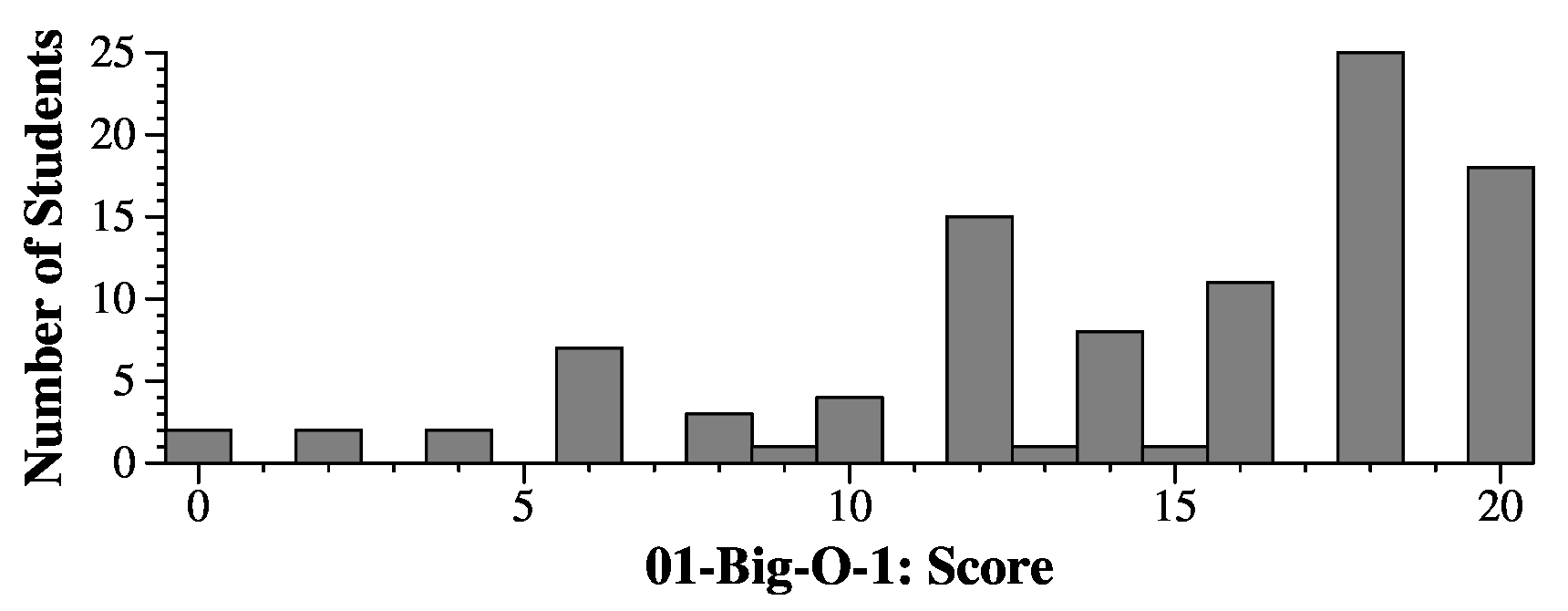
 |
With the exception of questions 5 and 6, there were many different exam sheets, which either shuffled the questions and answers, or used different names for example input. I will let you know here how to map your exam to these answers.
