 |
All of this works with make, so that if you grab this directory using the Git repo on bitbucket, or you scp it from the lab machines, you should be able to type "make clean; make", and everything will be compiled for you. In your sorting lab, you will implement the procedure in two different ways, which will result in two more sorting executables.
#include <vector> void sort_doubles(std::vector <double> &v, bool print); |
The file src/sort_driver.cpp contains a main() routine that lets you perform a variety of sorting examples. It is called with five command line arguments:
size iterations seed double-check(yes|no) print(yes|no) |
This will run iterations tests where it sorts a randomly created vector of size size by calling sort_doubles(). It will use the given seed as a seed for srand48(). The elements of the vector will be floating point numbers between 0 and 10 (i.e. we multiply drand48() by 10). If double-check is "yes", then it will double check the results of sort_doubles() to make sure that it sorted correctly. The last command line argument specifies whether to set the print parameter to true or false.
In this lecture (and your next lab), we will implement a large host of sorting algorithms and link them in with obj/sort_driver.o so that we can test their correctness and speed.
The first such implementation is src/null_sort.cpp, which does nothing except print out the vector if print is true:
#include <iostream>
#include <vector>
#include "sorting.hpp"
using namespace std;
void sort_doubles(vector <double> &v, bool print)
{
size_t j;
if (print) {
for (j = 0; j < v.size(); j++) printf("%4.2lf ", v[j]);
cout << endl;
}
return;
}
|
As such, it does not run correctly. For example, if we double-check it on a three-element vector, it will fail:
UNIX> bin/null_sort 3 1 0 yes no V is unsorted at element 1 0 1.70828036 1 7.49901980 2 0.96371656 UNIX>Although it doesn't sort properly, src/null_sort.cpp is useful because we can use it as a base case for timing other sorting algorithms.
Bubble sort works with the following inner loop:
2 4 3 1Then, when you perform an iteration of bubble sort, you'll skip over the value 2, but you'll swap 3 and 4. Next, you'll be looking at 4 again, and it's greater than 1, so you'll swap them. Since 4 is now at the last element, you're done. The vector is now:
2 3 1 4You'll note that after an iteration, the largest element will always be at the last index. That's good, because if you want to do another iteration, you don't have to worry about that last element -- it's already where it belongs.
You'll also note that whenever an element moves to a smaller index, it can only do that once per iteration. Thus, if the smallest value starts at the highest index, you'll have do do n-1 iterations to get it to the beginning. Such is bubble sort. You iterate n-1 times, and at each iteration, you perform the "inner loop" above. Each time you perform it, you can skip an additional element at the end of the vector, because the previous iteration has already placed that element where it belongs. Here's src/bubble_sort.cpp, without the code to print the vector, and without the headers:
void sort_doubles(vector <double> &v, bool print)
{
int i, j, n;
double tmp;
// The vector is printed here, but I've omitted the code.
n = v.size();
for (i = 0; i < n-1; i++) {
/* This is the inner loop. Each time you perform it, you can stop
one step closer to the beginning of the vector, because the previous
iteration has placed the element where it belongs. */
for (j = 0; j < n-i-1; j++) {
if (v[j] > v[j+1]) {
tmp = v[j];
v[j] = v[j+1];
v[j+1] = tmp;
}
}
// The vector is printed here, but I've omitted the code.
}
}
|
I'm going to run it on seed 14, and an 8-element vector. You'll see that we need all 7 iterations to get the smallest element from the right side to the left side. I'm also coloring this one so that you see the elements that are inspected in each loop.
| UNIX> bin/bubble_sort 8 1 14 yes yes
Before the loop: | 3.62 6.14 4.35 3.88 4.12 8.09 6.28 0.72
i = 0 | 3.62 4.35 3.88 4.12 6.14 6.28 0.72 8.09
i = 1 | 3.62 3.88 4.12 4.35 6.14 0.72 6.28 8.09
i = 2 | 3.62 3.88 4.12 4.35 0.72 6.14 6.28 8.09
i = 3 | 3.62 3.88 4.12 0.72 4.35 6.14 6.28 8.09
i = 4 | 3.62 3.88 0.72 4.12 4.35 6.14 6.28 8.09
i = 5 | 3.62 0.72 3.88 4.12 4.35 6.14 6.28 8.09
i = 6 | 0.72 3.62 3.88 4.12 4.35 6.14 6.28 8.09
| UNIX>
|
If you count the number of elements that are inspected over the course of the algorithm, that is:
That is equal to n(n-1)/2 - 1, which is clearly O(n2). For that reason, bubble sort is a really slow algorithm (we can always sort in O(n log(n)) time, which is much faster). And for that reason, we never use bubble sort.
Selection sort is pretty straightforward:
Before looking at any code, let's look at the output to make sure we know what's going on:
| UNIX> bin/selection_sort 8 1 13 yes yes
Before the loop: | 4.91 9.10 6.96 9.22 4.24 5.93 1.32 4.50
i = 0 | 1.32 9.10 6.96 9.22 4.24 5.93 4.91 4.50
i = 1 | 1.32 4.24 6.96 9.22 9.10 5.93 4.91 4.50
i = 2 | 1.32 4.24 4.50 9.22 9.10 5.93 4.91 6.96
i = 3 | 1.32 4.24 4.50 4.91 9.10 5.93 9.22 6.96
i = 4 | 1.32 4.24 4.50 4.91 5.93 9.10 9.22 6.96
i = 5 | 1.32 4.24 4.50 4.91 5.93 6.96 9.22 9.10
i = 6 | 1.32 4.24 4.50 4.91 5.93 6.96 9.10 9.22
| UNIX>
|
What you see above is that in iteration i, we find the smallest value from indices i to the end of the vector, and then we swap that value with the value in index i. Those values are the ones in light blue. The values in yellow are those that are checked in that iteration. The number of colored elements are exactly the same as in bubble sort, which means that selection sort is O(n2) as well. Typically, it is faster than bubble sort, because it involves fewer swaps.
