 |
The operating system (OS) has four kinds of data structures for files:
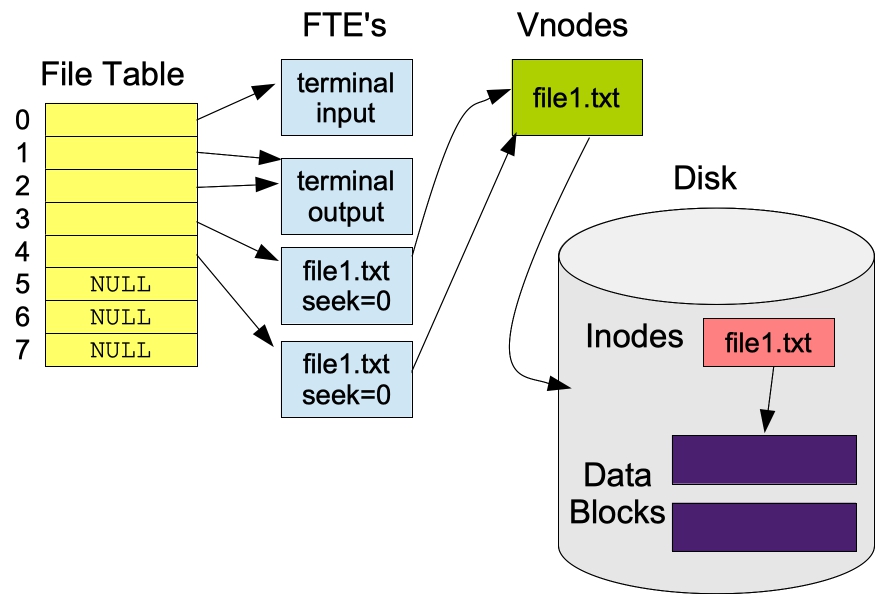
When you start your program, the OS has three file table entries defined for you -- one each for stdin, stdout, stderr, which are pointed to by entries 0, 1 and 2 in the file table. Each time you call open(), a new file table entry is created for you in the OS, and an entry in the file table is set to this entry. The index of the entry is returned as a file descriptor.
So, look at the following program (I don't have this program in a file -- it is the beginning of fs1.c).
int main()
{
int fd1, fd2;
fd1 = open("file1.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
fd2 = open("file1.txt", O_WRONLY);
}
|
What has happened? The OS has created two file table entries, one for each open() call, but only one vnode. This is because there is only one file. Both file table entries point to the same vnode, but they each have different seek pointers. The state of the system is as pictured:
|
Now, suppose we write to these file descriptors: (This is file src/fs1.c)
/* This shows what happens when you open the same file twice for writing. */
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main()
{
int fd1, fd2;
fd1 = open("file1.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
fd2 = open("file1.txt", O_WRONLY);
write(fd1, "Jim\n", strlen("Jim\n"));
write(fd2, "Plank\n", strlen("Plank\n"));
close(fd1);
close(fd2);
return 0;
}
|
Then what will happen? Well, the first write() call will write the string "Jim\n" into file1.txt. Then the second write() call will overwrite it with "Plank\n". This is because each fd points to its own file table entry, which has its own lseek pointer, and thus the first write() does not update the lseek pointer of fd2:
 |
To make this more clear, src/fs1a.c prints out the values of each fd's seek pointer at each step of the program. As you can see, even though the two fd's are for the same file, since they each have their own file table entry, they each have their own seek pointer:
UNIX> bin/fs1 UNIX> cat file1.txt Plank UNIX> bin/fs1a Before writing Jim: lseek(fd1, 0, 1): 0. lseek(fd2, 0, 1): 0 # The file has no bytes. Before writing Plank: lseek(fd1, 0, 1): 4. lseek(fd2, 0, 1): 0 # The first write puts "Jim\n" into the file. After writing Plank: lseek(fd1, 0, 1): 4. lseek(fd2, 0, 1): 6 # The second write overwrites it with "Plank\n". UNIX> cat file1.txt Plank UNIX>
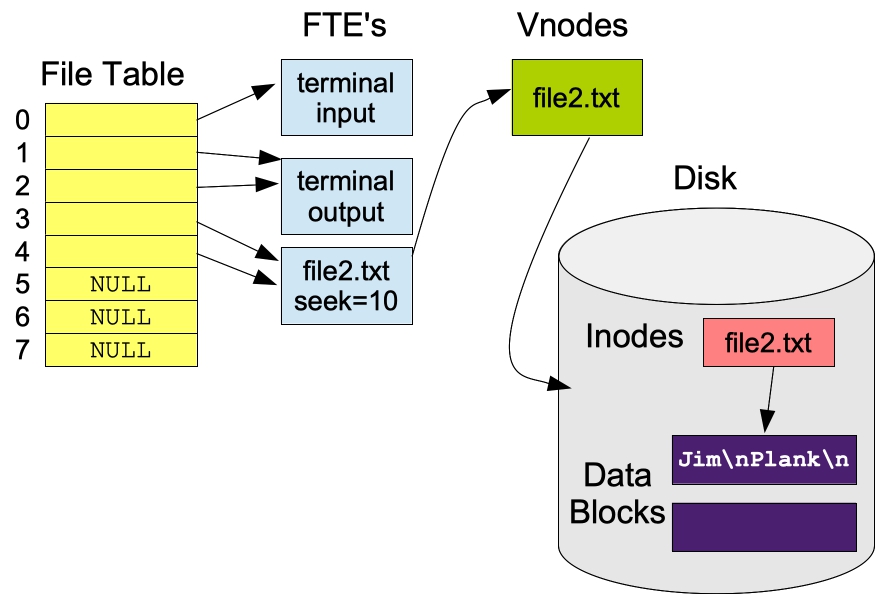
Look at an alteration of src/fs1.c (in src/fs2.c). Instead of calling open() to initialize fd2, it calls dup(fd1). Thus, after the first write, the lseek pointer of fd2 has been updated to reflect the write to fd1 -- this is because the two file descriptors point to the same file table entry.
Thus, after running bin/fs2, the file "file2.txt" should say "Jim\nPlank\n". Like src/fs1a.c, src/fs2a.c prints out the lseek pointers of fd1 and fd2 at each step. As you can see, the write() to fd1 updates the lseek pointer for fd2:
UNIX> bin/fs2 UNIX> cat file2.txt Jim Plank UNIX> bin/fs2a Before writing Jim: lseek(fd1, 0, 1): 0. lseek(fd2, 0, 1): 0 # At the beginning, the file is empty. Before writing Plank: lseek(fd1, 0, 1): 4. lseek(fd2, 0, 1): 4 # Now it contains "Jim\n", but since fd2 points to the same FTE, its seek pointer changes too. After writing Plank: lseek(fd1, 0, 1): 10. lseek(fd2, 0, 1): 10 # This appends "Plank\n" after "Jim\n" UNIX> cat file2.txt Jim Plank UNIX>
 |
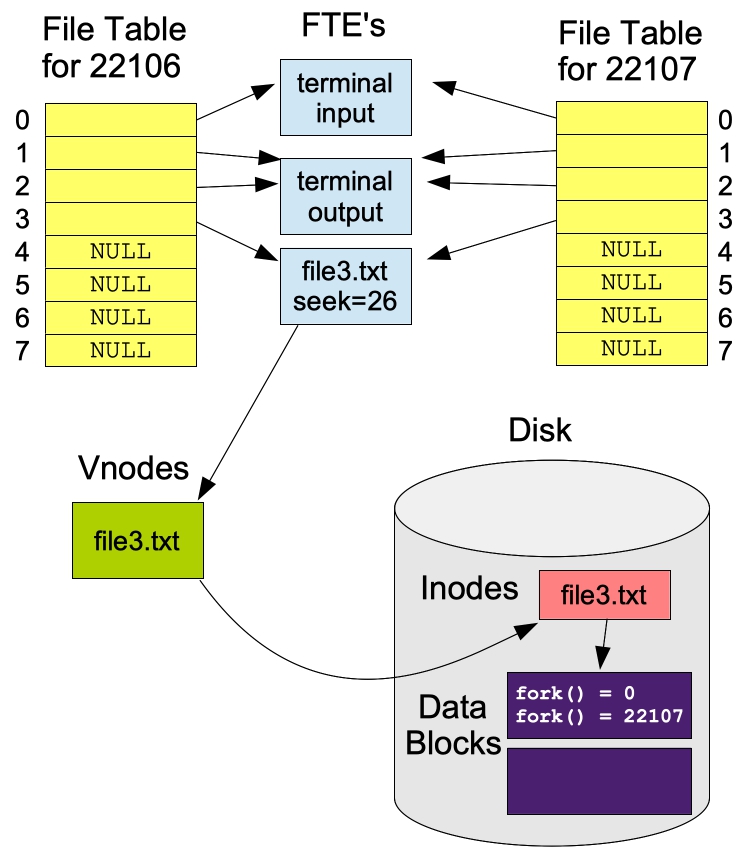
When fork() is called, all file descriptors are duplicated, as if dup() were called. Thus, look at the following program (src/fs3.c):
/* A simple program that shows how a file descriptor is "duped" during a fork() call. */
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main()
{
char s[1000];
int i, fd;
fd = open("file3.txt", O_WRONLY | O_CREAT | O_TRUNC, 0644);
i = fork();
sprintf(s, "fork() = %d.\n", i);
write(fd, s, strlen(s));
close(fd);
return 0;
}
|
What should happen? Well, whichever process gets control of the CPU first after the fork() will write s to file3.txt. Then the other process will append its string s to file3.txt. For example:
UNIX> bin/fs3 UNIX> cat file3.txt fork() = 0. fork() = 22107. UNIX> bin/fs3 UNIX> cat file3.txt fork() = 0. fork() = 22110. UNIX> bin/fs3 UNIX> cat file3.txt fork() = 22113. fork() = 0. UNIX>This is because the file descriptor fd is duplicated across fork() calls. Were it not duplicated, but instead re-opened, then one write() would overwrite the other. Here's a picture after the two processes have written in the first call to bin/fs3 above:
 |
Perhaps you're thinking, ``He opened a file and then called fork(). Does he have to worry about that buffer copying problem that was in the Fork Lecture notes?'' The answer is no, because I'm using write(), which is a system call, and there is no buffering. You have to worry about the buffering problem when the standard I/O library is being used, and the buffer is not empty when fork() is called. For example, look at src/fs3a.c and src/fs3b.c. They use fprintf() instead of write(). With src/fs3a.c, the fork() call is made before any fprintf() statement, so there is no problem with buffering (because the buffer is empty when fork() is called). With src/fs3b.c, I make a fprintf() call before the fork() call, so the buffer is copied by the fork() call, and you get two lines that say "The is file3.txt.":
UNIX> bin/fs3a UNIX> cat file3.txt fork() = 0. fork() = 3716. UNIX> bin/fs3b UNIX> cat file3.txt This is file3.txt fork() = 3719. This is file3.txt fork() = 0. UNIX>
int dup2(int fd1, int fd2)
With dup2(), fd2 specifies the desired value of the new
descriptor. If descriptor fd2 is already in use, it is
first deallocated as if it were closed by close(2V).
Dup2() is most often used so that you can redirect standard
input or output. When you call dup2(fd, 0) and the dup2()
call is successful, then whenever your program reads from standard
input, it will read from fd. Similarly, when you call
dup2(fd, 1) and the dup2()
call is successful, then whenever your program writes to standard output,
it will write to fd.
