CS302 Final Exam - Answers and Grading
James S. Plank - December 9, 2015
Question 1
The procedure halt() takes two parameters.
Program_file is the name of a file containing a C++ program.
Input_file is the name of a file which program_file will read on standard
input. The procedure halt() should take a finite amount of time to complete, and it
should return "infinite loop" if it determines that program_file will go into an infinite loop when it runs
input_file on standard input. It should return "halt" otherwise.
The halting problem states that it is impossible to write halt().
Grading
- 3 points for saying that halt() returns "halt" when program_file halts when
called on input_file.
- 3 points for saying that halt() returns "infinite loop" when program_file goes
into an infinite loop when called on input_file.
- 3 points for saying that halt() has to return an answer in a finite amount of time.
- 3 points for saying that halt() cannot be written.
- It's incorrect to say that halt() runs the program on the input, because that's
not what it does -- it determines what happens when the program is run on the input. I took of
a point on each of the first parts if you only said it ran the program on the input.
Question 2
Parts A-C: Just before the final merge, the first half of the array will be sorted,
as will the second half. Here are the answers:
- Part A: { 1 2 3 3 2 4 4 5 }
- Part B: { 2 3 4 5 1 2 3 4 }
- Part C: { 1 2 3 4 2 3 4 5 }
To perform the partition, we will have two pointers, l and r, which start at
elements 1 and size()-1 respectively. We increment l until it points to a value greater
than or equal to the pivot, and we decrement
r until it points to a value less
than or equal to the pivot. We swap the values, increment l, decrement r and move on.
So:
- Part D: Swap 7 with 1, and 9 with the rightmost zero: { 6 0 3 1 0 4 5 0 9 7 }
- Part E: Swap 8 with the rightmost 4, 7 with 6, and you're done: { 7 4 4 1 4 6 7 9 7 8 }
- Part F: Swap 7 with the rightmost 6, 6 with 4, and 9 with 6: { 6 6 4 5 6 8 9 6 9 7 }
Grading:
2 points per. I gave some partial credit on the quicksort answers, so long as you partitioned the
input correctly, and the pivot was in the beginning.
Question 3
We went over this exact problem in detail in class. It is in the Dynamic Programming lecture notes.
The file
Q3.cpp has an answer and a main(). Here's the answer:
int MS::Maxseq_DP(int a, int b)
{
int rv, rv1, rv2;
if (a == SA.size()) return 0;
if (b == SB.size()) return 0;
if (cache[a][b] != -1) return cache[a][b];
if (SA[a] == SB[b]) {
rv = 1 + Maxseq_DP(a+1, b+1);
} else {
rv1 = Maxseq_DP(a, b+1);
rv2 = Maxseq_DP(a+1, b);
rv = (rv1 > rv2) ? rv1 : rv2;
}
cache[a][b] = rv;
return rv;
}
|
We can verify it on examples from the lecture notes:
UNIX> g++ Q3.cpp
UNIX> echo AbbbcccFyy FxxxyyyAc | a.out
3
UNIX> echo AbbbcccFyy FxxxyyyAccc | a.out
4
UNIX> echo 9009709947053769973735856707811337348914 9404888367379074754510954922399291912221 | a.out
15
UNIX>
Grading
12 points. As usual, if you were close, you started with 12 points and I deducted
for things that were incorrect. If you weren't close, I gave you points according to what
I thought you did right.
Question 4
See relevant lecture notes for this.
- Part A: Breadth-first search: f.
- Part B: Network flow: i (This was your network flow lab).
- Part C: Union/Find on disjoint sets: a
- Part D: Network flow: i
- Part E: Breadth-first search: f.
- Part F: Topological sort: c.
- Part G: Depth-first search: b. You can do it with disjoint
sets, but that would be O(|E|α(|V|)).
- Part H: Dijsktra's shortest path algorithm: h.
Grading
- Part A: 2 points for f. 0.75 for h.
- Part B: 2 points for i.
- Part C: 2 points for a.
- Part D: 2 points for i. 0.5 for b (since you do a DFS after the network flow calculation).
- Part E: 2 points for f. 0.5 for g.
- Part F: 2 points for c. 0.5 for g.
- Part G: 2 points for b. 0.75 for a. 0.5 for f.
- Part H: 2 points for h. 0.5 for g. 0.5 for e.
As always, crowdsourcing scored 100% --
Y'all's answers:
- Part A: 47 of 55 answered f.
