Remote Visualization
Remote visualization enables users to access visualization data stored at remote and dispersed locations without making complete local replicas. Delivering visualization to remote sites has been a long standing goal of research and development, especially in situations where the data cannot or has been chosen to stay on the hosting site.
A primary performance measure of remote visualization is the latency incurred during user interaction. The absolute latency is measured from the time a user request is generated, e.g. choosing a new view angle or a new iso-value, until the request is fulfilled. Reducing the latency is a challenging problem in remote visualization.
Latency hiding techniques are the primary methods for addressing this problem. In a nutshell, they aim to trade temporary visual quality for a steadily low response time, for instance, by intelligently using approximations of the requested data while the data is still being transmitted. In this case, user-perceived latency can be greatly reduced with the same absolute latency.
Reducing the absolute latency in remote visualization, if addressed properly, would invariably improve the overall quality of the user's experience. When latency hiding methods are not employed, then the incurred latency directly impacts the rate of client-side user interaction. With latency hiding techniques, a lower absolute latency would require fewer approximations, leading to better visual quality and accuracy during a visualization session.
A general strategy to reduce absolute latency is to prefetch data and use caching, similar to the use of processor and web caches. The caching mechanisms needed by remote visualization, however, are unique in several important ways.
- Remote visualization caches are commonly designed to provide low latency interactivity to one or just a few active users.
- Remote visualization is data intensive, and hence needs caches to adapt to changing network bandwidth and user request rates, etc.
- Exacerbating the problem is a need to manage data fetches of highly varying sizes indexed by many variables.
- It has become popular to use multiple networked nodes for dispersed tasks and this greatly complicates the problem.
- The problem space has no linear structures to leverage.
Other methods include: (1) reducing the amount of data needed per request to a minimum using methods based on view-dependence, level-of-detail, and compression, and by (2) integrating the latest graphics hardware into remote visualization systems, or the latest networking protocols into the system.
Here the distinction is to check whether a method is reducing the absolute latency or the user perceived latency. These are two necessary steps that are not mutually exclusive. The cutting edge practice is to recognize this distinction and use different techniques that accelerate each different aspect. This is unlike before. Nevertheless, let's still take a look at some of the most noteworthy methods proposed by pioneers in this field.
A short survey of previous methods
There two common research perspectives: an algorithmic one and an architectural one.
Most existing latency hiding methods took the algorithmic approach, mainly by designing on alternative representations of a visualization. For instance, texture mapped geometry meshes can be used to faithfully approximate volume rendered results under a small range of viewing angles. Using such approximations of the requested data while the data is still being transmitted, user-perceived latency could sometimes be negligible. But if a user moves outside the targeted range too soon, user-perceived visual quality would then severely suffer. Indeed, latency-hiding as an algorithmic approach introduces a tradeoff between user-perceived visual quality and user-perceived latency.
General architectural aspects of remote visualization are also important venues of research. Researchers have explored using advanced networking protocols, scalable infrastructure of distributed computing systems, etc.
Somewhat related to this subject are methods used in distributed virtual reality and networked games. There, datasets are replicated on all participating computers. The network is not the bottleneck due to minimal runtime communication (transmitting only control messages and highly compressed video streams). Of course during installation, the software needs to test the configuration alternatives to optimize resource utilization on each individual PC.
A general caching model
All modern remote visualization algorithms heavily depend on using caching and prefetching, and in some cases multiple stages of caching. As shown in [Sisneros 2007], getting a good configuration vs. getting a bad configuration would lead to significant performance differences, often two orders of magnitude or more. Traditionally, caching parameters have been manually chosen or twiddled from experience. Given dynamically varying network bandwidth that is available at runtime to an application and, particularly for remote vis, the dynamically changing rates of user requests, such manual settings are not likely to guarantee efficiency.
In our study [Sisneros 2007], we first implemented three common remote visualization algorithms (geometry streaming for volume visualization, image streaming and streamline-streaming for flow visualization) under a common multi-level caching architecture. Through this common architecture, we then systematically evaluated caching performance by experimenting with different cache(s) settings in search of a "optimal" one. Of course we cannot guarantee finding global minimum and usually do find only local minima. The overall process is repeated for each instance of particular interest. In the following, (a) shows the overall theoretical model and (b) shows a common instance in practice.

