The Bank Simulation
The book uses a bank simulation example to motivate the need for priority queues. We will do such a simulation, more for the programming exercise than for any other reason.Basically, we are confronted with the following problem. We are bank executives, and we need to hire tellers. We want to hire enough tellers that customers don't have to wait in line too long. However, we don't want to hire too many tellers, because we want to save money. Thus, we want to hire an optimal number of tellers.
One way to do this is to simulate a bank. To do this, we need to characterize on average when people come to a bank, and how long their transactions take. Then we can write a simulator that randomly generates people coming into a bank doing transactions, and we can see how the number of tellers impacts how long people wait, and how long tellers are idle. This will let us make a decision about the optimal number of tellers.
Now, suppose we run the following simulation:
New Person: 0 enters the bank at 1.5. Transaction time: 5.7 New Person: 1 enters the bank at 2.8. Transaction time: 1.9 New Person: 2 enters the bank at 3.3. Transaction time: 8.7 New Person: 3 enters the bank at 9.2. Transaction time: 2.7We have two tellers, and four people.
What happens is that the simulator generates four random people that enter the bank at 1.5, 2.8, 3.3, and 6.2 minutes. Their transactions take 5.7, 1.9, 8.7, and 2.8 minutes respectively. Given these parameters and two tellers, the simulation will go as follows:
- At 1.5, person 0 enters the bank. Both tellers are free, so teller 1 starts working on the person's transaction. The transaction will take 5.7 minutes, so it will be done at 7.2 minutes.
- At 2.8, person 1 enters the bank. Teller 2 is free, so teller 2 starts working on the person's transaction. The transaction will take 1.9 minutes, so it will be done at 4.7 minutes.
- At 3.3, person 2 enters the bank. Both tellers are busy, so person 2 must wait in line until one of the tellers is free.
- At 4.7, teller 2 is free, so person 2 can get off the line, and the teller can work on person 2's transaction. Person 2's transaction will take 8.7 minutes, so it will be done at 13.4 minutes.
- At 7.2, teller 1 is free. Since no one is in line, teller 1 remains free.
- At 9.2, person 3 enters the bank. Teller1 is free, so teller 1 starts working on the person's transaction. The transaction will take 2.7 minutes, so it will be done at 11.9 minutes.
- At 12.0, teller 1 is free.
- At 13.4, teller 2 is free. There are no more people generated by the simulation, so the simulation is complete.
Suppose we changed the situation so that there are three tellers. Now person 2 will not have to wait as they can be immediately served by teller 3. Persons 0, 1, and 4 still will not have to wait. The average waiting time therefore drops to 0 minutes. However, the teller idle time goes way up. Assuming that Teller 1 handles persons 0 and 3, then Teller 1 is idle from 0 to 1.5, 7.2 to 9.2, and 11.9 to 12.0, for a total of 4.1 minutes. Teller 2 is idle from 0 to 2.8 and then from 4.7 to 12 for a total of 10.1 minutes. Teller 3 is idle from 0 to 3.3 for a total of 3.3 minutes. The average idle time climbs from 3.2 minutes to 5.83 minutes. That's half the time the bank is open and would probably be considered wasteful by the bank's executives.
Hopefully, at this point, you understand the basics of the simulation -- why we're writing it, and what the input and output is like. Now we get into details.
Event Generation
One of the trickiest parts of writing a simulator is choosing how you generate random events. Suppose I say that the average transaction time is 10 minutes. The following sequence of transactions fits this description: (i.e. the numbers average to ten):8 12 10 11 9 7 13As does this sequence:
0 0 0 0 0 0 0 0 0 100I think we would all agree that these two sequences are greatly different, even though they both average to ten.
This whole area is a big area in statistics, and there is quite a bit of math involved. I am not going to bore you with it. However, I'm going to use some statistical terms and concepts.
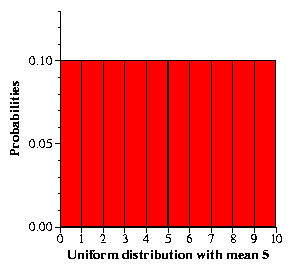
Random numbers are defined to fit what are known as distributions. These define how we can characterize the random numbers in ways that are more specific than, say, a mean value. We will use two such distributions in our simulation. The first is a very simple distribution. It is called the uniform distribution. For our purposes, if we choose a random number r according to a uniform distribution with a mean m, this means that r will have a value between 0 and 2m, and that every value between 0 and 2m are equally likely.
