 |
The code is in src/reverse_1.cpp:
/* This program shows how to reverse standard input using a list.
We create the list with push_front(), so the list holds the
lines of standard input in reverse order. Therefore, we traverse
it from front to back with a const_interator. */
#include <iostream>
#include <list>
using namespace std;
int main()
{
list <string> lines;
string s;
list <string>::const_iterator lit; // We use const_iterator, because the iterator
// does not change its contents.
while (getline(cin, s)) lines.push_front(s);
for (lit = lines.begin(); lit != lines.end(); lit++) {
cout << *lit << endl;
}
return 0;
}
|
A few things -- you declare an empty list just like you declare an empty vector. In fact, the code to create the list is very much like the code to create a vector, except we are using push_front() to prepend each string to the front of the list.
To traverse the list, we use an iterator, which is a special type defined by the standard template library (STL). The for loop is typical -- you start with the first element of the list, obtained with the begin() method, and traverse until you are one element beyond the end of the list (signified by the end() method). To go from one element to the next, you increment the iterator. This is operator overloading, implemented by the STL.
Then, to access the element in the list, you use pointer indirection (the asterisk), which is in fact really another overloaded method. When you get used to seeing this code, it reads nicely. It does take a little acclimation though. Regardless, it works:
UNIX> cat files/input.txt 1. Born in the night 2. She would run like a leopard 3. That freaks at the sight 4. Of a mind close beside herself UNIX> bin/reverse_1 < files/input.txt 4. Of a mind close beside herself 3. That freaks at the sight 2. She would run like a leopard 1. Born in the night UNIX>
/* This also reverses standard input, by appending the strings to the list,
and then using a "reverse" iterator to traverse the list backward. */
#include <iostream>
#include <list>
using namespace std;
int main()
{
list <string> lines;
list <string>::const_reverse_iterator lit;
string s;
while (getline(cin, s)) lines.push_back(s);
for (lit = lines.rbegin(); lit != lines.rend(); lit++) {
cout << *lit << endl;
}
return 0;
}
|
We create the list with push_back(), and we change lit to be a const_reverse_iterator. Once again, the "const" part says that I won't change what the iterator points to. The "reverse" part says that when I increment the iterator, it moves backward in the list.
The iteration proceeds from rbegin(), which is the last element of the list, to rend(), which is one element before the first element of the list. Again, increment lit to have it go backward in the list. Is that natural? You be the judge.
UNIX> bin/reverse_2 < files/input.txt 4. Of a mind close beside herself 3. That freaks at the sight 2. She would run like a leopard 1. Born in the night UNIX>
The program src/reverse_3.cpp implements reversal by inserting each element at the front and traversing the list in the forward direction:
/* This program now creates the list in reverse order by inserting each
string before the first element in the list. This is equivalent to
calling push_front(). */
#include <iostream>
#include <list>
using namespace std;
int main()
{
list <string> lines;
list <string>::const_iterator lit;
string s;
while (getline(cin, s)) lines.insert(lines.begin(), s); // This is equivalent to push_front().
for (lit = lines.begin(); lit != lines.end(); lit++) {
cout << *lit << endl;
}
return 0;
}
|
It works like the others:
UNIX> bin/reverse_3 < files/input.txt 4. Of a mind close beside herself 3. That freaks at the sight 2. She would run like a leopard 1. Born in the night UNIX>
/* This code inserts each string at the front of a vector, instead of a list.
What this does is resize the vector at every insert() call, move each element
over one, and put the new string at element 0. Thus, it is *really*
inefficient code. Its performance will scale quadratically with the
size of the input. */
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector <string> lines;
vector <string>::const_iterator lit;
string s;
while (getline(cin, s)) lines.insert(lines.begin(), s);
for (lit = lines.begin(); lit != lines.end(); lit++) {
cout << *lit << endl;
}
return 0;
}
|
I call this ill-judged because when you perform an insertion such as v.insert(v.begin(), x), the STL basically does the following:
v.resize(v.size()+1); for (i = v.size(); i > 0; i--) v[i] = v[i-1]; v[0] = x; |
In other words, it copies all of the elements of the vector to make room for the new element at v[0]. This is expensive, and makes reverse_4.cpp above run in time proportional to n2, when n is the number of lines in standard input. (Later, we'll call that O(n2)).