Here's the code (in selection_sort.cpp):
void sort_doubles(vector <double> &v, bool print)
{
int i, j, k, n;
double tmp;
int minindex;
n = v.size();
/* Optionally print the vector before sorting */
if (print) {
for (k = 0; k < n; k++) printf("%4.2lf ", v[k]);
cout << endl;
}
/* Outer loop. At each of these iterations, we
are going to find the smallest element from
index i to the end, and swap it with the
element in index i. */
|
for (i = 0; i < n-1; i++) {
/* Put the index of the smallest element
starting at index i in minindex. */
minindex = i;
for (j = i+1; j < n; j++) {
if (v[j] < v[minindex]) {
minindex = j;
}
}
/* Now swap v[minindex] with v[i] */
tmp = v[i];
v[i] = v[minindex];
v[minindex] = tmp;
/* Optionally print the vector. */
if (print) {
for (k = 0; k < n; k++) printf("%4.2lf ", v[k]);
cout << endl;
}
}
}
|
Although it as a useless algorithm in computer science, selection sort is the best way to sort a hand of cards. I explain in this video from 2020: https://www.youtube.com/watch?v=I5v77ITleSw.
Plus in this video, also from 2020, Mrs. Dr. Plank sorts an entire deck of cards in just 76 seconds, with a combination of bucket and selection sort. (That's faster than I could do it): https://youtu.be/pzT8_iQ8vkQ.
| UNIX> bin/insertion_1_sort 8 1 4 yes yes
Before the loop. The first element is sorted. | 6.54 5.68 0.50 7.33 5.30 6.50 6.74 8.55
Iteration 0: The first 2 elements are sorted. | 5.68 6.54 0.50 7.33 5.30 6.50 6.74 8.55
Iteration 1: The first 3 elements are sorted. | 0.50 5.68 6.54 7.33 5.30 6.50 6.74 8.55
Iteration 2: The first 4 elements are sorted. | 0.50 5.68 6.54 7.33 5.30 6.50 6.74 8.55
Iteration 3: The first 5 elements are sorted. | 0.50 5.30 5.68 6.54 7.33 6.50 6.74 8.55
Iteration 4: The first 6 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 7.33 6.74 8.55
Iteration 5: The first 7 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 6.74 7.33 8.55
Iteration 6: All 8 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 6.74 7.33 8.55
| UNIX>
|
Now, think about how to implement this. At iteration i, the first i+1 elements are already sorted. The only element out of place is element i+2. For example, in the output above, when iteration 0 starts, the first element (6.54) is already sorted, and the element that is out of place is 5.68. Similarly, when iteration 1 starts, the first two elements (5.68 6.54) are already sorted, and the element that is out of place is 0.50.
So, our inner loop of insertion sort is going to look at the one element that is out place, and then put it in its proper place. To do so, it will insert it into its proper place, but it will have to move all of the elements greater than it over one, so that it can make room. Let's annotate the output on seed 4 a little more. What I'll do is show the element that is inserted in blue, and the elements that have to be "moved over" in yellow:
| UNIX> bin/insertion_1_sort 8 1 4 yes yes
Before the loop. The first element is sorted. | 6.54 5.68 0.50 7.33 5.30 6.50 6.74 8.55
Iteration 0: The first 2 elements are sorted. | 5.68 6.54 0.50 7.33 5.30 6.50 6.74 8.55
Iteration 1: The first 3 elements are sorted. | 0.50 5.68 6.54 7.33 5.30 6.50 6.74 8.55
Iteration 2: The first 4 elements are sorted. | 0.50 5.68 6.54 7.33 5.30 6.50 6.74 8.55
Iteration 3: The first 5 elements are sorted. | 0.50 5.30 5.68 6.54 7.33 6.50 6.74 8.55
Iteration 4: The first 6 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 7.33 6.74 8.55
Iteration 5: The first 7 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 6.74 7.33 8.55
Iteration 6: All 8 elements are sorted. | 0.50 5.30 5.68 6.50 6.54 6.74 7.33 8.55
| UNIX>
|
What makes insertion sort different than selection and bubble sort is that the number of operations that insertion sort takes in each inner loop is dependent on the element to be "inserted," and how many elements have to move to accomodate it. In the worst case, that element will go to the beginning of the vector, which will make insertion sort's running time be just like selection and bubble sort. In the "average" case, the element will have to go into the middle of the elements that precede it, which is still O(n2). But what makes insertion sort interesting is what happens when the element to be inserted is close to where it belongs. Then, insertion sort is much faster.
Before we think about that any more, let's look at implementations. I have three implementations that vary in their details. The first is src/insertion_1_sort.cpp, which I'll include in its entirety. Note, it works pretty much straight from the definition of insertion sort -- assume you have a sorted list of size i-1 and look at the ith element. Start at the right-hand side of the sorted list, and as long as the ith element is less than that element, swap the two. When you're done, the element will be in its proper place, and you have a sorted list of size i.
#include <iostream>
#include <vector>
#include "sorting.hpp"
using namespace std;
void sort_doubles(vector <double> &v, bool print)
{
size_t i, j;
double tmp;
/* Optionally print the vector */
if (print) {
for (j = 0; j < v.size(); j++) printf("%.2lf ", v[j]);
cout << endl;
}
for (i = 1; i < v.size(); i++) {
|
/* Inner loop -- while element i is out of place,
swap it with the element in front of it. */
for (j = i; j >= 1 && v[j] < v[j-1]; j--) {
tmp = v[j-1];
v[j-1] = v[j];
v[j] = tmp;
}
/* Optionally print the vector */
if (print) {
for (j = 0; j < v.size(); j++) printf("%.2lf ", v[j]);
cout << endl;
}
}
}
|
Let's reconsider what makes insertion sort an interesting algorithm: When the input is already sorted, or "nearly" sorted, then it sorts in linear time rather than quadratic. That's because at each iteration, the element to be inserted is "close" to where it belongs. To see this, I've implemented a second driver program called src/sort_sorted.cpp which generates "nearly" sorted input and sorts it. Instead of simply inserting random numbers between 0 and 10, this program inserts i*0.1+drand48() into index i. This means that the vector contains the numbers from 0 to roughly v.size()/10.0, where each number is within 10 vector slots of its final sorted position. Let's look at an example with 20 elements:
UNIX> bin/insertion_1_sorted 20 1 0 no yes | head -n 1 0.17 0.85 0.30 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 UNIX>Think about the element in index zero. Its value will be randomly distributed between 0 and 1. The element in index one will be randomly distributed between 0.1 and 1.1. And so on -- element zero has to be less than element 10, so you know that element zero is within 10 slots of its final resting place. Now, let's take a look at insertion sort sorting this "nearly" sorted vector:
UNIX> bin/insertion_1_sorted 20 1 0 no yes 0.17 0.85 0.30 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.85 0.30 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 1.17 0.98 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.17 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.17 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.17 1.29 1.29 1.07 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.67 1.65 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.65 1.67 1.45 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.65 1.67 1.45 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.65 1.67 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.65 1.67 1.93 1.56 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.93 1.79 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.45 2.28 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.28 2.45 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 2.28 2.28 2.45 2.52 1.98 0.17 0.30 0.85 0.98 1.07 1.17 1.29 1.29 1.45 1.45 1.56 1.65 1.67 1.79 1.93 1.98 2.28 2.28 2.45 2.52 UNIX> |
Because each element is "near" where it should be, insertion sort takes very few operations.