For example, look at src/dup2ex.c. This opens the file file4 for writing, and then uses dup2 to redirect standard output to that file. It then writes to standard output in a variety of ways:
/* Showing how dup2(fd, 1) redirects standard output to the file in fd. */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>
int main()
{
int fd;
char *s;
fd = open("file4", O_WRONLY | O_CREAT | O_TRUNC, 0666);
if (dup2(fd, 1) < 0) { perror("dup2"); exit(1); }
printf("Standard output now goes to file4\n");
close(fd);
printf("It goes even after we closed file descriptor %d\n", fd);
putchar('p'); putchar('u'); putchar('t'); putchar('c'); putchar('h');
putchar('a'); putchar('r'); putchar(' '); putchar('w'); putchar('o');
putchar('r'); putchar('k'); putchar('s'); putchar('\n');
s = "And fwrite\n";
fwrite(s, sizeof(char), strlen(s), stdout);
fflush(stdout);
s = "And write\n";
write(1, s, strlen(s));
return 0;
}
|
When it's done, you'll see that everything has gone into file4:
UNIX> bin/dup2ex UNIX> cat file4 Standard output now goes to file4 It goes even after we closed file descriptor 3 putchar works And fwrite And write UNIX>Why did I make the fflush() call in src/dup2ex.c? Take it out and see. Make sure that you can explain this.
The program src/dup2ex2.c puts a printf() statement at the beginning of the program:
int main()
{
int fd;
char *s;
printf("Printing this before we open anything.\n");
/* Same as before.... */
|
I'm doing this again to highlight buffering in the standard I/O library. If we run this program with standard output going to the screen, then the first printf() statement goes to the screen, and the remainder to file4. This is because the standard I/O library flushes the buffer after every newline when the output is to the screen:
UNIX> bin/dup2ex2 Printing this before we open anything. UNIX> cat file4 Standard output now goes to file4 It goes even after we closed file descriptor 3 putchar works And fwrite And write UNIX>However, if we redirect standard output to a file, then the standard I/O library does not flush the buffer until either the buffer is full, or the program exits. For that reason, the first string does not go to the screen, but instead it goes to the buffer. The buffer doesn't get flushed until after the dup2() call, so all of the output goes to file4:
UNIX> bin/dup2ex2 > file5 UNIX> cat file5 UNIX> cat file4 Printing this before we open anything. Standard output now goes to file4 It goes even after we closed file descriptor 3 putchar works And fwrite And write UNIX>I've been over this buffering phenomenon a lot. Make sure you understand it.
/* This program executes /bin/cat with stdin coming from f1.txt, and stdout
going to f2.txt. This is all done with fork, exec, and dup: */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/wait.h>
int main(int argc, char **argv, char **envp)
{
int fd1, fd2;
int dummy;
char *newargv[2];
/* In the child, first open f1.txt and then dup it to file descriptor zero. */
if (fork() == 0) {
fd1 = open("f1.txt", O_RDONLY);
if (fd1 < 0) {
perror("catf1f2: f1.txt");
exit(1);
}
if (dup2(fd1, 0) != 0) {
perror("catf1f2: dup2(f1.txt, 0)");
exit(1);
}
close(fd1);
/* In the child, next open f2.txt and then dup it to file descriptor one. */
fd2 = open("f2.txt", O_WRONLY | O_TRUNC | O_CREAT, 0644);
if (fd2 < 0) {
perror("catf1f2: f2.txt");
exit(2);
}
if (dup2(fd2, 1) != 1) {
perror("catf1f2: dup2(f2.txt, 1)");
exit(1);
}
close(fd2);
/* Set up the argv array, and call execve(). */
newargv[0] = "cat";
newargv[1] = (char *) 0;
execve("/bin/cat", newargv, envp);
perror("execve(bin/cat, newargv, envp)");
exit(1);
/* The parent merely waits for the child to exit. */
} else {
wait(&dummy);
}
return 0;
}
|
Study this program closely, because you will find it greatly helpful in the jsh lab.