|
|
 |
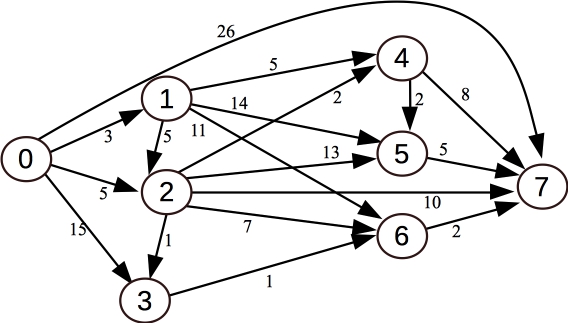 |
However, you can solve the problem just by knowing the adjacency list for node 2, because that is the next node that you will process from the multimap. That node has a shortest distance of 5 from node zero. So, let's process each node on node 2's adjacency list:
 |
(BTW, you don't need to use a deque. You can use a vector so long as you push and pop from the back).
long long Graph::Num_Paths(int from, int to)
{
int i, n, t;
deque <int> zero_inc;
/* Set all paths to zero, except for node <b>from</b>, where there is one. */
for (i = 0; i < Paths.size(); i++) Paths[i] = 0;
Paths[from] = 1;
/* You need a deque of nodes which have zero incident edges.
The only node on this deque when you start is node from. */
zero_inc.push_back(from);
/* Process the list. */
while (!zero_inc.empty()) {
/* Pull the first node off, and delete it */
n = zero_inc[0];
zero_inc.pop_front();
/* If this is to, then we're done -- return the number of paths
to to that is held in the vector Paths. */
if (n == to) return Paths[to];
/* Add the current node's number of paths to each node adjacent to it.
Then "delete" the edge by decrementing that node's indicent edges.
When that value hits zero, pust the node onto the deque. */
for (i = 0; i < Adj[n].size(); i++) {
t = Adj[n][i];
Paths[t] += Paths[n];
Incident[t]--;
if (Incident[t] == 0) zero_inc.push_back(t);
}
}
return Paths[to]; /* This shouldn't happen because all nodes
are reachable from node "from" */
}
|
I've programmed this up in
Graph.cpp, and put a main() that reads the number of
nodes, and then the edges. Nodes are numbered from 0 to the number of nodes minus one.
I've put examples 0 and 3 from the
IncreasingSubsequences problems into the files.
G1.txt and
G2.txt.
I've put a denser graph with 31 nodes into
G3.txt. This program works well on all three files:
It works on the first two files, but it takes 12 seconds on G3.txt, because it's not a true DFS --
it calls Num_Paths() on the same node multiple times, and these calls blow up
exponentially in G3.txt:
If you didn't start off with a working framework, then I simply assigned some points for
code that looked like it would at least compile, or maybe do something reasonable. Let me
give you an example. Here's an answer that is similar to some of yours:
This answer is worth about three points to me. It should compile, but it doesn't make
much sense. There are small problems that I attribute to time pressure and stress.
When I'm grading answers like this one, these small problems
don't mean much to me, and they don't factor into my assignment of points, although
if there are ten of these, then they do factor in.
(And I'll say that they do factor into answers that are more correct. For example, if you
give one of the good answers above, and you don't initialize your variables, I will take off
a point).
The recursion follows my hints -- try each value of s and recursively call Stones(P-s, S). If that returns that the caller loses, then whoever calls Stones(P, S) will win.
If there is no value of s that works, then return that the caller loses.
You have to memoize to make it work fast enough.
Here's my answer, in
Stones.cpp. I've added a main() which reads
the parameters from standard input, so you can test it.
Here we test a few:
UNIX> g++ -o Graph Graph.cpp
UNIX> time ./Graph < G1.txt
4
0.000u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX> time ./Graph < G2.txt
41
0.001u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX> time ./Graph < G3.txt
531372800
0.001u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX>
Other Approaches, Working and Non-Working
Many of you didn't identify this problem as topological sort, and tried other approaches.
I'll address these in turn:
DFS
You can structure this recursively, like a DFS -- call Num_Paths() on each of your
children, and sum the return values. If you call Num_Paths(to, to), then return 1.