To explore it further -- take a look at sorting 50,000 random elements, and 50,000 "nearly" sorted elements with insertion sort (all timings in this writeup are done on a Dell Linux workstation in 2009):
UNIX> time bin/insertion_1_sort 50000 1 0 no no 3.768u 0.000s 0:03.76 100.0% 0+0k 0+0io 0pf+0w UNIX> time bin/insertion_1_sorted 50000 1 0 no no 0.004u 0.008s 0:00.00 0.0% 0+0k 32+0io 0pf+0w UNIX>
The "user time" is the first word printed -- 3.768 seconds for unsorted input as opposed to 0.004 seconds for sorted input. The difference is stunning!
We can speed up our first implementation of insertion sort if we observe that the implementation above performs too much data movement. Think about the following output:
UNIX> bin/insertion_1_sort 6 1 1 no yes 0.42 4.54 8.35 3.36 5.65 0.02 0.42 4.54 8.35 3.36 5.65 0.02 0.42 4.54 8.35 3.36 5.65 0.02 0.42 3.36 4.54 8.35 5.65 0.02 0.42 3.36 4.54 5.65 8.35 0.02 0.02 0.42 3.36 4.54 5.65 8.35 UNIX> |
Specifically, look at the two highlighted lines. When we perform the insertion of 0.02, think about what happens:
for (i = 1; i < v.size(); i++) {
tmp = v[i];
/* While v[j-1] is greater than v[i], move v[j-1] over one. */
for (j = i; j >= 1 && tmp < v[j-1]; j--) {
v[j] = v[j-1];
}
/* And put v[i] into its proper place. */
v[j] = tmp;
}
|
Note how it is faster than insertion_1_sort:
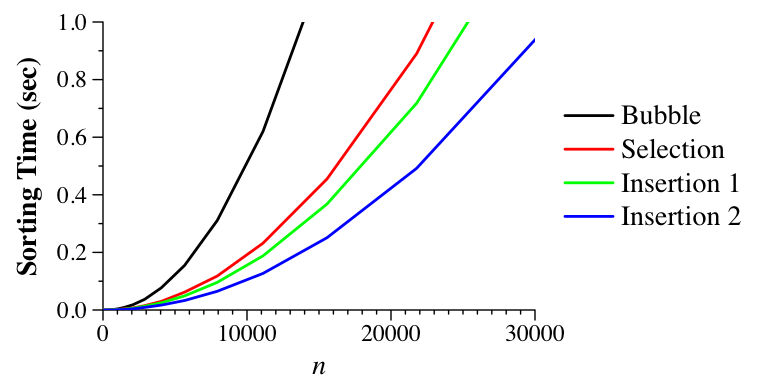
UNIX> time bin/insertion_1_sort 50000 1 0 no no 3.792u 0.000s 0:03.80 99.7% 0+0k 0+0io 0pf+0w UNIX> time bin/insertion_2_sort 50000 1 0 no no 2.584u 0.012s 0:02.59 100.0% 0+0k 32+0io 0pf+0w UNIX>Let's compare sorting algorithms graphically. To do so, I've written a shell script called scripts/do_timing.sh that varies the number of elements and times the given sorting program as it runs ten iterations. It uses the wall-clock time of the program (again on my Linux box in 2009). I have results of timing all the programs in this lecture in the file txt/all_timings.txt. Below, we graph the algorithms that we have seen so far:
|
So, insertion sort is the fastest (interestingly, this can vary from machine to machine. On my Mac in 2009, selection sort was fastest).
If you look at the inner loop of insertion_2_sort, there is one place where it can be improved: it is always checking to make sure that j >= 1. We can fix this by sentinelizing: we traverse the vector before sorting and swap the minimum element in index 0. This is done in src/insertion_3_sort.cpp -- here's the relevant part:
/* Swap the minimum element into element 0 */
minindex = 0;
for (i = 1; i < v.size(); i++) if (v[i] < v[minindex]) minindex = i;
tmp = v[0];
v[0] = v[minindex];
v[minindex] = tmp;
/* Now, I can remove the "(j >= 1)" check in the inner loop: */
for (i = 1; i < v.size(); i++) {
tmp = v[i];
for (j = i; tmp < v[j-1]; j--) v[j] = v[j-1];
v[j] = tmp;
}
|
This improves matters, but not to a great degree (again, this varies from machine to machine).
