Spring 2014 CS140 Final Exam - Answers and Grading
James S. Plank
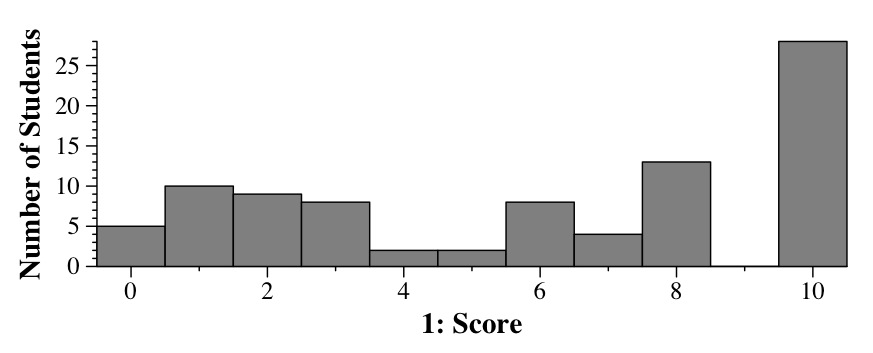
Question 1 - Big O - 10 Points
This question asked you to memorize the definition of Big-O, and apply
it to two concrete functions. If you're studying from this exam, what do
you study for this? You make sure you've memorized the definition of Big-O,
and then you know how to match T(n) and f(n) to a Big-O equation.
Let's recall the definition of Big-O from the lecture notes:
T(n) = O(f(n)) if there exists a constant c such that
c*f(n) >= T(n).
Here, f(n) = n3 and T(n) = 5n3 + 500 log2 (n).
And recall how we define "greater than or equal" with functions:
f(n) is greater than or equal to g(n)
if there is a value x0 so that for all x >= x0:
f(x) >= g(x)
Put them together, and you get I: For all n ≥ x0, cn3
≥ 5n3 + 500 log2 (n).
Now, given that, I'd say choose the largest c and x0, and you're safe.
That's answer J: c = 10, x0 = 1024.
We can prove it though -- for these two constants, you have:
10 (1024)3 = 10 (210)3 = 10 (230).
5 (1024)3 + log2(1024) = 5 (230) + 5,000.
It's pretty clear that the top number is bigger than the bottom, and the function will
be growing faster.
As it turns out, none of the other sets of constants work:
- With A, cn3 is zero.
- In B through D, 5n3 is always going to grow faster than
n3, so that won't work.
- In E through G, the two 5n3 terms are equal, so
cn3 will never be greater than
5n3 + 500 log2 (n).
- In H and I, when n = 2,
5n3 + 500 log2 (n) equals 40+500 = 540, and
10n3 equals 80. Thus, x0 is not big enough yet.
Grading
Five points for Part A and Part B.
I was very liberal with partial credit:
- Part A, you got 2.5 points for "close" answers: A, M, J, K.
- Part A, you got 1 points for "less close" answers: B, C, E, L, N, O.
- Part b, you got 3.5 points for H, and 2.5 for I, G and D.
Question 2 - Linked Lists - 16 points
The point of this question was to test your understanding of how linked lists are
implemented. There are detailed lecture notes for this, plus you implemented this
exact data structure in lab 8, so my hope was that you would be prepared. How do
you study for this? By reading through the lecture notes and making sure you
understand them.