- Part B: 27 of 55 answered i. Every other answer was guessed except h.
- Part C: 38 of 55 answered a.
- Part D: 30 of 55 answered i. Other popular answers: b, e and g.
- Part E: 45 of 55 answered f.
- Part F: 41 of 55 answered c. f was the other popular answer.
- Part G: 51 of 55 answered b.
- Part H: 46 of 55 answered h.
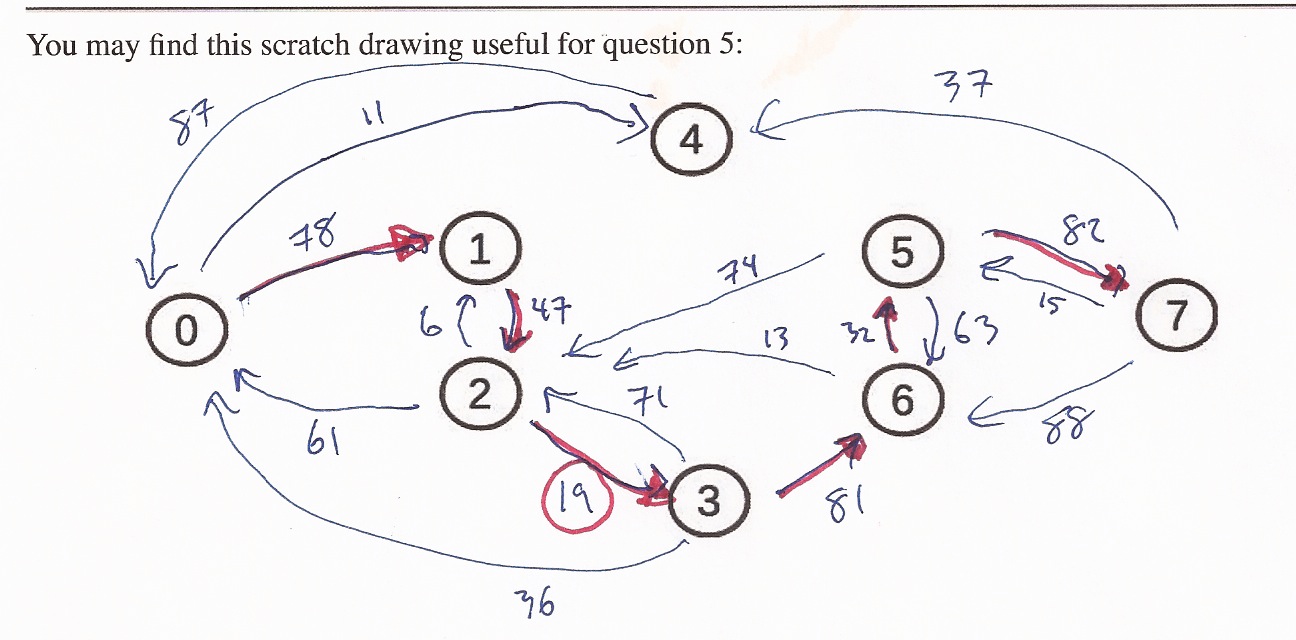
Question 5
Turn the adjacency matrix into a picture. Here's mine, using the
node layout that I gave you on page two of the exam:
Part A: There's only one path from 0 to 7: 0 - 1 - 2 - 3 - 6 - 5 - 7.
Part B: Its flow is 19.
Here is Part C as a plain text table:
Change 0 1 -19
Change 1 2 -19
Remove 2 3
Change 3 6 -19
Change 6 5 -19
Change 5 7 -19
Add 1 0 19
Change 2 1 +19
Change 3 2 +19
Add 6 3 19
Change 5 6 +19
Change 7 5 +19
|
Grading
- The path: 4 points.
- The flow: 4 points (if you gave the wrong path, I gave full credit if you gave the proper
flow for that path).
- 2 points each for removed edges, added added, positively changed edges and negatively
changed edges. This answer had to be with respect to the path you gave.