I have this solution in
Graph2.cpp. You'll note that it doesn't use Paths
or Incident:
long long Graph::Num_Paths(int from, int to)
{
long long rv;
int i;
if (from == to) return 1;
rv = 0;
for (i = 0; i < Adj[from].size(); i++) {
rv += Num_Paths(Adj[from][i], to);
}
return rv;
}
UNIX> time ./Graph2 < G1.txt
4
0.000u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX> time ./Graph2 < G2.txt
41
0.001u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX> time ./Graph2 < G3.txt
531372800
12.551u 0.008s 0:12.56 99.9% 0+0k 0+0io 0pf+0w
UNIX>
Memoizing the DFS
You can memoize the DFS like it's a dynamic program -- now the running time is linear again
(I'm using Paths as the cache, and setting all entries to -1 at the beginning of the
program). This is in
Graph3.cpp:
long long Graph::Num_Paths(int from, int to)
{
long long rv;
int i;
if (from == to) return 1;
if (Paths[from] != -1) return Paths[from];
rv = 0;
for (i = 0; i < Adj[from].size(); i++) {
rv += Num_Paths(Adj[from][i], to);
}
Paths[from] = rv;
return rv;
}
UNIX> g++ -o Graph3 Graph3.cpp
UNIX> time ./Graph3 < G1.txt
4
0.000u 0.001s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX> time ./Graph3 < G2.txt
41
0.001u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX> time ./Graph3 < G3.txt
531372800
0.001u 0.001s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX>
Using recursion to do the topological sort
This one is harder to get correct, but you can perform the topological sort using
recursion -- when you set a node's Incidence to 0, you call Num_Paths
recursively. This assumes that Paths is initialized to zero for every
node. Compare this solution with the first solution above -- they are quite
similar, but this one doesn't manage a deque or vector explicitly. The other
solution is more straightfoward.
This is in
Graph4.cpp:
long long Graph::Num_Paths(int from, int to)
{
long long rv;
int tn;
int i;
if (from == to) return Paths[from];
rv = 0;
for (i = 0; i < Adj[from].size(); i++) {
tn = Adj[from][i];
Paths[tn] += Paths[from];
Incident[tn]--;
if (Incident[tn] == 0) rv = Num_Paths(tn, to);
}
return rv;
}
UNIX> g++ -o Graph4 Graph4.cpp
UNIX> time ./Graph4 < G1.txt
4
0.000u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX> time ./Graph4 < G2.txt
41
0.000u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX> time ./Graph4 < G3.txt
531372800
0.001u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w
UNIX>
Grading
This was worth 15 points, and you started with 15 if you had one of the correct working
frameworks. After that, you got deductions. For example, if you used the DFS, but didn't
memoize, you lost three points.
long long Graph::Num_Paths(int from, int to)
{
int rv;
int i, j;
vector <int> P;
for (i = 0; i < Adj.size(); i++) {
for (j = 0; j < Adj[i].size(); j++) {
if (Adj[i][j] == to) {
P.push_back(Adj[i][j]);
} else {
Paths[j]++;
}
}
}
for (i = 0; i < P.size(); i++) {
rv += Paths[P[i]];
}
return rv;
}
There are other small mistakes that show a lack of attention to the problem:
And there are much bigger problems that make this seem as though the student is just
putting down code that uses the variables and does something graph-like, but also
make it seem like the student doesn't really understand the problem or the solution:
So, I would assign this 3 out of 15, for doing something graph-like, but nothing that
seems like the student understands the problem or the proper solution. On your exam, I'll
say "Please see the answer." That means that your solution falls into this category.
Question 5
This is very similar to (and much easier than) the PartisanGame topcoder problem
that I assigned in lab. That problem had different vectors for Alice and Bob, and the
constraints were too big that you could simply use dynamic programming for P. Here,
the constraints are much smaller, and you can simply use dynamic programming.
#include <string>
#include <vector>
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;
class Game {
public:
string Stones(int P, vector <int> &S);
vector <string> Cache;
};
string Game::Stones(int P, vector <int> &S)
{
int i;
/* If the cache is empty, create it. */
if (Cache.size() == 0) Cache.resize(P+1, "");
/* Get the return value from the cache if it's there. */
if (Cache[P] != "") return Cache[P];
/* Otherwise, use recursion to see if there is any value
of s that will enable the caller to win. */
for (i = 0; i < S.size(); i++) {
if (P-S[i] >= 0 && Stones(P-S[i], S) == "Lose") {
Cache[P] = "Win";
return "Win";
}
}
/* If there is no such value, return that you are losing. */
Cache[P] = "Lose";
return "Lose";
}
/* Here's a main that lets you test it. */
int main()
{
int P;
int s;
vector <int> S;
Game G;
cin >> P;
while (cin >> s) S.push_back(s);
cout << G.Stones(P, S) << endl;
}
UNIX> g++ -o Stones Stones.cpp
UNIX> echo 5 1 | Stones
Win
UNIX> echo 4 1 | Stones
Lose
UNIX> echo 5 2 | Stones
Lose
UNIX> echo 5 2 3 | Stones
Lose
UNIX> echo 5 2 1 | Stones
Win
UNIX> echo 1000 7 3 11 | Stones
Lose
UNIX> echo 1000 7 3 10 | Stones
Win
UNIX>
Grading
This one is also 15 points, and like the other one, if you have a generally correct
framework, you start with 15 and get deductions. If your code isn't close, I gave
you 5 points if you had recursion and a cache, and 3 points if you only had recursion.