To illustrate, files/input_2.txt is an files/input file with 10,000 lines, and files/input_3.txt is one with 40,000 lines. Look at the difference in speed between bin/reverse_3 and bin/reverse_4 (this was on my 2.2 GHz MacBook in 2019):
UNIX> wc files/input_2.txt 10000 10000 80000 files/input_2.txt UNIX> wc files/input_3.txt 40000 40000 320000 files/input_3.txt 0.000u 0.000s 0:00.00 0.0% 0+0k 0+0io 0pf+0w UNIX> time bin/reverse_3 < files/input_2.txt > /dev/null 0.017u 0.003s 0:00.02 50.0% 0+0k 0+0io 0pf+0w # 0.02 seconds UNIX> time bin/reverse_3 < files/input_3.txt > /dev/null 0.066u 0.013s 0:00.08 87.5% 0+0k 0+0io 0pf+0w # 0.08 seconds UNIX> time bin/reverse_4 < files/input_2.txt > /dev/null 0.696u 0.004s 0:00.70 98.5% 0+0k 0+0io 0pf+0w # 0.70 seconds UNIX> time bin/reverse_4 < files/input_3.txt > /dev/null 10.460u 0.014s 0:10.47 100.0% 0+0k 0+0io 0pf+0w # 10.47 seconds!! UNIX>As you can see, bin/reverse_3 is very fast, while bin/reverse_4 becomes painfully slow!! This is is important, and you should take care that it doesn't happen to you.
A good rule of thumb is to use a vector as a direct-access data structure, and not a list. Don't use iterators -- use integer indices. Then you're ok.
/* This code uses a deque to store standard input in reverse order.
We then traverse it in the forward direction, to print standard input
in reverse order. Deques are like vectors, because we can access
elements with integer indices. They differ, because you can insert
and delete from both the front and the back. With vectors, you should
only insert and delete from the back. */
#include <iostream>
#include <deque>
using namespace std;
int main()
{
deque <string> lines;
size_t i;
string s;
while (getline(cin, s)) lines.push_front(s);
for (i = 0; i < lines.size(); i++) cout << lines[i] << endl;
return 0;
}
|
Unlike the vector version, this one runs very fast:
UNIX> bin/reverse_4 < files/input.txt 4. Of a mind close beside herself 3. That freaks at the sight 2. She would run like a leopard 1. Born in the night UNIX> time bin/reverse_5 < files/input_2.txt > /dev/null 0.017u 0.004s 0:00.02 50.0% 0+0k 0+0io 0pf+0w # 0.02 seconds UNIX> time bin/reverse_5 < files/input_3.txt > /dev/null 0.065u 0.012s 0:00.07 100.0% 0+0k 0+0io 0pf+0w # 0.07 seconds UNIX>
/* This program uses lists to print the last ten lines of standard input.
It calls push_back to append each line to the list, and then whenever
the list becomes greater than 10 elements, it deletes the first element. */
#include <iostream>
#include <list>
using namespace std;
int main()
{
list <string> lines;
list <string>::const_iterator lit;
string s;
while (getline(cin, s)) {
lines.push_back(s);
if (lines.size() > 10) lines.erase(lines.begin());
}
for (lit = lines.begin(); lit != lines.end(); lit++) {
cout << *lit << endl;
}
return 0;
}
|
Works fine:
UNIX> bin/mytail_list < files/input_2.txt 9991 9992 9993 9994 9995 9996 9997 9998 9999 10000 UNIX> bin/mytail_list < files/input_3.txt 39991 39992 39993 39994 39995 39996 39997 39998 39999 40000 UNIX>As with the previous example, we can port the code directly to vectors and to deques, since they both implement an erase() method. I've done that with src/mytail_100_list.cpp, src/mytail_100_deque.cpp, and src/mytail_100_vector.cpp, which all print the last 100 lines, rather than the last 10 (because that amplifies the difference when you use vectors). You can see that the vector implemention performs worse, since it copies all of the remaining elements upon deletion (the shell scripts make them do more work so that you can see the difference in their performance):
UNIX> time sh scripts/big_mytail_list.sh 0.601u 0.008s 0:00.60 100.0% 0+0k 0+0io 0pf+0w # 0.60 seconds for list UNIX> time sh scripts/big_mytail_deque.sh 0.629u 0.008s 0:00.63 98.4% 0+0k 0+0io 0pf+0w # 0.63 seconds for deque UNIX> time sh scripts/big_mytail_vector.sh 1.736u 0.010s 0:01.74 100.0% 0+0k 0+0io 0pf+0w # 1.74 seconds for vector UNIX>
This is from Topcoder SRM 346 D2, 250-pointer. Here's their problem description. The bottom line is that you have a string s, composed of less-than and greater-than signs. Your job is to look for "diamonds" which are "<>" substrings. If you find a diamond, you remove it from the string, and continue to look for more diamonds. You return the number of diamonds that you find.