For example, suppose that our random numbers are integers. If we are choosing random numbers according to a uniform distribution with mean 3, then each time we choose a random number, it is equally likely that this number will be 0, 1, 2, 3, 4, 5, and 6.
Uniform distributions are very easy to use in C. There are two important functions as part of the C standard library: srandom() and random(). srandom(i) takes a long i and uses it as a seed to the random number generator. Then each time you call random() it returns a long uniformly distributed in the range [0, 231-1].
Therefore, if you want to get a random number according to a uniform distribution with a mean of m, you should use the formula:
random()%((2*m) + 1)This formula will produce random numbers between 0 and 2m. Of course you may want to restrict this range but the idea should be clear: your range should be from [m - amount, m + amount].
Here is an example:
/* generate 20 random numbers using a uniform distribution with a mean
of 50 */
srandom(737); // provide an initial "seed" to the random generator
for (i = 0; i < 20; i++) {
d = random()%101;
printf("%d \t %ld \n", i, d);
}
We can view distribution functions using histograms. For example the following histogram shows a uniform distribution function whose mean is 5:
Different distribution functions have diffierent histograms. A very important distribution function is the exponential distribution function. This distribution function has one parameter called lambda which is one over the mean of the distribution function. Here is a histogram of an exponential whose mean is 120:
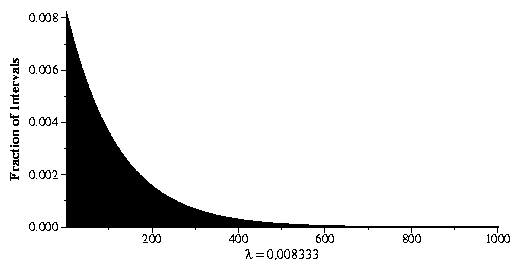
In our simulation, we are going to assume that people enter our bank according to an exponential distribution.
Generating Random Events Without Too Much Math
Now, in our simulation, we're going to generate the times that people enter a bank according to an exponential distribution. We're also going to generate their transactions according to a uniform distribution. To make this easier, we're going to define two event generator classes, histogramEventGenerator and uniformEventGenerator, which generate events from a histogram and from a uniform distribution with mean 'mean'. The declarations for these classes can be found in EventGen.h:
#include <map>
#include <string>
using namespace std;
class histogramEventGenerator {
public:
histogramEventGenerator(string filename);
~histogramEventGenerator();
long next(); // produce the next random number
protected:
map<long,long> tree;
long total;
};
class uniformEventGenerator {
public:
uniformEventGenerator(long mean);
~uniformEventGenerator();
long next(); // produce the next random number
protected:
long mean;
};
Basically, you create an event generator by giving it either a mean of
a uniform distribution, or the name of a histogram file. The format
of this file is simply lines of x and y values of the histogram. That is,
the x value is the middle of one of the histogram bars, and the y value
is the height of the bar. The y values are relative frequencies.
In other words,
they do not have to sum to 1. For example, here is a histogram file for
the uniform distribution with a mean of 1:
0 1 1 1 2 1In other words, each value between 0 and 2 is equally likely. The exponential with a lambda of 1/120 (i.e. a mean of 120) is in the file expon_120:
UNIX> head expon_120 1 8264 2 8195 3 8127 4 8060 5 7993 6 7927 7 7861 8 7796 9 7731 10 7667 UNIX> tail expon_120 1157 1 1158 1 1159 1 1160 1 1161 1 1162 1 1163 1 1164 1 1165 1 1166 1 UNIX>Now, with one of these histogram files, we can generate random numbers as follows:
- Create a C++ STL map.
- Set total to zero.
- Do the following for each line of the histogram file:
- Read in a line of the file and get an x and y value.
- Add y to total
- Insert a new node into the tree with a key of total and a value of x.