Using experimental results as the benchmark, we found that a purely simulation based method, built upon running a light weight optimization scheme, that can systematically search for configurations that render the same level of performance improvement as real-world experiments. The input to the optimization algorithm are:
- Measured network bandwidth for a variety of message sizes
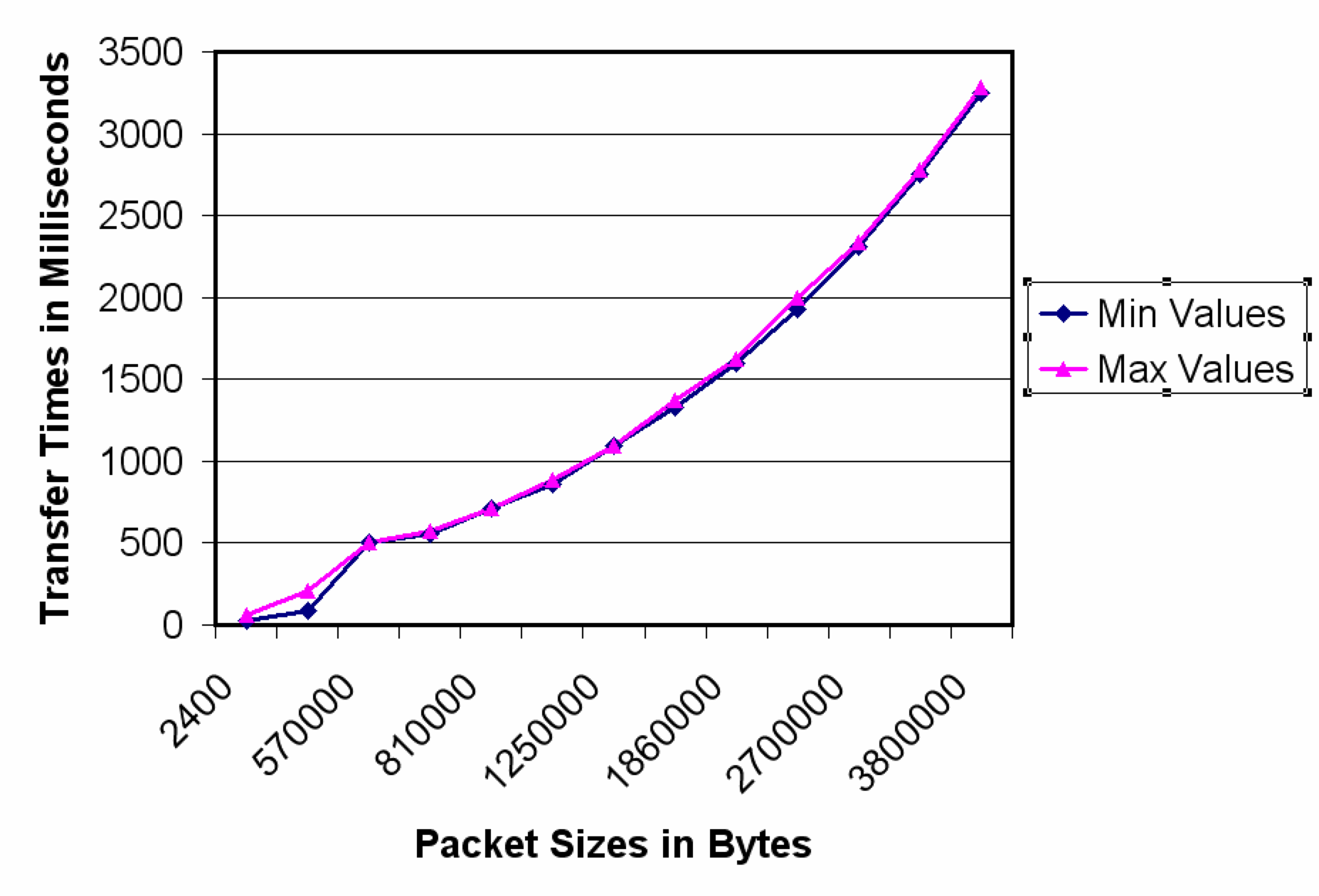
- Rate of user requests
- Range of payload (number of bytes) for users request
No cache uses associative rules for cache line assignment. Treat each cache as a database of limited size. The optimization procedure controsl cache size, percentage of deletion (a miss occurring when cache is full) and size of prefetch. Please note, the optimization for caching configuration does not achieve a performance that is impossible before. All it does is that it can guarantee a good configuration, instead of just a "guessed" one. The following shows a results from a real experiment demonstrating the importance of NOT making a bad choice.