Part A:
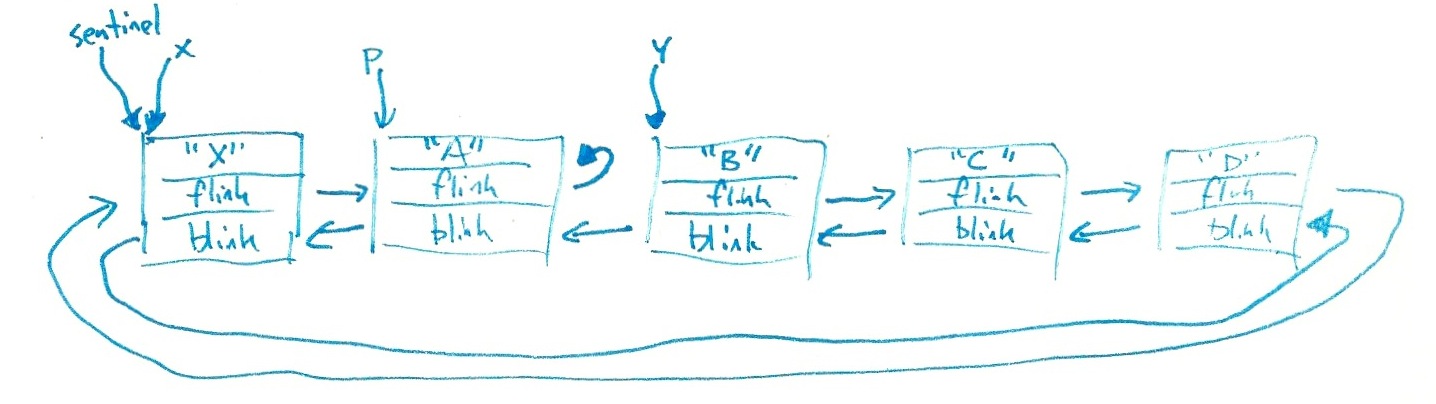
At the point of the first cout call, here is the state of the linked list:
So:
- The first line is "B".
- The second line is "C".
- The third line is "D".
The next two statements put the string "X" into the sentinel, and then corrupt p->flink
so that it points to x->flink = p:
So:
- p->flink equals p, so the fourth line is "A".
- y->blink also equals p, so the fifth line is "A".
- y->blink->blink is the sentinel, so the fifth line is "X".
Part B: At the end of main(), the destructor is called on b.
That's where the seg fault occurs. Specifially, the destructor tries to call delete
on every node in the list, but when it gets to p, it follows p->flink and
ends up deleting p twice. On a good day, that's a seg fault.
Some of you said stuff like "you can't access the sentinel because it's protected."
That's a true statement in that my code cannot say "b.sentinel." However, if my code
is passed a pointer to the sentinel (like p->blink),
then my code is free to use it.
Grading
- Line 1: 2 points for B, 0.5 for A or C.
- Line 2: 2 points for C, 0.5 for B or D.
- Line 3: 2 points for D, 0.5 for C or empty string.
- Line 4: 2 points for A, 0.5 for X.
- Line 5: 2 points for A, 0.5 for X.
- Line 6: 2 points for X, 0.5 for A or D.
- 2 points for saying that the seg fault happens in the destructor.
- 2 points for saying that it's because p->flink is pointing to itself.
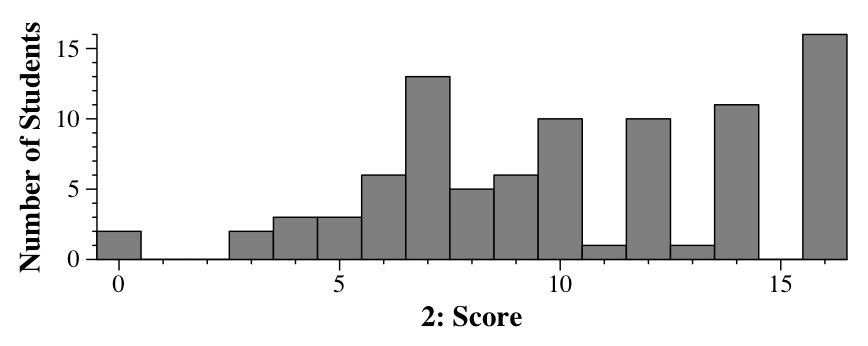
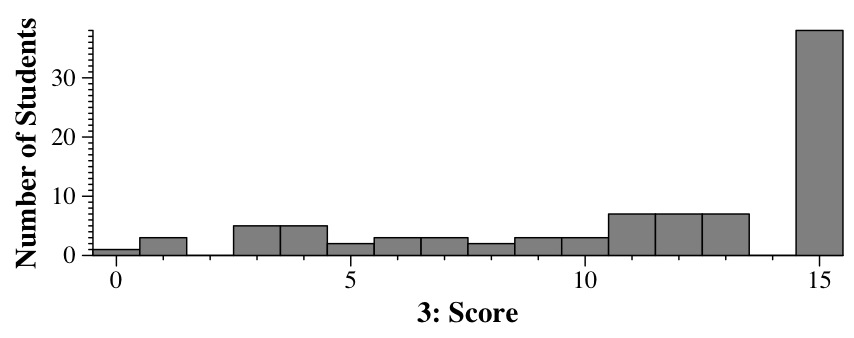
Question 3 - AVL Trees - 15 points
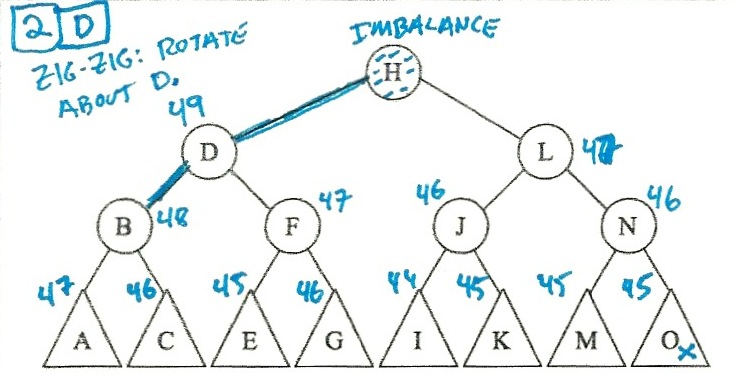
