Pointers, new and delete
Pointers are typically confusing to students when they first learn them. For better or worse, the standard template library in C++ lets you write some very powerful programs without having to even acknowledge that that pointers exist. However, pointers are fundamental and important. The main reason is that often you want to have a piece of data that is stored by multiple data structures. And you want the data structures to reference the same piece of data instead of each data structure having its own copy. This is why pointers are important.You declare that a variable is a pointer to a data type with the asterisk. For example, if I want the variable ip to point to an integer, I declare it as:
int *ip; |
The pointer itself is a four or eight byte piece of data. For now, think of that data as being an arrow that points to other data. In the above code, it points to an integer.
You can set a pointer's value by having it point to a piece of data that already exists. You do that using the ampersand. When you want to reference what a pointer points to, you use the asterisk. For example, the program src/pointer_mess_1.cpp has the pointer ip point to the integer i, and then does some setting and printing of that integer:
/* A program to demonstrate single pointer that points to an integer. */
#include <cstdio>
using namespace std;
int main()
{
int i; // Declare an integer i
int *ip1; // and a pointer to an integer, named ip1.
ip1 = &i; // Set ip1 to point to i.
/* When we change i, we can access that change either from i itself,
or by "dereferencing" ip1 using the asterisk. */
i = 5;
printf("i: %2d *ip1: %2d\n", i, *ip1);
/* When we change *ip1, you see the change reflected in both i and *ip1. */
*ip1 = 10;
printf("i: %2d *ip1: %2d\n", i, *ip1);
/* This is like the first statement - changine i is reflected in both i and *ip1. */
i = 15;
printf("i: %2d *ip1: %2d\n", i, *ip1);
return 0;
}
|
When we run it, we see the following output:
UNIX> make bin/pointer_mess_1 g++ -std=c++98 -Wall -Wextra -Iinclude -o bin/pointer_mess_1 src/pointer_mess_1.cpp UNIX> bin/pointer_mess_1 i: 5 *ip1: 5 i: 10 *ip1: 10 i: 15 *ip1: 15 UNIX>I'll try to illustrate this with pictures below. When you first declare i and ip, that allocates space for them. Setting ip to be &i has ip "point" to i. Then, when you set i or *ip, it sets the integer stored in i. For that reason, printing i or *ip prints the same value:
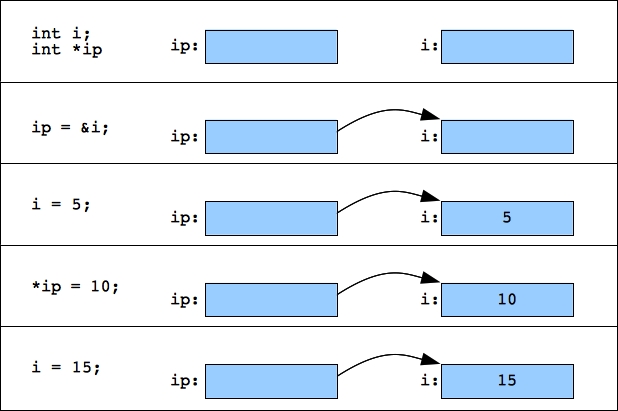 |
The program src/pointer_mess_2.cpp is a little more complex:
#include <cstdio>
using namespace std;
int main()
{
int i;
int *ip1, *ip2;
/* This is like the previous program -- we set ip1 to point to i, and then after we
set i's value to 5, you see that reflected in both i, and *ip1. */
ip1 = &i;
i = 5;
printf("i: %2d *ip1: %2d\n", i, *ip1);
/* By saying "new int", we have allocated new memory for ip1. It now points to
this new memory, and no longer to i. For this reason, i's value remains 5, while
*ip1 has been set to ten. */
ip1 = new int;
*ip1 = 10;
printf("i: %2d *ip1: %2d\n", i, *ip1);
/* We have allocated another integer and set ip1 to point to it. We have "lost"
the memory from the first "new" statement, because we don't have any pointer
to it. This is known as a "memory leak." */
ip1 = new int;
*ip1 = 15;
printf("i: %2d *ip1: %2d\n", i, *ip1);
/* We set ip2 equal to ip1. That means they both point to the same integer, so when
you set *ip2 to 20, that will be reflected in both *ip1 and *ip2. You'll note that
all this time, i has been unaffected, with its value remaining as 5. */
ip2 = ip1;
*ip2 = 20;
printf("i: %2d *ip1: %2d *ip2: %2d\n", i, *ip1, *ip2);
/* We allocate still another integer for ip1. Since ip2 points to where ip1 was, this
is not a memory leak. At this point, i, *ip1 and *ip2 are all different values. */
ip1 = new int;
*ip1 = 25;
printf("i: %2d *ip1: %2d *ip2: %2d\n", i, *ip1, *ip2);
/* This deallocates the memory for ip1, so that it can be used for a new "new" call.