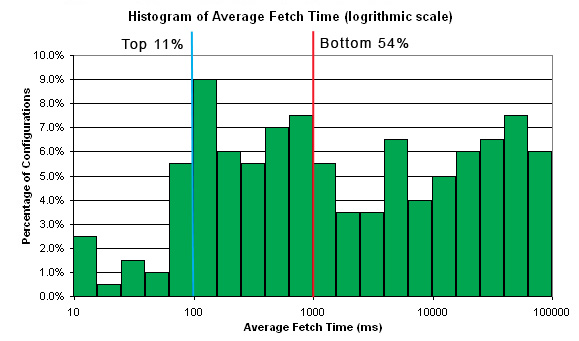
Optimization Process
We took the procedural approach of numerical minimization. Two alternative algorithms were used: (i) the gradient based Steepest Descent and (ii) Conjugate Gradient, both of which are general methods commonly used. While Steepest Descent is the most straightforward method of numerical minimization, Conjugate Gradient is more theoretically sophisticated and, with more assumptions, might lead to better results. Between the two methods, one does not always outperform the other. It is of particular value to use both methods at run time and return the best configuration for more robustness.
Our testing framework considered four network layouts. Remote streaming models containing a client, a server, and L1 and L2 caches, are the most practical. The standard components of any remote system, a server and a client, represent the end layers. The server acts as the compute layer, which is responsible for the storage and access to the visualization datasets that have been computed prior to streaming. The middle layers consist of L1 and L2 caches to join the server and client. In all tests, we use the standard Internet as the wide-area network.
- Layout 1 distributes L1 on the same ethernet LAN as the client and L2 on the same LAN as the server, but not on the same machine. In this layout, L2 cache prefetches subsets of the dataset to hold in memory and handles network transmission on the slower remote connection. The sever itself can devote more time to other visualization tasks.
- Layout 2 places L1 cache on the client machine and L2 cache on the same ethernet LAN as the client. If the wide-area connection is sufficiently fast or the user input rate is sufficiently slow, this layout can locally pre-stage a significant portion of the dataset for the client with large prefetches, as done in [Ding03].
- Layout 3 is similar to Layout 1, with a wireless network replacing the ethernet LAN for the client.
- Layout 4 is similar to Layout 2, with a wireless network replacing the ethernet LAN for the client.
Suppose the number of indexes in a dataset is m, with each index in the compound key being Key_j. We assume that a user would modify any given compound key in consecutive steps by issuing a new request with each modification. To mimic an average user, we assume a user will take one step of unit size in a randomly chosen direction, j. Specifically, our random step generator begins with an initial Key and randomly picks one of the m indices, Key_j to modify by a unit step (increment or decrement with an equal probability).
Using such a procedural user model, we can conveniently control the user behavior by setting a different rate of user input. Between experiments we can use the same random sequence of user requests to measure differences in fetch time in a controlled manner.
If there is a parameter, such as time, which the user is more likely to change than the other parameters, such as view angles, then we can succinctly model this behavior by changing the probability that each Key_j would be chosen for next move. As another example, if a user engages in browsing a hierarchically organized data at a low level-of-detail (LoD), user requests can be generated with a fixed LoD index, while all other indices are freely varied.
The caching system treats all requests the same. It is the minimization code that discovers, over a sequence of user inputs, that an index like time should incur larger prefetch (high prefetch size) or an indiex such as LoD should have a Pinc value of 0, for different applications, respectively. In such a way, specific requirements of different applications are handled transparently in an implicit manner.
Testing Applications
All of our tests assume that the visualization results to be streamed across the network have been pre-computed off-line. This is reasonable for study under the scope of this paper, because the time to compute an incremental on the fly could be treated as a part of the general network latency. The same inCache model can be invariably applied. The overall model of a sequential set of caches still applies. Our testing includes four testing applications, chosen to reflect incremental updates of a constant size vs. varying sizes, small sizes vs. large sizes, and different types of compound keys.