Below is the order in which I graded the questions, so this is the order you'll see on your grading sheet:
void XXX(int n)
{
int i;
vector <int> v;
for (i = 0; i < n; i++) v.push_back(i);
}
|
void XXX(int n)
{
int i;
deque <int> v;
for (i = 0; i < n; i++) v.push_back(i);
}
|
void XXX(int n)
{
int i;
deque <int> v;
for (i = 0; i < n; i++) v.push_front(i);
}
|
void XXX(int n)
{
int i;
list <int> v;
for (i = 0; i < n; i++) v.insert(v.begin(), i);
}
|
void XXX(int n)
{
int i;
set <int> v;
for (i = 0; i < n; i++) v.insert(i);
}
|
void XXX(int n)
{
int i;
map <int, int> v;
for (i = 0; i < n; i++) v.insert(make_pair(i,i));
}
|
void XXX(int n)
{
int i;
unordered_map <int, int> v;
for (i = 0; i < n; i++) v.insert(make_pair(i,i));
}
|
int XXX(int n)
{
int i, s;
s = 0;
for (i = 0; i < (1 << n); i++) s++;
return s;
}
|
int XXX(int n)
{
int i, j, s;
s = 0;
for (i = 0; i < n; i++) {
for (j = 0; j < i; j++) s++;
}
return s;
}
|
void XXX(int n)
{
vector <int> v;
int i;
for (i = 0; i < n; i++) v.insert(v.begin(), i);
}
|
In your exams, the names of the procedures correspond to which question they were. Here is a mapping of those names to the question numbers above:
p00e77: #6 p02bf9: #1 p0669d: #1 p07a0d: #3 p08507: #9 p0da13: #9 p0dc1f: #2 p0fede: #6 p100e0: #3 p1aec9: #4 | p1b0b6: #3 p1df98: #7 p21776: #3 p236d7: #7 p27f0a: #7 p311f9: #8 p3160e: #1 p3477c: #6 p40e31: #3 p42750: #1 | p4e202: #6 p53d3b: #8 p549ee: #9 p54ccb: #1 p5f687: #6 p61666: #4 p6f3cf: #9 p71d53: #5 p75dd5: #6 p76598: #9 | p7d691: #1 p80027: #10 p82b0f: #10 p8326b: #8 p868c8: #1 p89739: #5 p8eb9d: #2 p8feb9: #10 p90294: #8 p96864: #3 | p96cc2: #3 p9d926: #5 p9edbf: #7 pa0559: #7 pa12be: #8 pa16fa: #4 pa3e27: #6 pa4d20: #5 pa91cd: #2 pa9a2a: #2 | pab7da: #10 padfb1: #10 paf481: #5 pb52f1: #10 pba554: #9 pbbad2: #8 pc0aa4: #4 pc3d12: #4 pc66fb: #4 pcd698: #5 | pcdfd6: #8 pd087b: #4 pd7cff: #7 pe092f: #2 pe1155: #2 ped5c1: #10 pf8243: #9 pf8e3d: #7 pfda9c: #5 pfe5f4: #2 |
|
void XXX(vector <int> &v1, int m)
{
int i;
for (i = 0; i < m; i++) v1.push_back(i);
}
|
int XXX(set <int> &v1, int m)
{
int i;
int j;
j = 0;
for (i = 0; i < m; i++) {