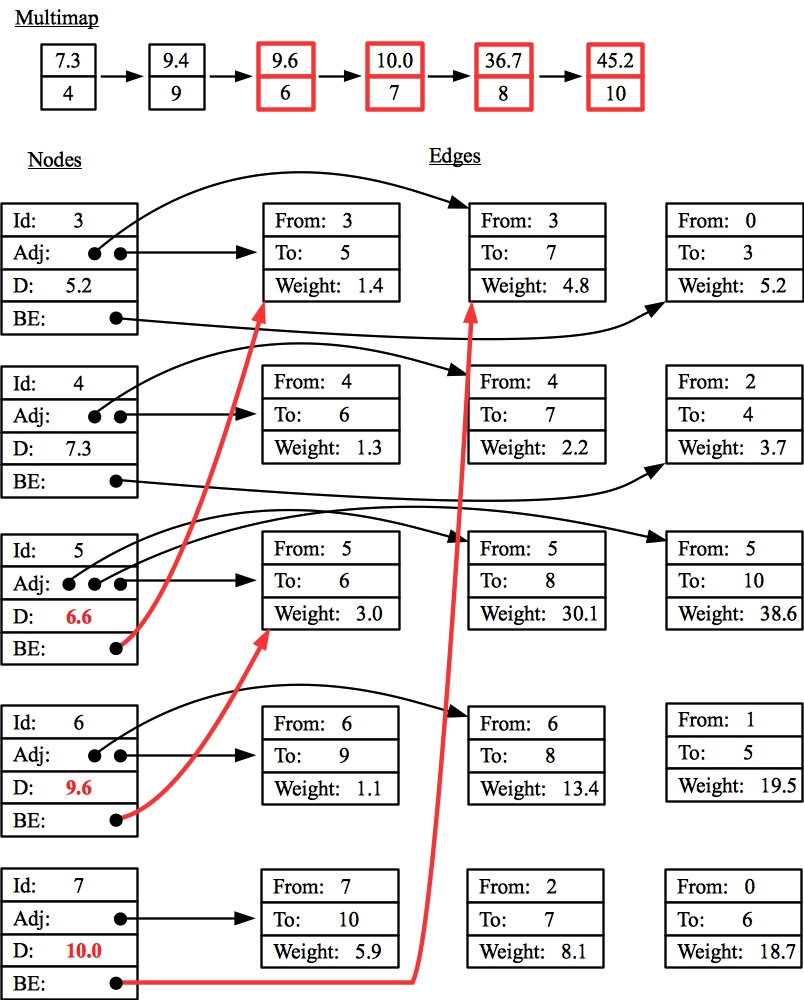
Question 6
Part A: Ptr is there for when you find a shorter path to a node
than the one that is currently recorded on the multimap. When that happens,
you have to delete the node from the multimap and reinsert it with the
new path. The problem is that the entry on the multimap is keyed on distance
and not on the node itself, so you retain a pointer to it in Ptr.
That way, you can find the entry in the multimap in constant time, so that
you may delete it.
Part B
.
The first node that you process is node three:
- You remove it from the multimap.
- Then you traverse its adjacency list.
- The path to node 5 through node three has a length of 6.6, so you
need to update node 5's distance and backedge, delete it from the multimap
and reinsert it with a key of 6.6
- The path to node 7 through node three has a length of 10.0, so you
need to update node 7's distance and backedge, delete it from the multimap
and reinsert it with a key of 10.
The next node on the multimap is now node 5, because its distance (6.6)
is less than node 4's (7.3). So:
- You remove it from the multimap.
- Then you traverse its adjacency list.
- The path to node 6 through node 5 has a length of 9.6, so you
need to update node 6's distance and backedge, delete it from the multimap
and reinsert it with a key of 9.6.
- The path to node 8 through node 5 has a length of 36.7.
Node 8 isn't pictured, so you don't have to update its information.
However, you do have to delete it from the multimap
and reinsert it with a key of 36.7.
- The path to node 10 through node 5 has a length of 45.2.
Again, node 10 isn't pictured, so you don't have to update its information.
However, you do need to add it to the multimap.
Here's the drawing, with anything new/changed in red:
Grading
- Part A: 4 points. You had to mention deletion for two points, and you had
to mention that it is relevant when you change the path for a node to get that last point.
- Part B: 0.5 points each for the weights of nodes 3 and 4, and the backedges for
nodes 3 and 4.
- Part B: 1 point each for the weights of nodes 5, 6, 7, 8 and 10.
- Part B: 1 point each for the backedges of nodes 5, 6, and 7.
- Part B: 1 point each for no hinkiness with the multimap.
- I gave some partial credit here. In particular, if you had your back edges go to nodes,
or you gave me a correct answer for processing node 4 rather than node 5, you received significant
partial credit.