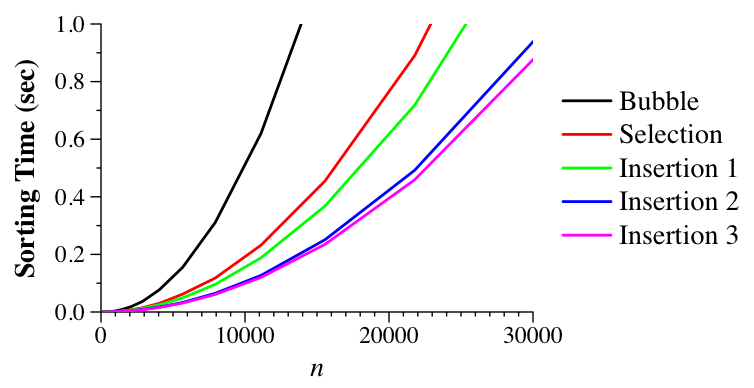 |
void sort_doubles(vector <double> &v, bool print)
{
multiset <double> s;
size_t i;
multiset <double>::iterator sit;
for (i = 0; i < v.size(); i++) s.insert(v[i]);
i = 0;
for (sit = s.begin(); sit != s.end(); sit++) {
v[i] = *sit;
i++;
}
if (print) {
for (i = 0; i < v.size(); i++) printf("%4.2lf ", v[i]);
cout << endl;
}
}
|
As you can see below, this blows away the other algorithms in performance. This is because the others are O(n2) algorithms, and STL's sets are implemented with a balanced binary tree structure (e.g. AVL or Red-Black trees), which results in O(n log(n)) sorting:
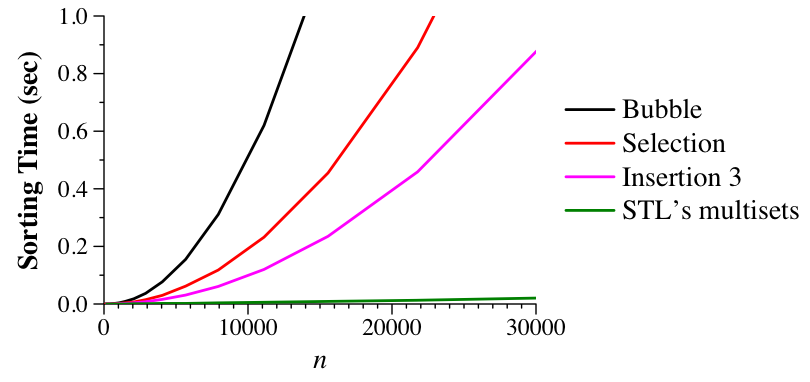 |
Using multisets, however, is overkill, since they contain a lot of structure (internal nodes, pointers, etc), which takes time and memory to keep updated after every insert() call. There are algorithms that sort in O(n log(n)) time without the extra overhead. One of these is used in the sort routine implemented with STL algorithms. We include that in src/stl_sort.cpp
void sort_doubles(vector <double> &v, bool print)
{
size_t j;
sort(v.begin(), v.end());
if (print) {
for (j = 0; j < v.size(); j++) printf("%4.2lf ", v[j]);
cout << endl;
}
}
|
The graph below shows how it destroys the others (note the X-axis has been greatly expanded to sort up to one million elements).
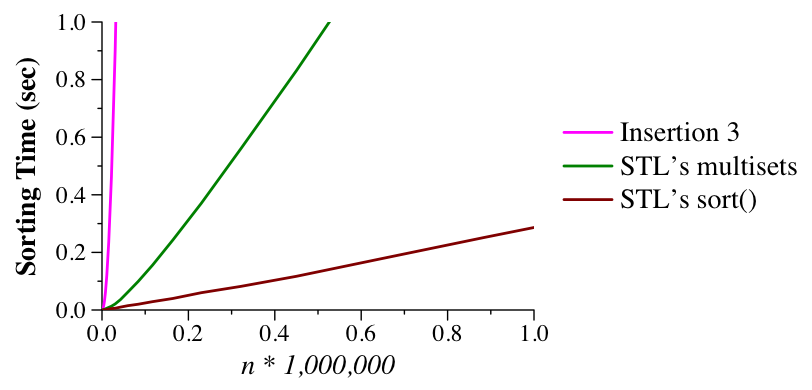 |
The reason is that the STL's sort() routine is a very carefully tuned O(n log(n)) algorithm (I'd guess quicksort). We'll explore these algorithms below.
The first is src/heap_sort.cpp. This uses the priority queue implementation from the priority queue lecture notes (although, I modified the print routine so it would match these lecture notes). When you use the "print" option, it prints the vector and the priority queue at every step. In the example below, I color the part of the vector that is sorted at every step. As you can see, the root of the heap in the previous step (yellow) becomes the next element of the vector. I draw the sorted vector in light red.
| UNIX> bin/heap_sort 8 1 0 no yes |
vector | 1.71 7.50 0.96 8.70 5.77 7.86 6.92 3.69 0.96 3.69 1.71 7.50 5.77 7.86 6.92 8.70 | heap
| 0.96 7.50 0.96 8.70 5.77 7.86 6.92 3.69 1.71 3.69 6.92 7.50 5.77 7.86 8.70 |
| 0.96 1.71 0.96 8.70 5.77 7.86 6.92 3.69 3.69 5.77 6.92 7.50 8.70 7.86 |
| 0.96 1.71 3.69 8.70 5.77 7.86 6.92 3.69 5.77 7.50 6.92 7.86 8.70 |
| 0.96 1.71 3.69 5.77 5.77 7.86 6.92 3.69 6.92 7.50 8.70 7.86 |
| 0.96 1.71 3.69 5.77 6.92 7.86 6.92 3.69 7.50 7.86 8.70 |
| 0.96 1.71 3.69 5.77 6.92 7.50 6.92 3.69 7.86 8.70 |
| 0.96 1.71 3.69 5.77 6.92 7.50 7.86 3.69 8.70 |
| 0.96 1.71 3.69 5.77 6.92 7.50 7.86 8.70 |
| UNIX> |
|
The second is src/heap_fast_sort.cpp. One inefficiency with using the priority queue data structure is that you make a copy of the vector. This program rips the functionality out of the priority queue program and puts it directly into the sorting procedure. That way, it doesn't require a second vector. It first turns the vector into a heap whose root is the maximum rather than the minimum element. It does this using the linear time heap construction method. Then, it removes the root and puts it at the end of the vector, then calls percolate down on the remaining v.size()-1 elements. It continues doing this until the heap is gone, and the vector is sorted.
In this program, when the print option is specified, it prints out the vector after turning it into a heap, and then at every step of removing the root of the heap. In the example below, I color the heap yellow and the sorted vector light red:
| UNIX> bin/heap_fast_sort 8 1 0 no yes |
heap, but | 8.70 7.50 7.86 3.69 5.77 0.96 6.92 1.71 | the vector is filled
storing max | 7.86 7.50 6.92 3.69 5.77 0.96 1.71 8.70 | in from right to left
values rather | 7.50 5.77 6.92 3.69 1.71 0.96 7.86 8.70 | with the maximum element
than min | 6.92 5.77 0.96 3.69 1.71 7.50 7.86 8.70 | popped off the heap.