They give a few examples:
| String | Number of diamonds |
| "><<><>>><" | 3 |
| ">>>><<" | 0 |
| "<<<<<<<<<>>>>>>>>>" | 9 |
| "><<><><<>>>><<>><<><<>><<<>>>>>><<<" | 14 |
This implementation works directly from the problem statement, using the find() method of strings to find a diamond, and then "removing" the diamond by creating two substrings:
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;
class DiamondHunt {
public:
int countDiamonds(string mine);
};
/* We count diamonds by searching for "<>" in the string. If we find it, we "remove" it by
recreating the string with the concatenation of the two substrings surrounding the "<>". */
int DiamondHunt::countDiamonds(string mine)
{
int num_diamonds;
size_t i;
num_diamonds = 0;
while (1) {
i = mine.find("<>");
if (i == string::npos) return num_diamonds;
num_diamonds++;
mine = mine.substr(0, i) + mine.substr(i+2);
}
}
/* The main reads the strings from standard input and calls the method on each string. */
int main()
{
DiamondHunt d;
string s;
while (cin >> s) {
cout << d.countDiamonds(s) << endl;
}
return 0;
}
|
When we test it out, it works fine:
UNIX> bin/DiamondHunt1 <> 1 >< 0 ><<><>>>< 3 >>>><< 0 <<<<<<<<<>>>>>>>>> 9 ><<><><<>>>><<>><<><<>><<<>>>>>><<< 14 <CNTL-D> UNIX>Although this solution works, think about its running time. In particular, think about the "<<<<<<<<<>>>>>>>>>" input. It has to scan nine characters before finding the diamond. Then the next time it has to scan 8, then 7, etc. In other words, if you have a string of n less-than signs followed by n greater-than signs, you will have to perform n2 scans to find the diamonds. When n is small (25 in the topcoder constraints), that doesn't make a difference. However, it can matter. The program src/make_bad_diamond.cpp is a very simple C++ program that takes n on the command line and produces a string with n less-than signs followed by n greater-than signs. See what happens when we call it with successively larger values and time the output:
UNIX> time sh -c "bin/make_bad_diamond 100 | bin/DiamondHunt1" 100 0.003u 0.004s 0:00.00 0.0% 0+0k 0+0io 0pf+0w # 0.00 seconds for 100 diamonds UNIX> time sh -c "bin/make_bad_diamond 1000 | bin/DiamondHunt1" 1000 0.009u 0.005s 0:00.01 0.0% 0+0k 0+0io 0pf+0w # 0.01 seconds for 1000 diamonds UNIX> time sh -c "bin/make_bad_diamond 10000 | bin/DiamondHunt1" 10000 0.478u 0.006s 0:00.48 97.9% 0+0k 0+0io 0pf+0w # 0.48 seconds for 10000 diamonds UNIX> time sh -c "bin/make_bad_diamond 100000 | bin/DiamondHunt1" 100000 45.692u 0.053s 0:45.75 99.9% 0+0k 0+0io 0pf+0w # 45.75 seconds for 100000 diamonds! UNIX>When the input size is increased by a factor of 10, the running time is increased by a factor of 100. That's not good.
Instead, src/DiamondHunt2.cpp uses a list. It copies the elements of mine to a list, and then uses three iterators on the list:
/* This is an implementation of DiamondHunt which uses a list rather than a string.