if (v1.find(i) != v1.end()) j++;
}
return j;
}
|
int XXX(int n, int m)
{
int i, j, s;
s = 0;
for (i = 0; i < n; i++) {
for (j = 1; j < m; j = 2 * j) s++;
}
return s;
}
|
vector <int> XXX(vector <int> &v1)
{
vector <int> rv;
int i, k, t, n;
for (i = 1; i < v1.size()-1; i++) {
t = 0;
n = 0;
for (k = -1; k <= 1; k++) {
n++;
t += v1[i+k];
}
rv.push_back(t/n);
}
return rv;
}
|
So the answers are either O(n) or O(2n)
int XXX(vector <int> &v1, int m)
{
int i, j, t;
j = 1;
t = 0;
for (i = 0; i < v1.size(); i++) j *= 2;
for (i = 0; i < j; i++) {
t += (v1[j] % v1.size());
}
return t;
}
|
int XXX(vector < vector < int> > v1)
{
int i, j, t, n;
n = 0;
t = 0;
for (i = 0; i < v1.size(); i += 10) {
for (j = 0; j < v1[i].size(); j += 5) {
t += v1[i][j];
n++;
}
}
return t/n;
}
|
int XXX(map <int, int> &v1, int m)
{
int i, total;
map <int, int>::iterator mit;
total = 0;
for (i = 0; i < m; i++) {
for (mit = v1.begin(); mit != v1.end(); mit++) {
total += (i + mit->first - mit->second);
}
}
return total;
}
|
p00e7c: #4 p07c1e: #8 p09131: #4 p0df46: #1 p122e9: #6 p14db3: #7 p1af08: #2 p1ecd9: #7 | p1fc00: #7 p23520: #5 p26c31: #4 p2c465: #7 p2f62d: #1 p3313a: #6 p34f88: #8 p3ccbb: #1 | p3ecb6: #6 p3eddf: #6 p42e5e: #4 p52723: #8 p55a40: #6 p57e30: #1 p59fcc: #7 p5ad86: #5 | p5cb3c: #2 p5d411: #8 p6677f: #7 p69796: #3 p69e02: #5 p7ad0a: #4 p7eca0: #3 p8099b: #1 | p80e6d: #5 p80eb7: #2 p815b8: #1 p83d4c: #2 p85f12: #2 p86373: #5 p8cb92: #4 p9b105: #3 | p9eca0: #4 pabfda: #5 pad910: #2 pb9a18: #8 pc1100: #8 pca9db: #3 pd0772: #2 pd327b: #6 | pdeac7: #7 pe6800: #5 pec986: #1 ped63b: #3 pf1032: #6 pfa353: #3 pfb194: #3 pfcdb5: #8 |
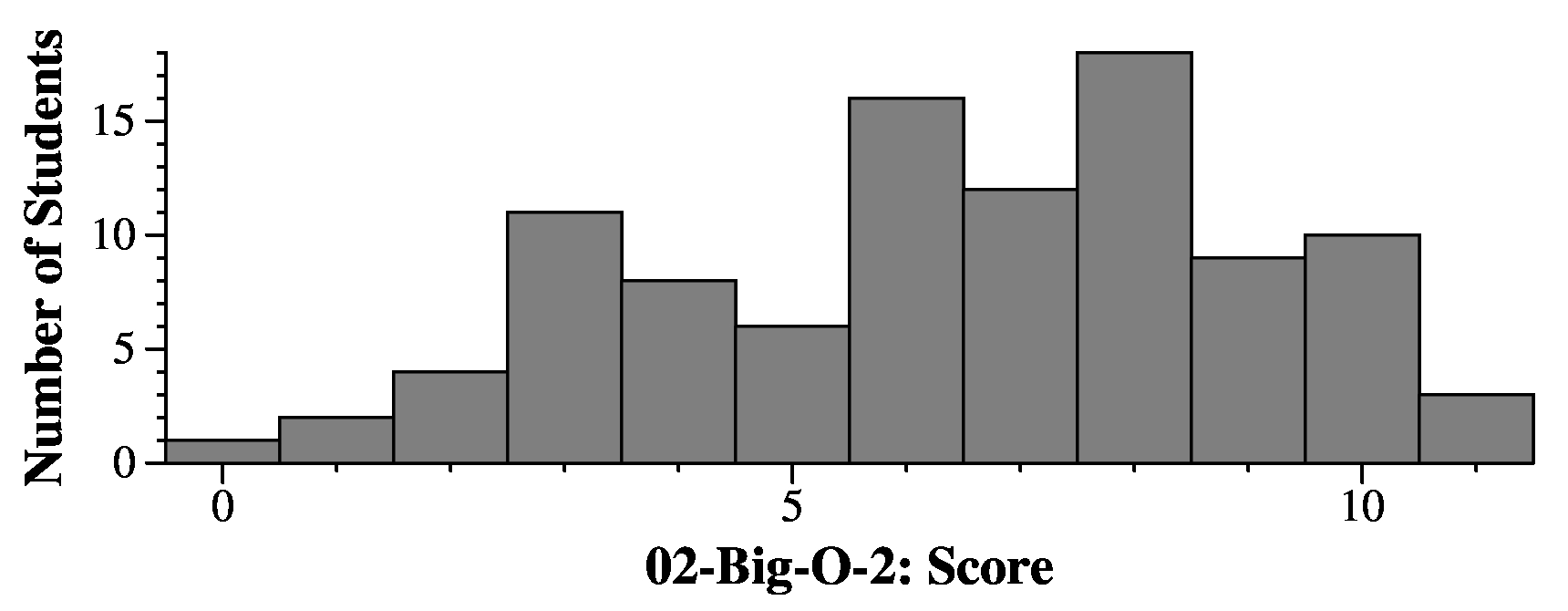 |
s: |-----------| |-----------| |-----------| |-----------| |-----------|
| top |---->| s: Dot | | s: Chase | | s: Benji | | s: Amelia |
| size: 4 | | next |---->| next |---->| next |---->| next=NULL |
|-----------| |-----------| |-----------| |-----------| |-----------|
|
When we call Pop(), "Dot" is returned and removed from the stack. So x is "Dot", and the stack is:
s: |-----------| |-----------| |-----------| |-----------|
| top |---->| s: Chase | | s: Benji | | s: Amelia |