values: | 5.77 3.69 0.96 1.71 6.92 7.50 7.86 8.70 |
| 3.69 1.71 0.96 5.77 6.92 7.50 7.86 8.70 |
| 1.71 0.96 3.69 5.77 6.92 7.50 7.86 8.70 |
| 0.96 1.71 3.69 5.77 6.92 7.50 7.86 8.70 |
| UNIX>
|
In terms of timing, this is faster than using multisets, and you can see that the "fast" version is faster, although just a little:
 |
Merge sort works with an ingenious recursion, which I outline as follows:
8.70 7.50 7.86 3.69 9.22 0.96 6.92 1.71The first thing that we do is split this into two 4-element vectors. I'm coloring one light red and one light blue:
Part 1 Part 2 8.70 7.50 7.86 3.69 9.22 0.96 6.92 1.71Now, we sort the vectors recursively. I know that's a leap of faith, but that's how recursion works. When we're done, here's what they look like:
Part 1 Part 2 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22Now, we want to merge them together into one sorted vector. One thing we know -- the first element of the sorted vector will be either the first element of the light red vector, or the first element of the light blue vector. It will be the smaller of the two -- in this case, 0.96. So, we copy that value to our final vector, and concentrate on the second value from the light blue vector:
Part 1 Part 2 Final Vector 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22 0.96Now, we're comparing 3.69 from the red vector, and 1.71 from the blue vector -- we copy the smallest of these, 1.71, to the final vector, and concentrate on the next value in the blue vector:
Part 1 Part 2 Final Vector 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22 0.96 1.71Next, we compare 3.69 from the red vector, and 6.92 from the blue vector -- again, we copy the smallest of these, 3.69, to the final vector, and concentrate on the next value in the red vector:
Part 1 Part 2 Final Vector 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22 0.96 1.71 3.69By now, I think you see how it progresses -- Here are the last five steps:
Part 1 Part 2 Final Vector 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22 0.96 1.71 3.69 6.92 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22 0.96 1.71 3.69 6.92 7.50 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22 0.96 1.71 3.69 6.92 7.50 7.86 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22 0.96 1.71 3.69 6.92 7.50 7.86 8.70 3.69 7.50 7.86 8.70 0.96 1.71 6.92 9.22 0.96 1.71 3.69 6.92 7.50 7.86 8.70 9.22As it turns out, merging is a linear operation -- O(n) in the size of the vector. We'll talk about the overall running time of merge sort later. For now, let's think about implementation. Here's what I suggest you use as your recursive call:
| void recursive_sort(vector <double> &v, vector <double> &temp, int start, int size, int print); |
The original vector is v, and temp is a temporary vector. Both are the same size. Recursive_sort() will only sort the elements from start to start+size. If size is equal to 1, then it simply returns. If size equals 2, then it sorts the elements directly. Otherwise, It calls recursive_sort() on the first size/2 elements, and on the last size-size/2 elements. When that's done, it merges them into temp, and then copies the elements in temp back to v. It is an unfortunate fact with merge sort that we need a temporary vector.
Let's take a quick look at the output of merge_1_sort. Whenever recursive_sort() is called with a size greater than one, it prints out "B:", start and size (both padded to 5 characters) and the vector. Right before a call to recursive_sort() returns, it does the same thing, only it prints "E" instead of "B". Below is an example of sorting 16 elements. I'm coloring the elements on which each call is focused in light red when recursive_sort() is first called ("B"), and yellow right when recursive_sort() is about to return ("E"):
UNIX> bin/merge_1_sort 16 1 1 yes yes
B: 0 16 0.42 4.54 8.35 3.36 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 0 8 0.42 4.54 8.35 3.36 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 0 4 0.42 4.54 8.35 3.36 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 0 2 0.42 4.54 8.35 3.36 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
E: 0 2 0.42 4.54 8.35 3.36 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 2 2 0.42 4.54 8.35 3.36 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
E: 2 2 0.42 4.54 3.36 8.35 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
E: 0 4 0.42 3.36 4.54 8.35 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 4 4 0.42 3.36 4.54 8.35 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 4 2 0.42 3.36 4.54 8.35 5.65 0.02 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
E: 4 2 0.42 3.36 4.54 8.35 0.02 5.65 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 6 2 0.42 3.36 4.54 8.35 0.02 5.65 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
E: 6 2 0.42 3.36 4.54 8.35 0.02 5.65 1.88 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
E: 4 4 0.42 3.36 4.54 8.35 0.02 1.88 5.65 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
E: 0 8 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 8 8 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 8 4 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
B: 8 2 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 7.50 3.66 3.51 5.73 1.33 0.64 9.51 1.54
E: 8 2 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.66 7.50 3.51 5.73 1.33 0.64 9.51 1.54
B: 10 2 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.66 7.50 3.51 5.73 1.33 0.64 9.51 1.54
E: 10 2 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.66 7.50 3.51 5.73 1.33 0.64 9.51 1.54
E: 8 4 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.51 3.66 5.73 7.50 1.33 0.64 9.51 1.54
B: 12 4 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.51 3.66 5.73 7.50 1.33 0.64 9.51 1.54
B: 12 2 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.51 3.66 5.73 7.50 1.33 0.64 9.51 1.54
E: 12 2 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.51 3.66 5.73 7.50 0.64 1.33 9.51 1.54
B: 14 2 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.51 3.66 5.73 7.50 0.64 1.33 9.51 1.54
E: 14 2 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.51 3.66 5.73 7.50 0.64 1.33 1.54 9.51
E: 12 4 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 3.51 3.66 5.73 7.50 0.64 1.33 1.54 9.51
E: 8 8 0.02 0.42 1.88 3.36 4.54 5.65 8.35 9.90 0.64 1.33 1.54 3.51 3.66 5.73 7.50 9.51
E: 0 16 0.02 0.42 0.64 1.33 1.54 1.88 3.36 3.51 3.66 4.54 5.65 5.73 7.50 8.35 9.51 9.90
0.02 0.42 0.64 1.33 1.54 1.88 3.36 3.51 3.66 4.54 5.65 5.73 7.50 8.35 9.51 9.90
|
Whenever there is an "E" line, you can see that the yellow elements are merged from the previous line. Study this output -- your lab will have to match it.
I've written an awk script in ms.awk to produce the colored output that you see above. Here's another example:
UNIX> bin/merge_1_sort 13 1 100 yes yes | awk -f ~jplank/cs302/Notes/Sorting/ms.awk > msex.html
And here's msex.html. It's not a bad idea to look at this, so that you can see how the recursive calls are made when size is an odd number.
You can view it in a alternative, but similar way -- each number, for example 0.42, is involved in exactly four yellow rectangles, which means exactly four merges. There are 16 numbers, and each is involved in log(16) merges. Hence (n log(n)).