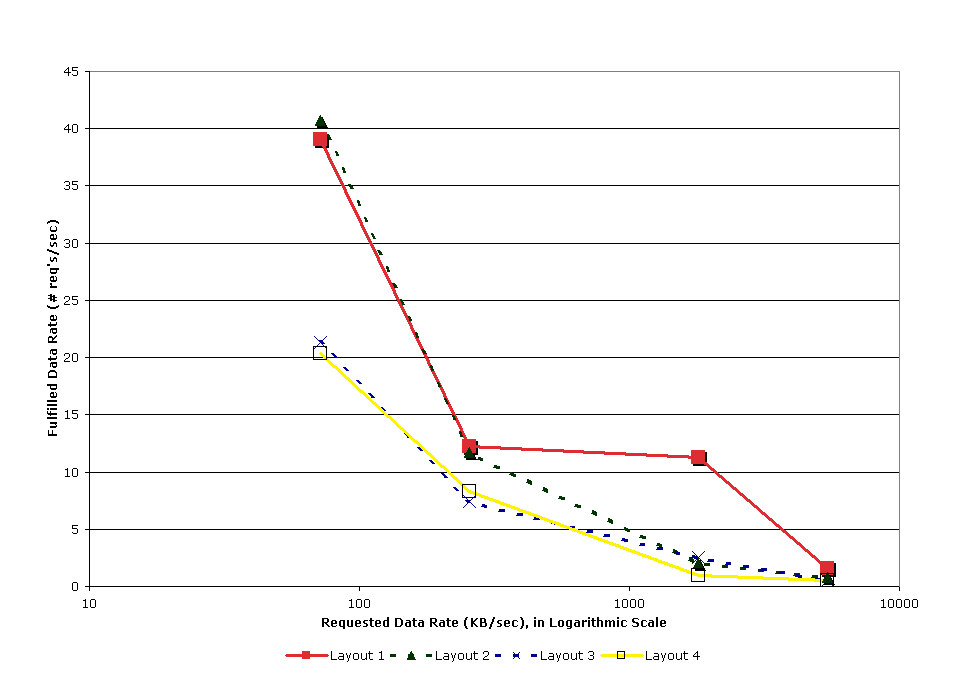
- Application 1 streams a set of streamlines of an equal number of vertices, computed from the well-known tornado dataset. There are 46^3 separate streamlines, with each being 2.4 KB in size, indexed by the coordinate of the seed of each streamline. The client request rate is 30 requests/second. Requested data is 72KB/sec.
- Application 2 involves a database of volume rendered images of a 30 time-step simulation data. The images are 512 x 512 in resolution, indexed by time step and two spherical coordinates (72 x 60) describing the view angel. With Z-lib compression, image sizes average at 85KB, ranging from 70KB to 110KB. The simulated client makes 3 requests/second. Requested data is 255KB/sec.
- Applications 3 and 4 deal with a set of iso-surfaces extracted at 11 different iso-values, from a 99 time-step volume dataset. After loss-less compression using Z-lib, the sizes of the compressed meshes are very different, ranging between 0.5MB and 3.8MB. Application 3 and 4 are tested at 1 request/second and 3 requests/second, respectively. User varies the time index over iso-value with a 2-to-1 probability. Requested data are 1.8MB/sec and 5.4MB/sec.
Now let's look at the optimization process. How well did it work?
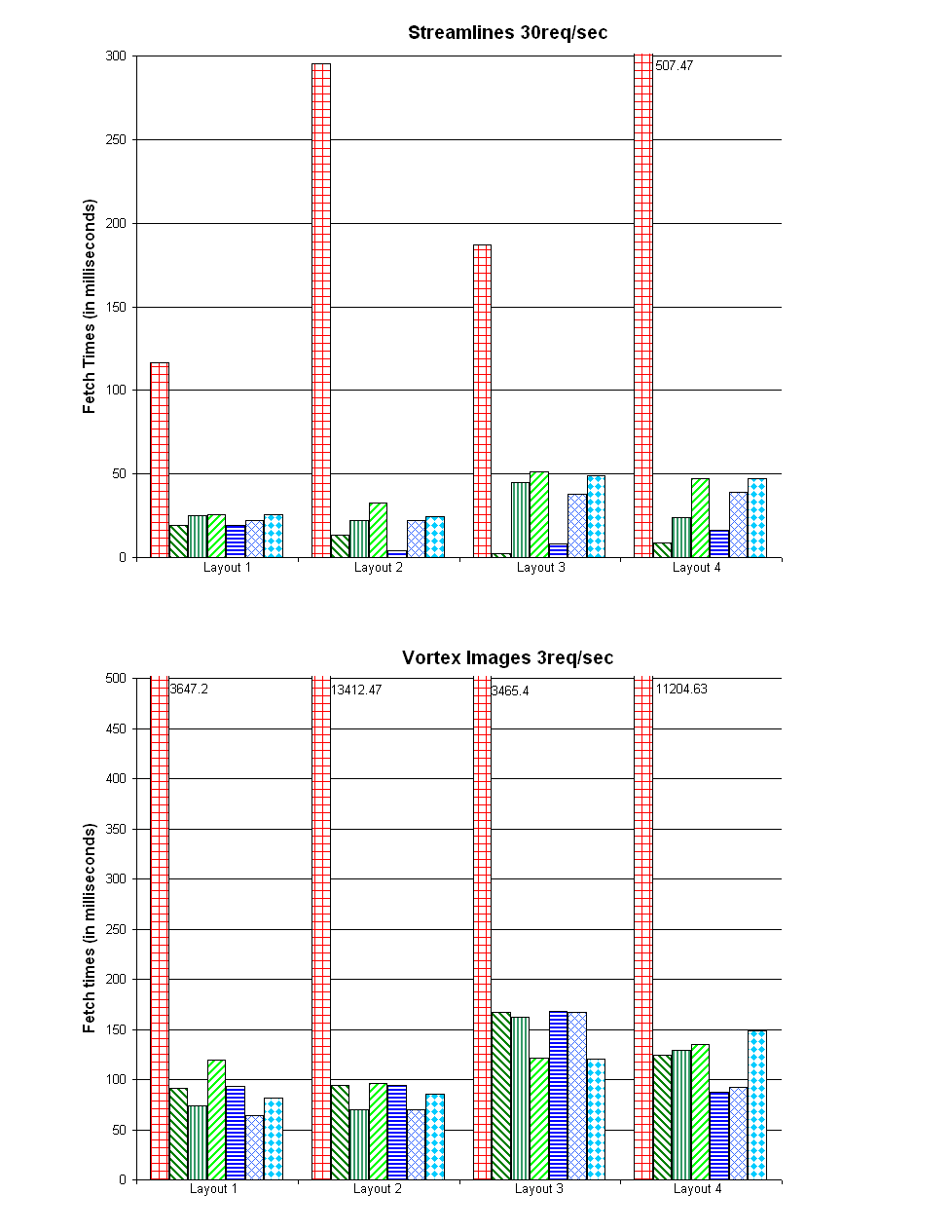
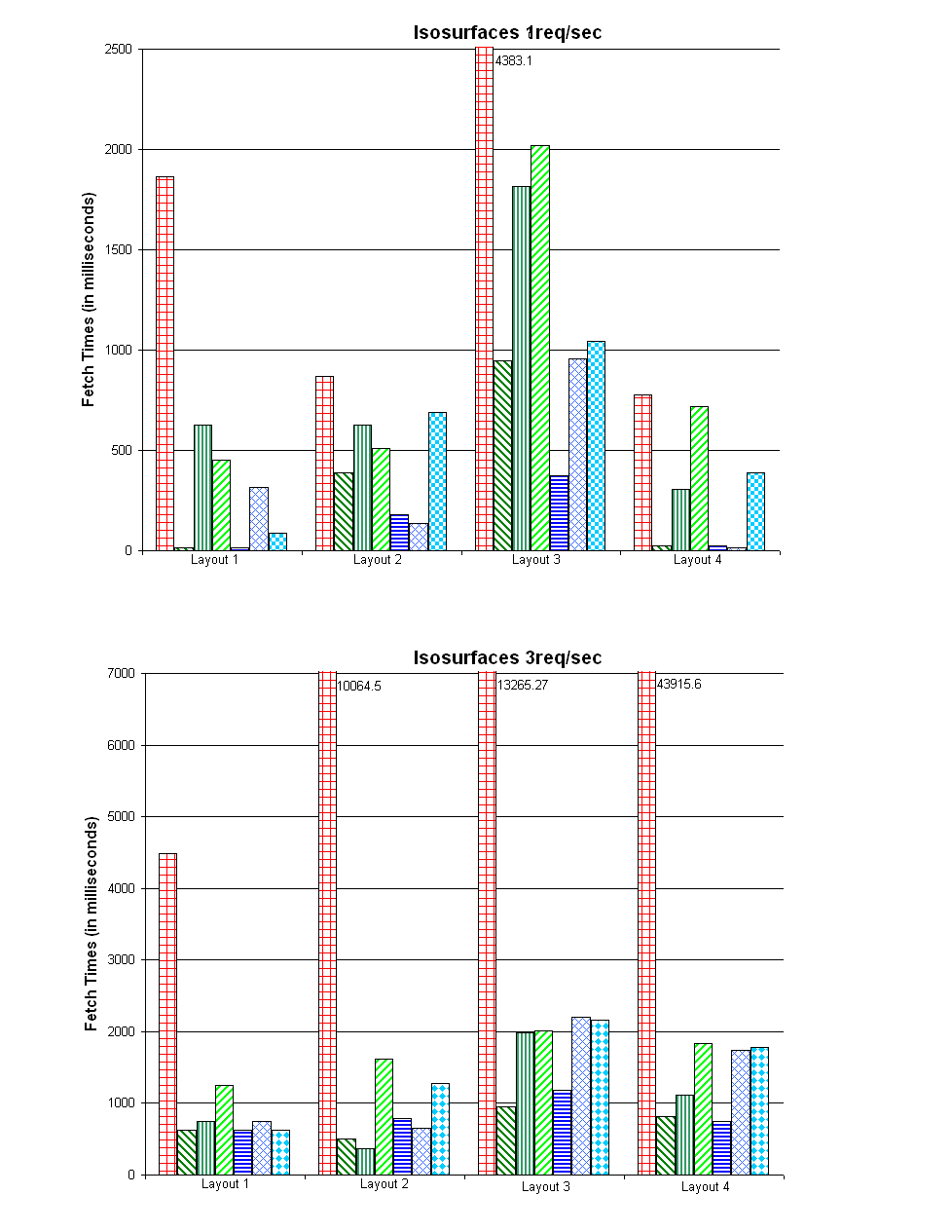
The keys are:

What about the actual performances? Here it is. For detailed explanation, please consult our paper [Sisneros 2007].
Lessons Learned
User request rate is probably more important than previously anticipated. Due considerations must be given to the targeted user request rates to design algorithms and systems with real world applicability.