| size: 3 | | next |---->| next |---->| next=NULL |
|-----------| |-----------| |-----------| |-----------|
^ ^ ^
| | |
| | |
s.top s.top->next s.top->next->next
|
Therefore, the answers to 1-4 are:
1. Dot 2. Chase 3. Benji 4. 3In the second column, we have a queue. first points to the first node, which is the least recently pushed node. last points to the last node, which is the most recently pushed. And each node's ptr points to the node most recently pushed after the node. So, after the four Push() calls, the queue is:
p: |-----------| |-----------| |-----------| |-----------| |-----------|
| first |---->| s: Ervin | | s: Franz | | s: Gustav | | s: Hugh |
| last |\ | ptr |---->| ptr |---->| ptr |---->| ptr=NULL |
| size: 4 | \ |-----------| |-----------| |-----------| ->|-----------|
|-----------| \ /
\---------------------------------------------------/
|
When we Pop(), "Ervin" is returned, and the queue becomes:
q: |-----------| |-----------| |-----------| |-----------|
| first |---->| s: Franz | | s: Gustav | | s: Hugh |
| last |\ | ptr |---->| ptr |---->| ptr=NULL |
| size: 3 | \ |-----------| |-----------| ->|-----------|
|-----------| \ /
\---------------------------------/
|
Therefore, the answers to 5-9 are:
5. Ervin 6. Franz 7. Hugh 8. 3 9. 1You'll note, that there's no segfault -- q.last is a valid node, and q.last->ptr is NULL.
In the last column, we have a dlist. After the two Push_Back() calls, the list is:
/-------------------------------\
/ \
d: |-----------| |-----------|<-/ |-----------| |-----------| |
| sentinel |---->| s: - | | s: Ignace | | s: June | |
| size: 2 | | flink |---->| flink |---->| flink |-/
|-----------| /| blink |<----| blink |<----| blink |
| |-----------| |-----------| ->|-----------|
\ /
\-------------------------------/
|
Now, the two Push_Front() commands put Ken, Layla and Michael at the front, in the order Michael-Layla-Ken:
/-------------------------------------------------------------------------------------\
/ \
d: |-----------| |-----------|<-/ |-----------| |-----------| |-----------| |-----------| |-----------| |