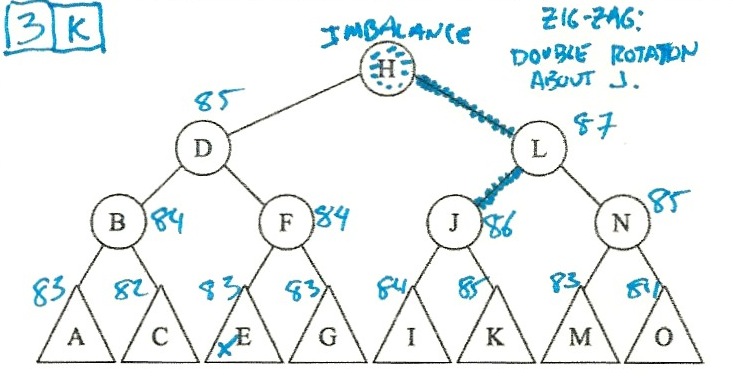
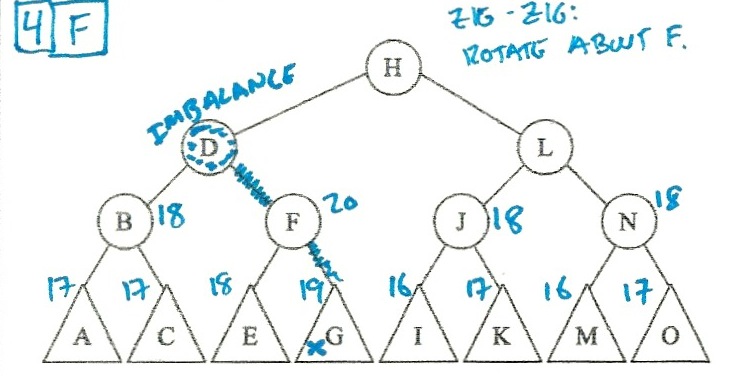
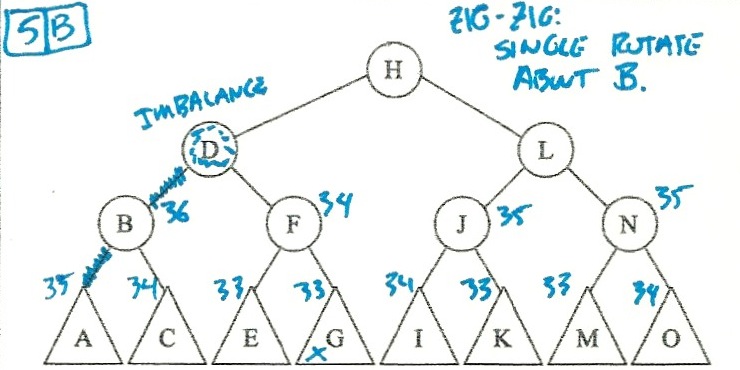
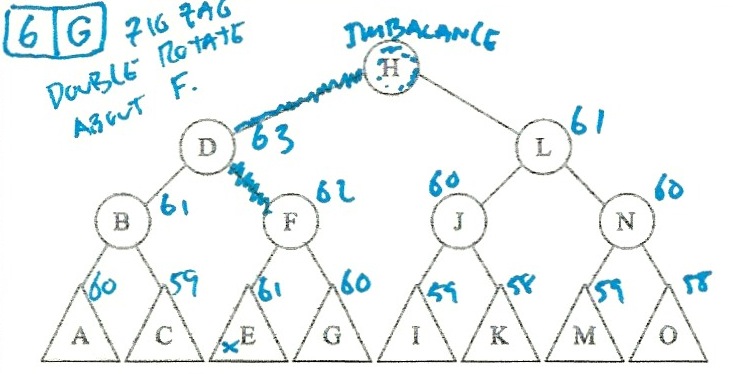
I solved these by putting the heights in the triangles, and then calculating the
heights of the higher nodes. When I spotted an imbalance, I figured out whether
the imbalance was a zig-zig or a zig-zag, and then did the right rotations:
So:
- Scenario 2 is d (Single rotate about D).
- Scenario 3 is k (Double rotate about J).
- Scenario 4 is f (Single rotate about F).
- Scenario 5 is b (Single rotate about B).
- Scenario 6 is g (Double rotate about F).
Grading
3 points per scenario.
Once again, I was liberal with extra credit:
- Scenario 2: One point for b, c, f, g, e.
- Scenario 3: One point for j, l, n, o.
- Scenario 4: One point for g, d.
- Scenario 5: One point for c, d, f, g.
- Scenario 6: One point for f, d.
Question 4 - Code Analysis - 16 points
The key here is to figure out the big-O complexity of the procedure, and then scale
the time accordingly. The study material for this was the Big-O lecture notes,
the recursion lecture notes,
plus the myriad times in class that we explored how the running time of programs
scaled when we doubled the size of input, or increased it by a factor of ten.
One sanity check for yourselves: if I'm doubling n, and there's
a loop that goes from 0 to n-1, then unless there's something really
crazy, the running time of the program is going to increase by at least a
factor of two. There was nothing crazy here, so the answers of 10 and 11 seconds
