size(); i++) {
tmp = v[i];
/* While v[j-1] is greater than v[i], move v[j-1] over one. */
for (j = i; j >= 1 && tmp < v[j-1]; j--) {
v[j] = v[j-1];
}
/* And put v[i] into its proper place. */
v[j] = tmp;
}
|
Note how it is faster than insertion_1_sort:
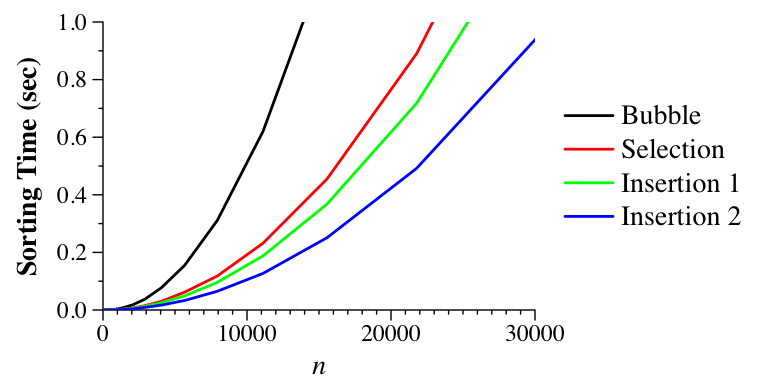
UNIX> time ./insertion_1_sort 50000 1 0 no no 3.792u 0.000s 0:03.80 99.7% 0+0k 0+0io 0pf+0w UNIX> time ./insertion_2_sort 50000 1 0 no no 2.584u 0.012s 0:02.59 100.0% 0+0k 32+0io 0pf+0w UNIX>Let's compare sorting algorithms graphically. To do so, I've written a shell script called do_timing.sh that varies the number of elements and times the given sorting program as it runs ten iterations. It uses the wall-clock time of the program (again on my Linux box in 2009). Dr. Plank has generated the results of timing all the programs in this lecture in the file all_timings.txt. Below, we graph the algorithms that we have seen so far:
|
So, insertion sort is the fastest (interestingly, this can vary from machine to machine. On Dr. Plank's Mac in 2009, selection sort was fastest).