| sentinel |---->| s: - | | s: Michael| | s: Layla | | s: Ken | | s: Ignace | | s: June | |
| size: 2 | | flink |---->| flink |---->| flink |---->| flink |---->| flink |---->| flink |-/
|-----------| /| blink |<----| blink |<----| blink |<----| blink |<----| blink |<----| blink |
| |-----------| |-----------| |-----------| |-----------| |-----------| ->|-----------|
\ /
\-------------------------------------------------------------------------------------/
|
The Pop_Back() calls sets s to "June" and deletes "June":
/-------------------------------------------------------------------\
/ \
d: |-----------| |-----------|<-/ |-----------| |-----------| |-----------| |-----------| |
| sentinel |---->| s: - | | s: Michael| | s: Layla | | s: Ken | | s: Ignace | |
| size: 2 | | flink |---->| flink |---->| flink |---->| flink |---->| flink |-/
|-----------| /| blink |<----| blink |<----| blink |<----| blink |<----| blink |
| |-----------| |-----------| |-----------| |-----------| ->|-----------|
\ /
\-------------------------------------------------------------------/
|
This gives us the last six lines:
10. June 11. Michael 12. Layla 13. Ignace 14. Ken 15. 5
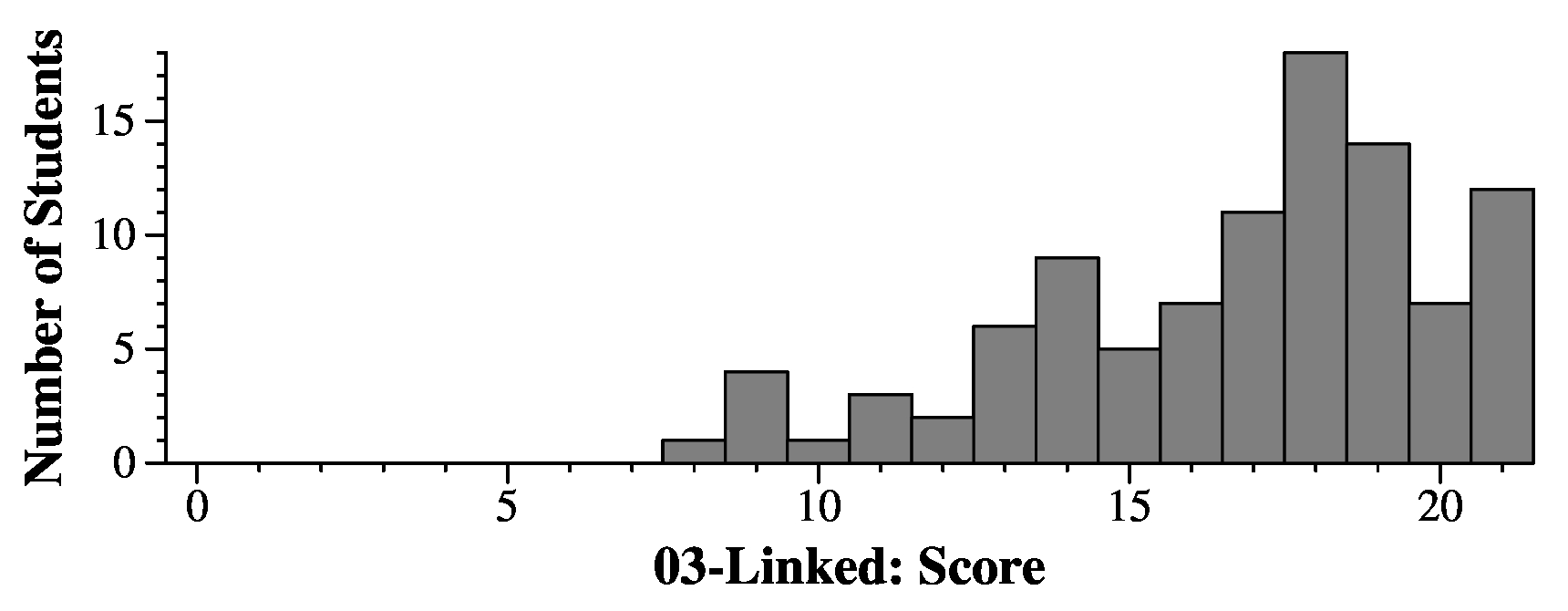 |
The answer to the second question lies in the fact that each person will be allocated once with new. Therefore, each person will be in two data structures, pvec and pmap. You only need to traverse one of them and delete the people. Therefore, the answer is:
People::~People()
{
size_t i;
for (i = 0; i < pvec.size(); i++) delete(pvec[i]);
}
|
The other good answer was:
People::~People()
{
size_t i;
Person *p;
for (i = 0; i < pvec.size(); i++) {
p = pvec[i];
delete(pmap[p->name]));
}
}
|
This answer is less efficient than the first one, but it is correct, and so it received 3.9 of 4 points.
The majority answer was the following:
People::~People()
{
size_t i;
unordered_map <string, Person *>::iterator mit;
for (i = 0; i < pvec.size(); i++) delete(pvec[i]);
for (mit = pmap.begin(); mit != pmap.end(); mit++) {
delete mit->second;
}
}
|
This answer is incorrect, because you delete each person twice -- once in pvec and once in pmap.