It improves the performance drastically, because it is not making those big
substrings, and it does not perform all of those find operations. Please read
the lecture notes for an explanation of the iterators. */
#include <iostream>
#include <list>
#include <string>
using namespace std;
class DiamondHunt {
public:
int countDiamonds(string mine);
};
int DiamondHunt::countDiamonds(string mine)
{
int num_diamonds;
size_t i;
list <char> l;
list <char>::const_iterator left, right, newleft;
/* Create the list from the string. */
for (i = 0; i < mine.size(); i++) l.push_back(mine[i]);
num_diamonds = 0;
left = l.begin();
while (left != l.end()) {
if (*left == '>') {
left++; // If left is not the beginning of a diamond, move on.
} else {
right = left;
right++;
if (right == l.end()) return num_diamonds;
if (*right == '<') { // If right is not the end of a diamond, move on
left++;
} else { // Otherwise, we've found a diamond. We need to increment
num_diamonds++; // num_diamonds, and set newleft to point to the previous
// char, or if left is at the beginning, to the next one.
if (left == l.begin()) {
newleft = right;
newleft++;
} else {
newleft = left;
newleft--;
}
l.erase(left); // Now erase left and right, and set left to newleft.
l.erase(right);
left = newleft;
}
}
}
return num_diamonds;
}
int main()
{
DiamondHunt d;
string s;
while (cin >> s) {
cout << d.countDiamonds(s) << endl;
}
return 0;
}
|
It works on the examples as before:
UNIX> bin/DiamondHunt2 <> 1 >< 0 ><<><>>>< 3 >>>><< 0 <<<<<<<<<>>>>>>>>> 9 ><<><><<>>>><<>><<><<>><<<>>>>>><<< 14 UNIX>However, it is much faster than the previous version because we don't traverse the list on each iteration as we did with m.find():
UNIX> time sh -c "bin/make_bad_diamond 10000 | bin/DiamondHunt2" 10000 0.013u 0.005s 0:00.01 100.0% 0+0k 0+0io 0pf+0w # 0.01 seconds for 10,000 diamonds UNIX> time sh -c "bin/make_bad_diamond 100000 | bin/DiamondHunt2" 100000 0.102u 0.008s 0:00.09 111.1% 0+0k 0+0io 0pf+0w # 0.09 seconds for 100,000 diamonds UNIX> time sh -c "bin/make_bad_diamond 1000000 | bin/DiamondHunt2" 1000000 0.967u 0.034s 0:00.82 120.7% 0+0k 0+0io 0pf+0w # 0.89 seconds for 1,000,000 diamonds UNIX>As we increase the string by a factor of 10, we increase the running time by a factor of ten. That's much better than DiamondHunt1.