I've also written merge_2_sort.cpp, which is identical to merge_1_sort, except that whenever size is less than 115, it sorts the array with insertion sort. The reason is that for small arrays, insertion sort is faster than merge sort, since it doesn't make recursive calls. Thus, merge_2_sort should be faster than merge_1_sort. (I determined the value of 115 experimentally). Here is merge sort in relation to the other algorithms:
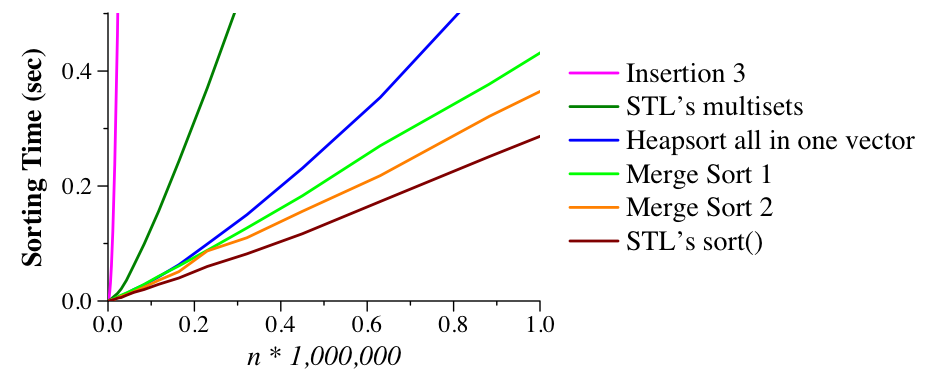 |
|
void recursive_sort(vector <double> &v, int start, int size, int print) |
In all versions of quicksort, I use a slight variant of the "version with in-place partition," (from the Wikipedia notes). We'll start with Quicksort 1, where I simply use the element in v[start] as the pivot. To perform the partition, I set a left pointer at start+1 and a right pointer at start+size-1. While the left pointer is less than the right pointer, I do the following:
When we are done, I swap the pivot in elements v[start] with the last element of the left set. Then I recursively sort the left and right sets, omitting the pivot, since it is already in the correct place.
The output of quick_1_sort is similar to merge_1_sort: I print the vector with an "S" label when I call recursive_sort() with a size greater than 1. If the size is equal to two, I simply sort the vector by hand and return. Otherwise, I partition the vector around the pivot, then print the vector with a "P" label. This statement includes the index of the pivot element. At the end of sorting, I also print out the vector.
Let's look at some example output:
UNIX> bin/quick_1_sort 12 1 82 no yes
S: 0 12 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
P: 0 12 6 3.15 5.26 3.62 0.43 3.46 4.95 5.77 6.09 7.55 6.82 6.69 6.49
S: 0 6 3.15 5.26 3.62 0.43 3.46 4.95 5.77 6.09 7.55 6.82 6.69 6.49
P: 0 6 1 0.43 3.15 3.62 5.26 3.46 4.95 5.77 6.09 7.55 6.82 6.69 6.49
S: 0 1 0.43 3.15 3.62 5.26 3.46 4.95 5.77 6.09 7.55 6.82 6.69 6.49
S: 2 4 0.43 3.15 3.62 5.26 3.46 4.95 5.77 6.09 7.55 6.82 6.69 6.49
P: 2 4 3 0.43 3.15 3.46 3.62 5.26 4.95 5.77 6.09 7.55 6.82 6.69 6.49
S: 2 1 0.43 3.15 3.46 3.62 5.26 4.95 5.77 6.09 7.55 6.82 6.69 6.49
S: 4 2 0.43 3.15 3.46 3.62 5.26 4.95 5.77 6.09 7.55 6.82 6.69 6.49
S: 7 5 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 7.55 6.82 6.69 6.49
P: 7 5 7 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 7.55 6.82 6.69 6.49
S: 7 0 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 7.55 6.82 6.69 6.49
S: 8 4 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 7.55 6.82 6.69 6.49
P: 8 4 11 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 6.49 6.82 6.69 7.55
S: 8 3 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 6.49 6.82 6.69 7.55
P: 8 3 8 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 6.49 6.82 6.69 7.55
S: 8 0 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 6.49 6.82 6.69 7.55
S: 9 2 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 6.49 6.82 6.69 7.55
S: 12 0 0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 6.49 6.69 6.82 7.55
0.43 3.15 3.46 3.62 4.95 5.26 5.77 6.09 6.49 6.69 6.82 7.55
UNIX>
|
I've colored the part of the array under attention red/blue. When the size is greater than two and we are looking at an "S" line, the pivot is at v[start] and is colored blue. When you see a "P" line, the pivot will be at the given index, still colored blue, and recursive calls will be made to the left partition and the right partition. For example, in line one, the pivot is 5.77. The partition moves it to index 6, and then makes recursive calls with start=0,size=6 and start=7,size=5.
You can create your own colored output by piping quick_1_sort to "awk -f ~jplank/cs302/Notes/Sorting/qs1.awk" -- the output is HTML that is colored. Here's a different example than the one above:
UNIX> quick_1_sort 16 1 100 yes yes | awk -f qs1.awk > qs1ex.htmlHere is qs1ex.html.
I am going to give two detailed examples of the partitioning algorithm. In the first, I want to show how the first partition above is done. To remind you, here is the array:
5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62 |
Our pivot is at element zero with a value of 5.77. What we do is have two integer indices, called left and right. Left starts at 1 and right starts at 11. I'm abbreviating left as L and right as R below, and I'm going to show two lines -- the original vector, and what is looks like as it is being partitioned:
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
Pivot L=1 R=11
|
Now, our first step is to increment L until it is pointing to a value ≥ the pivot. I'm going to color the skipped-over value green:
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
Pivot L=2 R=11
|
Next, I'm going to decrement R until it is pointing to a value ≤ the pivot. Since it is already pointing to such a value, I don't decrement it at all. Note, this picture is the same as the previous one:
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
Pivot L=2 R=11
|
We swap the values pointed to by L and R, increment L and decrement R. I'm going to color the elements in the right partition purple.
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 3.62 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 6.49
Pivot L=3 R=10
|
And we repeat. Increment L until it is pointing to a value ≥ the pivot:
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 3.62 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 6.49
Pivot L=4 R=10
|
Decrement R until it is pointing to a value ≤ the pivot:
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 3.62 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 6.49
Pivot L=4 R=7
|
Swap, increment L and decrement R:.