couldn't apply to any of the programs.
- Implementation 1:
This is going to be linear in n, so doubling n doubles the time: 20 seconds.
- Implementation 2:
Since v is a set, the insert call throws out duplicates. For that reason, the
set never gets bigger than 10 elements. Each insertion is O(1), and the procedure
will be linear: 20 seconds.
- Implementation 3:
Now we're using a multiset, which keeps duplicates. This means that the multiset grows to
be n elements, which means that Q4 is O(n log n). Now, 22 seconds is a good
guess for that, but you can make it precise:
If n log(n) = 10, then 2n log(2n) = 2n (log(n) + 1) = 2(n log(n)) + 2 = 22.
- Implementation 4:
Straightforward linear: 20 seconds.
- Implementation 5:
As we've seen many times in class, this is O(n2), so doubling the size of input
will increase the running time by 4: 40 seconds.
- Implementation 6:
This one is O(n2) + O(n log n). The quadratic term dominates, so this one is
really O(n2), and the answer is again 40 seconds. You may be tempted to
throw in four seconds for the O(n log n) term, but that is technically incorrect
(you can work out the math).
- Implementation 7: Linear recursion: 20 seconds.
- Implementation 8: Exponential recursion -- when you add one to n, it
doubles the running time. How to figure this out? Try it on four example values of
n: 1, 2, 3 and 4. Q4(n) is going to be called 3, 7, 15 and 31 times in these
four cases. Clearly it doubles when you add 1 to n, so doubling n is going
to make the running time skyrocket. The answer is "over 60 seconds."