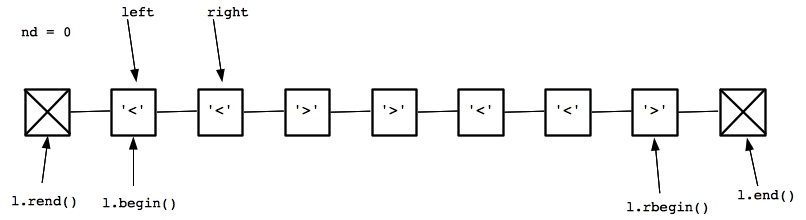
It's important for you to understand the code in src/DiamondHunt2.cpp. To help you, here's an example when we call it on the string: "<<>><<>": I will draw every iteration of the while() loop. Here are the list and the iterators in the first iteration:
|
I'm drawing the list with two sentinel nodes at each end. Before the first node is a sentinel node for l.rend(), and after the last node is a sentinel node for l.end(). We start with left equaling l.begin(), and since it points to a less-than character, we set right to be the next node. Since right also points to a less-than node, there is no diamond -- we increment left and go to the next iteration of the while() loop:
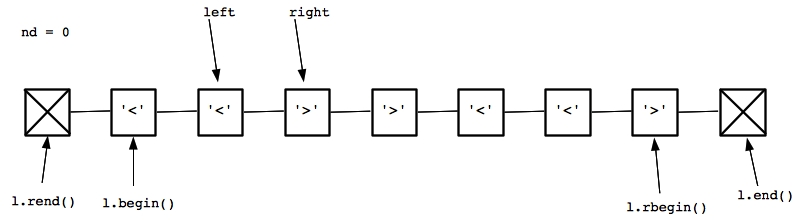 |
Now left points to a less-than and right points to a greater-than. So, we increment nd and then set newleft to be the node before left. That is pictured below:
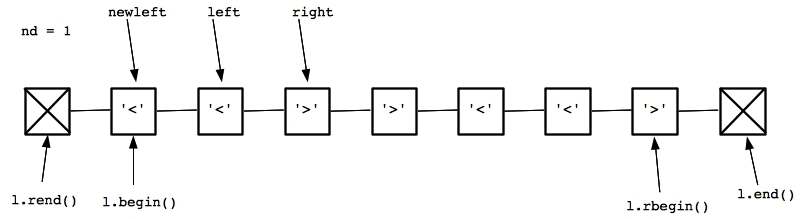 |
We then erase left and right, and set left to newleft before going back to the top of the while() loop. Here's what happens in the next iteration:
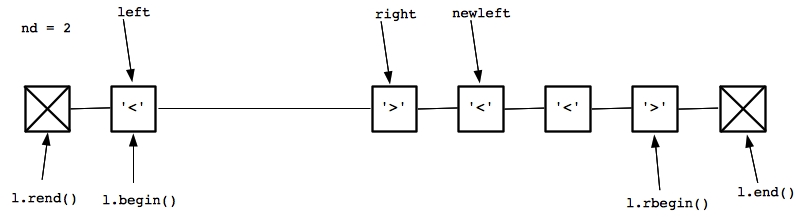 |
The two erased nodes are gone from the picture, and left and right point to a diamond. Thus, nd is incremented, and since left is equal to l.begin(), we set newleft to be the node after right. That is the state pictured above. We then erase left and right, and set left to newleft before going back to the top of the while() loop. Here's what happens in the fourth iteration:
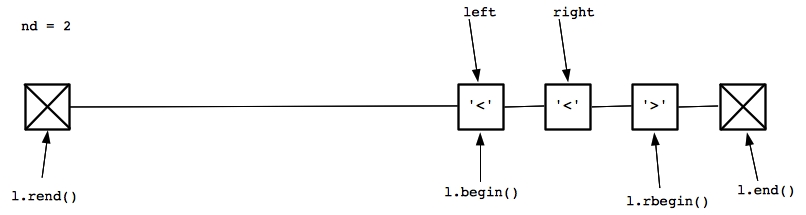 |
This is the same case as the first iteration -- no diamond. We increment left and move on:
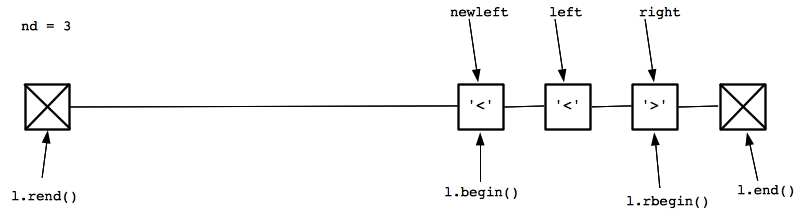 |
We have a diamond. We first increment nd. Next, since left is not equal to l.begin(), we set newleft to point to the node before left. That is depicted above. We then erase, set left to newleft and reach the last iteration of the while() loop:
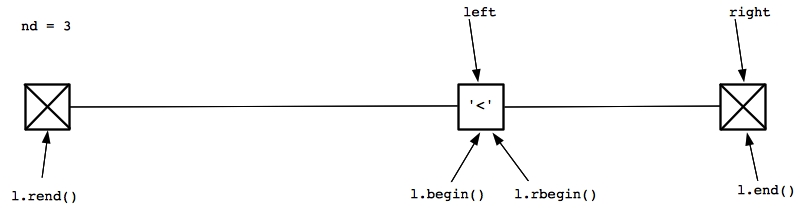 |
Since right equals l.end(), we return 3, and we're done. It's important that you step through this example until you understand it. You may even want to step through what happens when the string is we call it on the string "<<>>><>". The execution is very similar, except the fourth and sixth iterations look a little different.