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 3.62 0.43 3.46 4.95 3.15 6.09 7.55 6.82 6.69 6.49
Pivot L=5 R=6
|
Repeat again. Increment L until it is pointing to a value ≥ the pivot:
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 3.62 0.43 3.46 4.95 3.15 6.09 7.55 6.82 6.69 6.49
Pivot R=6 L=7
|
Decrement R until it is pointing to a value ≤ the pivot (it is already doing that, so this picture is identical to the last): :
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 5.77 5.26 3.62 0.43 3.46 4.95 3.15 6.09 7.55 6.82 6.69 6.49
Pivot R=6 L=7
|
Because L is greater than R, we're done. We now swap the pivot with the last element in the left (green) set:
Original: 5.77 5.26 6.49 0.43 6.09 4.95 3.15 3.46 7.55 6.82 6.69 3.62
In Progress: 3.15 5.26 3.62 0.43 3.46 4.95 5.77 6.09 7.55 6.82 6.69 6.49
R=6 L=7
|
And we make two recursive calls:
recursive_sort(v, 0, 6, print); recursive_sort(v, 7, 5, print);As you can see, this matches the first "P" line in the input above. Additionally, you can see the two recursive calls at lines 3 and 10.
Here's a second detailed example of the partitioning algorithm. For this, I'm including a third driver program, called sort_driver_lab.cpp. It is exactly the same as sort_driver.cpp, except when the seed is a multiple of 2000, it creates vectors with a lot of duplicate entries. The makefile in this directory compiles it to quick_1_lab_sort. Let's use an example to illustrate how the partitioning algorithm works when there are a lot of duplicate entries:
UNIX> bin/quick_1_lab_sort 12 1 6000 yes yes
S: 0 12 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
P: 0 12 8 2.93 2.93 7.70 9.85 7.70 2.93 7.70 2.93 9.85 9.85 9.85 9.85
S: 0 8 2.93 2.93 7.70 9.85 7.70 2.93 7.70 2.93 9.85 9.85 9.85 9.85
P: 0 8 2 2.93 2.93 2.93 9.85 7.70 7.70 7.70 2.93 9.85 9.85 9.85 9.85
S: 0 2 2.93 2.93 2.93 9.85 7.70 7.70 7.70 2.93 9.85 9.85 9.85 9.85
S: 3 5 2.93 2.93 2.93 9.85 7.70 7.70 7.70 2.93 9.85 9.85 9.85 9.85
P: 3 5 7 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 3 4 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
P: 3 4 3 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 3 0 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 4 3 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
P: 4 3 5 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 4 1 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 6 1 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 8 0 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 9 3 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
P: 9 3 10 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 9 1 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
S: 11 1 2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
2.93 2.93 2.93 2.93 7.70 7.70 7.70 9.85 9.85 9.85 9.85 9.85
UNIX>
|
As before, I'll walk you through the first partitioning:
Original: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
In Progress: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
Pivot L=1 R=11
|
We increment L until it points to an element ≥ the pivot, and we decrement R until it points to an element ≤ the pivot (it already does):
Original: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
In Progress: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
Pivot L=3 R=11
|
Swap the values (since they are equal, this doesn't do anything), increment L and decrement R:
Original: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
In Progress: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
Pivot L=4 R=10
|
Increment L until it points to an element ≥ the pivot, and decrement R until it points to an element ≤ the pivot (it already does):
Original: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
In Progress: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
Pivot L=5 R=10
|
Swap the values, increment L and decrement R:
Original: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
In Progress: 9.85 2.93 7.70 9.85 7.70 2.93 7.70 2.93 9.85 2.93 9.85 9.85
Pivot L=6 R=9
|
Increment L until it points to an element ≥ the pivot, and decrement R until it points to an element ≤ the pivot (again, it already does):
Original: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
In Progress: 9.85 2.93 7.70 9.85 7.70 2.93 7.70 2.93 9.85 2.93 9.85 9.85
Pivot L=8 R=9
|
Swap the values, increment L and decrement R:
Original: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
In Progress: 9.85 2.93 7.70 9.85 7.70 2.93 7.70 2.93 2.93 9.85 9.85 9.85
Pivot R=8 L=9
|
We're done. Swap the pivot with the last element of the left partition:
Original: 9.85 2.93 7.70 9.85 7.70 9.85 7.70 2.93 9.85 2.93 2.93 9.85
In Progress: 2.93 2.93 7.70 9.85 7.70 2.93 7.70 2.93 9.85 9.85 9.85 9.85
R=8 L=9
|
And make recursive calls:
recursive_sort(v, 0, 8, print); recursive_sort(v, 9, 3, print);PAY ATTENTION TO THIS: There are times when, after incrementing and decrementing, you will have L equal to R. Pay attention to this case, and perform the appropriate action. You can see an example of this with the following call:
UNIX> bin/quick_1_lab_sort 8 1 12000 yes yesIn the first partitioning, you will end up with L = R.
If you want yet another example of partitioning, I have some older notes in old.html.
 |
The circles show the three elements considered for the pivot -- the one with the median value is always chosen. (The indices are calculated as start, (start+size-1) and (start+size/2). Study that output, because you will have to duplicate it in your lab. (qs2.awk formats the output of quick_2_sort if you'd like to study from it).
This makes a minor difference in sorting random lists, but a huge difference in sorting presorted lists:
UNIX> time bin/quick_1_sorted 100000 1 0 no no 5.173u 0.012s 0:05.21 99.4% 0+0k 0+0io 0pf+0w UNIX> time bin/quick_2_sorted 100000 1 0 no no 0.006u 0.003s 0:00.01 0.0% 0+0k 0+0io 0pf+0w UNIX>Quicksort #3 sorts lists of size 46 and smaller with insertion sort. That improves the performance a little:
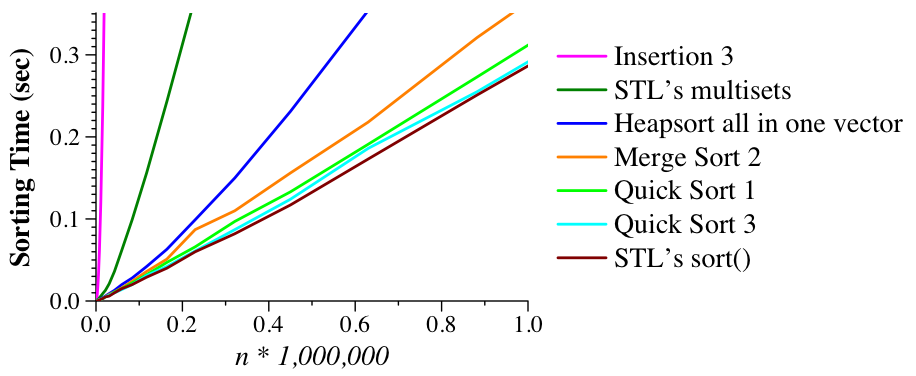 |
If you'd like more help, Katie Schuman (CS302 TA from 2010 to 2014, now an EECS professor) explains quicksort in this youtube video.