If, when prefetch is costly (comparatively speaking), the user does not leave sufficient time between requests to allow for prefetch, prefetch could quickly become a burden. For instance, in Application 1, at 30 requests/second the optimized cache configurations use minimal cache prefetching, even when each incremental is of a mere 2.4 KB. With Application 2, a lower request rate (3 requests/second) is used. Transferring an incremental across the WAN takes about 0.1 second. A medium Pinc value of four for each of the two indices would cause 64 incrementals to be prefetched together. Then, prefetch becomes a "post-fetch" and wastes network bandwidth.
Similarly, unless slow data request rates are used, the system benefits less from prefetching across the WAN than across a LAN (i.e. high vs. low prefetch costs). Often the L2 cache, when close to the server node, can take advantage of some prefetching to improve L1 misses. Such behavior is consistently reproducible in both experiment and simulation. This finding justifies the superiority of latency hiding algorithms. By separating user interaction rates from data request rates, a slower rate of data request is possible and leads to better performance.
Applications 3 and 4 serve as latency hiding examples. When surface mesh is requested at 3 requests/second (Application 4), high fetch times are shown to occur. Since mesh rendering is fully interactive by itself, we slow to 1 request/second in Application 3. Fetch times were reduced dramatically because the cache was able to utilize the "idle time" for more prefetch on both L1 and L2. In contrast, the optimizer used very small prefetch in Application 4 to compensate for the higher request rate.
Discussion
Our results can be interpreted in the following ways.
- After getting a targeted design specification for a remote visualization system, we can run a simulation based on real measured network bandwidth and expected range of user requested data sizes and request rates. This simulation can tell us whether the design goal is highly achievable, marginally achievable or just impractical. This is without actually building the system, thus saving resources and valuable programmer time. Given the targeted infrastructure, an operations manager can easily using this approach to evaluate different remote visualization alternatives.
- The optimization approach is ideally to be closely coupled with remote visualization packages. But this is not a hard requirement. Because as long as the range of sizes of user requests and the range of user request rates can be measured, a simulation can be run independently to obtain good cache settings. Then an operations manager can manually change the setting. Probably not using THE optimal setting, because network conditions vary from hour to hour. But the manager can choose a setting that works for most normal conditions for a certain period of the day.
- If the optimization code can have a direct coupling with a remote visualization package, then it would be possible to optimize multi-level caches on a short interval, because the optimization itself often completes with sub-second efficiency.