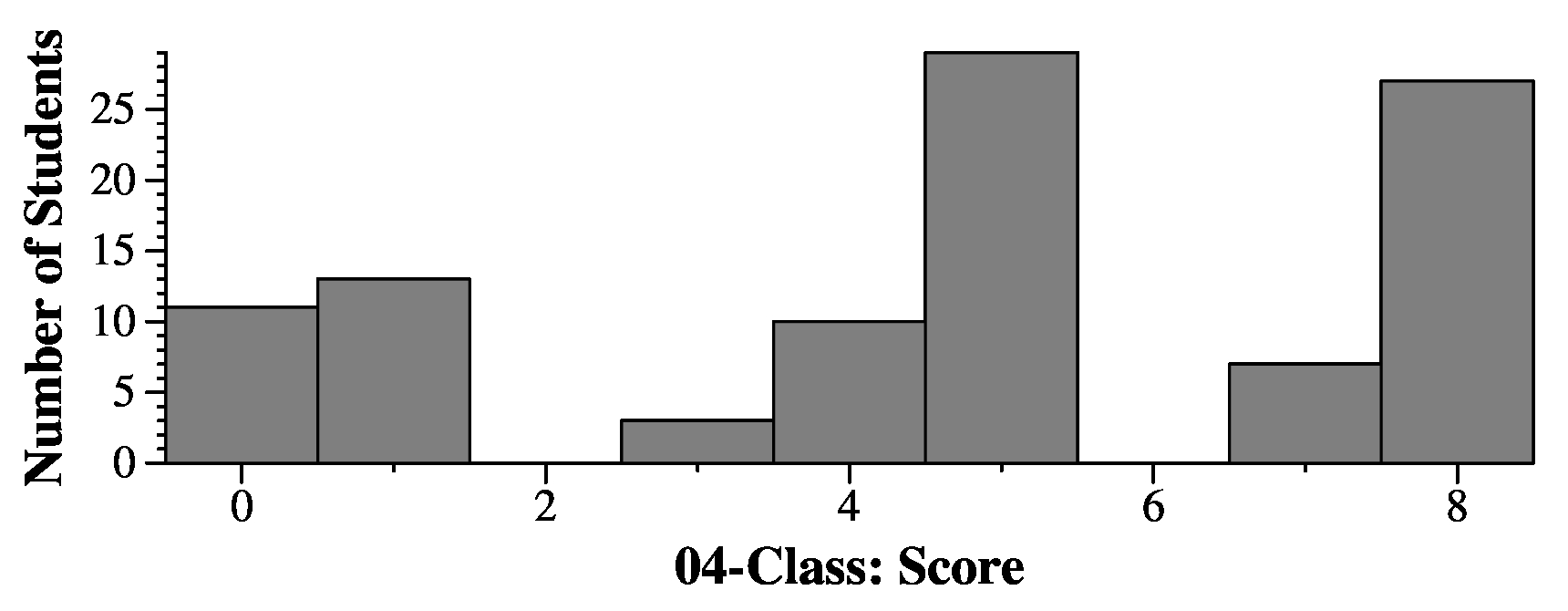 |
bool People::add_person(const string &name, int age)
{
Person *p;
if (pmap.find(name) != pmap.end()) return false;
p = new Person;
p->name = name;
p->age = age;
pvec.push_back(p);
pmap[name] = p;
return true;
}
|
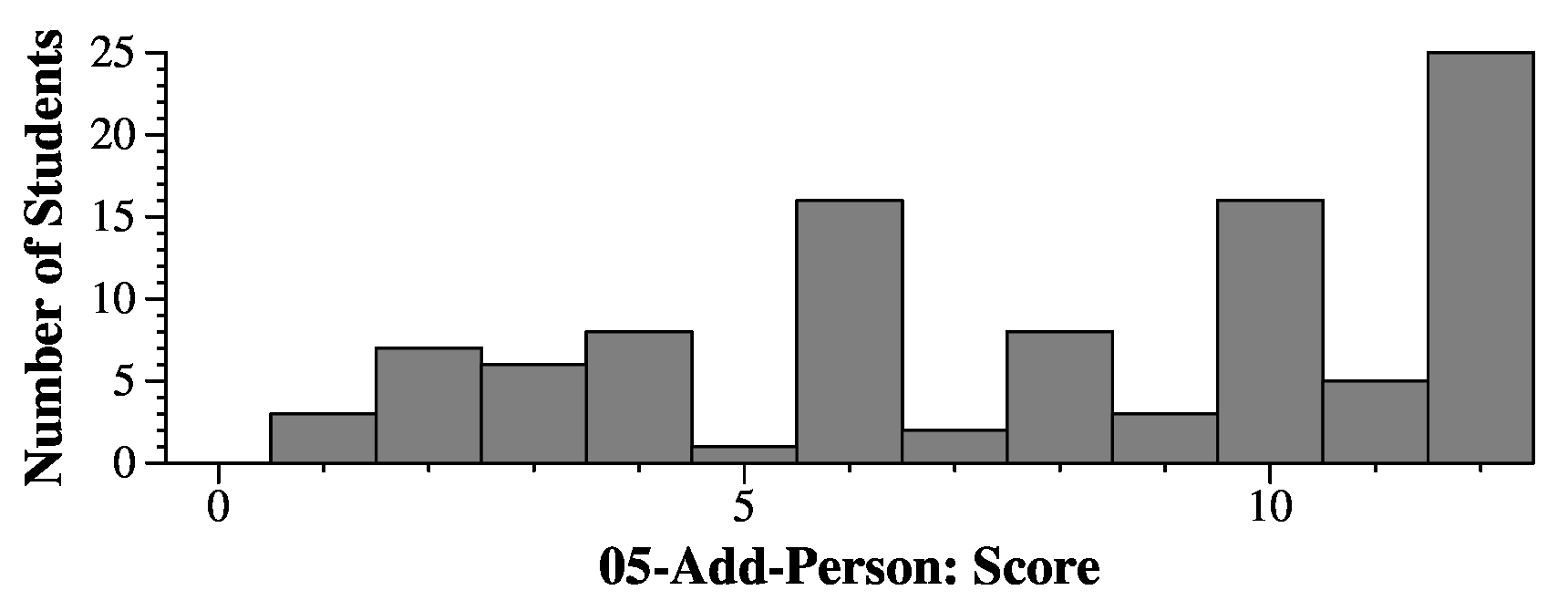 |
void People::print_by_age()