0.8 9.7 2.6 8.7 7.0 7.8 4.3 0.4 3.0 5.5 |
Since we know how the numbers have been generated, and we know that there are ten of them, we can approximate where they'll end up when we sort them:
0.8 -- around index 0 9.7 -- around index 9 2.6 -- around index 2 8.7 -- around index 8 7.0 -- around index 7 7.8 -- around index 7 4.3 -- around index 4 0.4 -- around index 0 3.0 -- around index 3 5.5 -- around index 5 |
So, to use Bucket Sort, let's start by putting each element where we think it belongs. If there's already an element there (as with 7.8 and 0.4), we'll find the closest empty element in the array:
Index 0 1 2 3 4 5 6 7 8 9 Start - - - - - - - - - - 0.8 goes to 0 0.8 - - - - - - - - - 9.7 goes to 9 0.8 - - - - - - - - 9.7 2.6 goes to 2 0.8 - 2.6 - - - - - - 9.7 8.7 goes to 8 0.8 - 2.6 - - - - - 8.7 9.7 7.0 goes to 7 0.8 - 2.6 - - - - 7.0 8.7 9.7 7.8 goes to 6 0.8 - 2.6 - - - 7.8 7.0 8.7 9.7 Nearest empty slot 4.3 goes to 4 0.8 - 2.6 - 4.3 - 7.8 7.0 8.7 9.7 0.4 goes to 1 0.8 0.4 2.6 - 4.3 - 7.8 7.0 8.7 9.7 Nearest empty slot 3.0 goes to 3 0.8 0.4 2.6 3.0 4.3 - 7.8 7.0 8.7 9.7 5.5 goes to 5 0.8 0.4 2.6 3.0 4.3 5.5 7.8 7.0 8.7 9.7 |
When we're done, we have a vector that is almost sorted. We can use insertion sort to sort it, and since it's almost sorted, insertion sort will run in linear time. How cool is that!!
A first implemention of using bucket sort in this way is in src/bucket_1_sort.cpp:
/* Headers and insertion sort omitted. */
void sort_doubles(vector <double> &v, bool print)
{
int sz;
int index, j;
double val;
double *v2;
int hind, lind, done, i;
sz = v.size();
/* Allocate a new array, and set every entry to -1. */
v2 = (double *) malloc(sizeof(double)*sz);
for (i = 0; i < sz; i++) v2[i] = -1;
/* For each element, find out where you think it will go.
If that index is empty, put it there. */
for (i = 0; i < sz; i++) {
val = (v[i] * sz/10.0);
index = (int) val;
if (v2[index] == -1) {
v2[index] = v[i];
/* Otherwise, check nearby, above and below, until
you find an empty element. */
|
} else {
hind = index+1;
lind = index-1;
done = 0;
while(!done) {
if (hind < sz && v2[hind] == -1) {
v2[hind] = v[i];
done = 1;
} else {
hind++;
}
if (!done && lind >= 0 && v2[lind] == -1) {
v2[lind] = v[i];
done = 1;
} else {
lind--;
}
}
}
}
/* At the end, copy this new vector back to the
old one, free it, and call insertion sort to
"clean up" the vector. */
for (i = 0; i < sz; i++) v[i] = v2[i];
free(v2);
if (print) {
cout << "Before Insertion Sort\n";
for (j = 0; j < sz; j++) printf("%.2lf ", v[j]);
cout << endl;
}
insertion_sort(v);
if (print) {
cout << "After Insertion Sort\n";
for (j = 0; j < sz; j++) printf("%.2lf ", v[j]);
cout << endl;
}
}
|
What this code does is predict where each value is going to go, and then put it into that index of v2 so long as it's empty (-1). If that entry is not empty, then it looks adjacent to that entry, and continues doing so until it finds an empty slot, and puts it there. Once that process is done, it copies v2 back to v and uses insertion sort to sort v. Since v is nearly sorted (or should be), insertion sort should sort it very quickly.
As it turns out, this process is quite slow, and the reason is that as v2 fills up, it takes longer to find empty slots and they are quite far from where they should be. We fix this in src/bucket_2_sort.cpp where we double the size of v2 so that there are more empty cells and a much smaller chance of having to move to adjacent cells. As you can see, the results are great -- even better than the Standard Template Library!
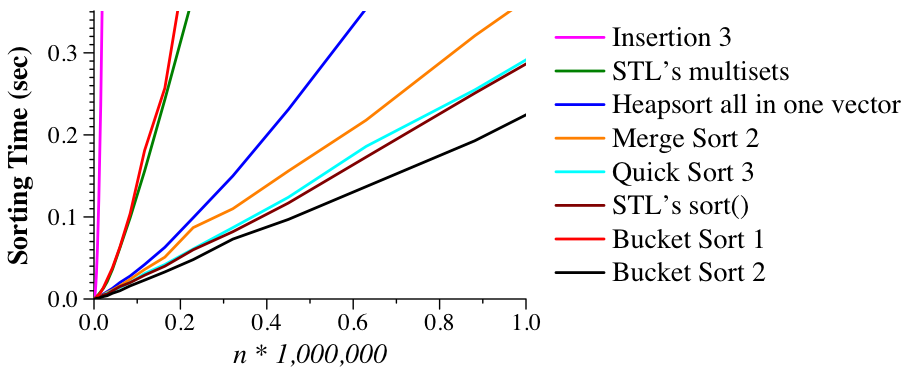 |
As I said in class, if you can characterize the probability distribution, you can use its CDF (Cumulative Distribution Function) to sort any input in this way. Think about it.