For example, suppose you wanted to do this with the histogram file for the uniform distribution with a mean of 1. You'll insert three nodes into your tree: (key=1, val=0), (key=2,val=1), (key=3,val=2). Now, when you want to get a random number, you choose a random number using random() between 0 and 2. Suppose that number is 1. You find the node whose key is the smallest key greater than 1 -- that is the node whose key is 2. And you use that xnode's val, which is 1.
In sum, the next method for the uniform and exponential event generator classes will be implemented as follows:
- For the uniform distribution, the random number is:
randomNumber = random() % ((2 * mean) + 1); - For a histogram distribution, the random number is:
index = random() % (total-1); find the first node in the map that is greater than index and return the value of this node (i.e., the x-value in the histogram)
You will write these random number simulators in lab.
Writing the Simulator
Ok -- now we have enough information to write our simulator. We're going to generate times for people entering the bank according to a histogram file. The one we'll use is expon_120, which is an exponential whose mean is 120. We'll generate transaction times according to a uniform distribution.Now, our simulator will revolve around three classes: Tellers, Persons, and Events. There will be one Teller for each teller in the bank, and we will number them starting with zero. There will be one Person for each person that enters the bank. Again, we will number them starting with zero. There will be one Event for each of the following events:
- Arrival Event: A person enters the bank. This event will contain a pointer to the Person.
- Departure Event: A teller finishes a transaction and the person leaves the bank. This event will contain a pointer to the Person and the Teller.
- A queue called line of people waiting in line at the bank. A person must wait in line if he/she is in the bank and all the tellers are busy with transactions.
- A queue called free_tellers. A teller is placed on free_tellers if he/she is free and if line is empty.
- A priority queue called eventQueue. You can use the C++ STL priority queue in which case you will store events on the queue and provide a comparator class that compares event times. For arrival events, the event time is the time that the person entered the bank. For departure events, the event time is the time that the transaction finishes and the person leaves the bank.
- An event generator that generates times from an exponential distribution. This event generator is called histogramEventGenerator.
- An event generator that generates times from a uniform distribution. This event generator is called uniformEventGenerator.
- It error checks the command line arguments.
- It creates line, free_tellers and eventQueue. At first all of these are empty.
- It creates an instance of histogramEventGenerator and uniformEventGenerator.
- Now, it creates the Tellers and puts them all on the free_tellers queue.
- Next, it creates all the Person's for the simulation, generating
both their arrival time and their transaction times.
You will write a procedure called generate_persons that
starts the time clock at 0. Your method should then repeatedly create
customers by:
- calling the histogramGenerator to generate an inter-arrival time (or elapsed time between customer arrivals)
- adding this time to the current clock time in order to get the time when the customer arrives at the bank. If the arrival time occurs after the bank "closes" (i.e., the simulation ends), then you should discard this time and return from the function. Otherwise you should update the clock time to be equal to this customer's arrival time.
- calling the uniformEventGenerator to get a transaction time.
- creating an arrivalEvent record with the new person, their arrival time, and their transaction time.
- adding the arrival event to the eventQueue.
- Now, eventQueue is processed. What happens is we grab the event with the
smallest key. This will either be a person entering the bank, or a teller
finishing a transaction. If it's an arrival event, then the following actions
are performed:
- the free_tellers queue is checked. If a teller is free, then that teller is removed from the queue, and a departure event is generated and put into eventQueue. The customer's transaction time should be added to the time at which the person is assigned to the teller to get the departure time for the event. The teller's cumulative idle time is also incremented by the amount of time the teller spent waiting on the free queue. This time can be calculated as the difference between the current time and the time when the teller was placed on the teller's queue. Finally the person's waiting time is calculated. The idle time is equal to the time when the transaction started minus the time the person entered the bank. The waiting time is added to a counter that keeps track of cumulative waiting time. If no teller is free, then the person is put onto line.
If the event is a departure event, then the following actions occur:
- A counter that keeps track of the number of people processed is incremented.
- The person is deleted (i.e. the person leaves the bank), and the teller either processes the next person on the line, or puts itself onto the free_tellers queue. If the teller puts itself onto the free_tellers queue, then it records the time it is put on the queue.
You keep processing events until eventQueue is empty. When eventQueue is empty, the simulation is over.