{
multimap <int, Person *> m;
multimap <int, Person *>::iterato mit;
size_t i;
for (i = 0; i < pvec.size(); i++) m.insert(make_pair(pvec[i]->age, pvec[i]));
for (mit = m.begin() mit != m.end() mit++) {
cout << mit->first << " " << mit->second->name << endl;
}
}
|
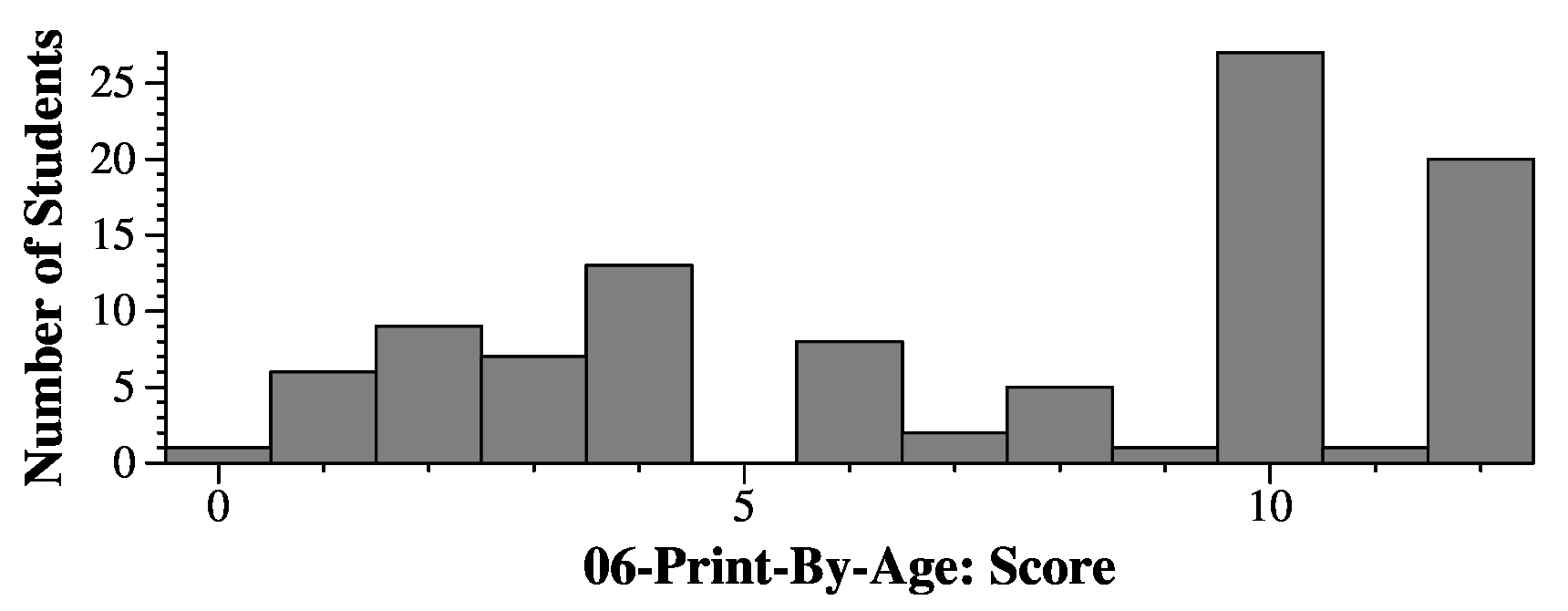 |