Grading
- Implementation 1 2 points for 20, 1.5 for 22.
- Implementation 2 2 points for 20, 1.5 for 22.
- Implementation 3 2 points for 22, 1.5 for 20, 0.5 for 40.
- Implementation 4 2 points for 20, 1.5 for 22.
- Implementation 5 2 points for 40, 1.5 for 44, 0.5 for 22.
- Implementation 6 2 points for 40 or 44.
- Implementation 7 2 points for 20, 1.5 for 22.
- Implementation 8 2 points for > 60.
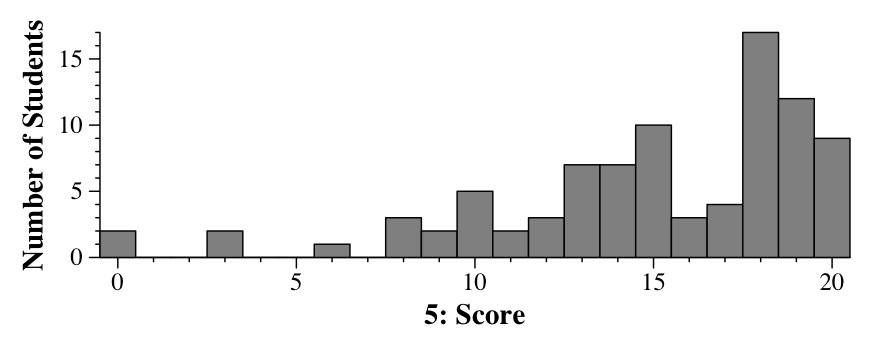
Question 5 - Sets and Maps - 15 points
I'll let you inhabit my perspective, and read a hand-written answer (mine - click on it to
blow it up):
This is the proper way to solve this problem -- use a map, whose key is the last name, and
whose val is a set of first names. It can be a pointer to a set (in fact, that's better, I
think, than my answer above). When you're done creating the map, then you traverse it and
maintain the last-name with the greatest set size. If you encounter a last-name whose
set size is equal to the greatest, ignore it, because the last name is lexicographically
greater than the current "best" one. When you're done, print out all the first names
that correspond to the last name.
There were some common solutions that y'all gave that were not the way to solve
the problem. I've grouped them into three categories:
STRING/INT MAPS: Quite a few of you tried a structure like the following:
- Maintain a map of last names (keys) and counts of first names (val).
- Maintain a set of first names, which are unique.
- Maybe reset this set whenever you have discovered a new last name with maximal count.
- When you're done, print out the names in the set.
This approach does not work, because you have to keep the association of certain first names
with certain last names. Consider the following example:
{ "John Smith", "John Doe", "Binky Taylor", "Kathy Doe" }
The approach above will do the following:
- "John Smith": Map = { [Smith,1] }, Set = { John }
- "John Doe": Map = { [Doe,1],[Smith,1] }, Set = { John }
- "Binky Taylor": Map = { [Doe,1],[Smith,1][Taylor,1] }, Set = { Binky,John }
- "Kathy Doe": Map = { [Doe,2],[Smith,1][Taylor,1] }, Set = ?
At this point, I don't know what you're going to do with the set to make it right.
The problem is that you've lost the association of first and last names.
STRING/STRING MAPS: Quite a few of you tried a map whose keys are last names and
whose vals are first names. That won't work, because it only holds one first name per last
name. Some of you added a map keyed on first name with vals as last names. That won't work
for the same reason.
MULTIMAPS: Some of you tried to insert last-name/first-name pairs into multimaps,
and then to cull duplicates while traversing the multimaps. That approach can work, but
you need to be super-careful traversing the multimap. I was not leanient on grading this
approach, because the extra care required to make it work is the
reason why it is a poor approach.
Grading
- Five points for the first part.
- Eight points for code structure. The STRING/INT MAPS and STRING/STRING MAPS
approaches got 3 points max, and often less because the code would become really
convoluted. I took off for MULTIMAPS depending on how convoluted (and incorrect) the
subsequent code was.
- Two points for reading input correctly.
- Two points for printing output correctly.
- Three points for the mechanics of sets and maps.