You'll note that you can still print it out (or worse yet, set it). That's because
the memory doesn't go away; it is simply not allocated. This is a memory bug, the
worst of all bugs to find and fix. */
delete ip1;
printf("i: %2d *ip1: %2d *ip2: %2d\n", i, *ip1, *ip2);
return 0;
}
|
This program has two pointers, ip1 and ip2. The first statements are the same as the previous program -- ip is set to be &i and then i is set to five:
 |
In the next set of statements, we call new. This creates a new integer and has ip1 point to it. This is called "allocating memory." This memory is guaranteed to exist until either the program ends, or you explicitly call delete on the pointer. That makes it different from local variables or procedure parameters which are created when a procedure starts running and is reclaimed when the procedure ends. Here's a picture -- you should see why the printf() statement prints out i as 5, and *ip1 as 10.
 |
In the next set of statements, we call new again and get the following picture:
 |
Printing out i and *ip1 yields 5 and 15. However, you'll note that the integer that holds 10 has nothing pointing to it. This is called a memory leak, because that memory will not be deallocated until the program ends, and no part of the program can access it. Memory leaks are things that you want to avoid, especially when you're writing programs that will run for a long time (like a web browser or editor).
The next statements have ip2 equal ip1. In other words, they point to the same integer. Thus, when you change *ip2 to 20, then both *ip2 and *ip1 equal 20:
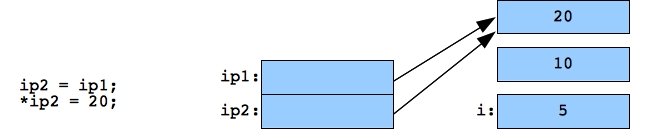 |
Now we call new again, so that ip1 and ip2 point to different integers. This is not a memory leak, because we can still access ip2. Printing i, *ip1 and *ip2 all print different values.
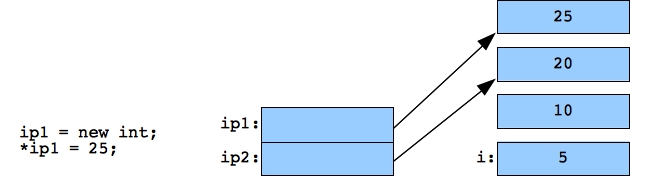 |
Finally, I call delete ip1. This releases the integer so that the memory can be reused by subsequent new calls. You'll note that I still print out *ip1 -- the results of this may differ from machine to machine. It might print out the old value because the memory hasn't been reused, or something else might happen. This is a source of bugs that are extremely difficult to track, and the compiler usually won't help. This is another reason why students hate pointers -- they can get you into trouble. Regardless, you need to learn and understand them.
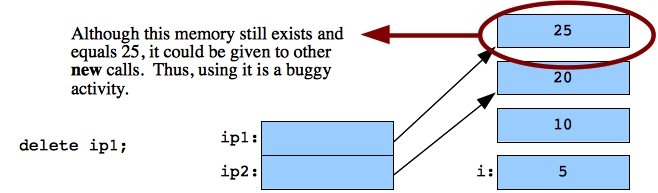 |
Here's the output:
UNIX> make bin/pointer_mess_2 g++ -std=c++98 -Wall -Wextra -Iinclude -o bin/pointer_mess_2 src/pointer_mess_2.cpp UNIX> bin/pointer_mess_2 i: 5 *ip1: 5 i: 5 *ip1: 10 i: 5 *ip1: 15 i: 5 *ip1: 20 *ip2: 20 i: 5 *ip1: 25 *ip2: 20 i: 5 *ip1: 25 *ip2: 20 # This value may differ. I've seen 0 and 1613348896 recently (2023). UNIX>
You can point to vectors
The program src/vector_pointers.cpp is more complex. Instead of having pointers to integers, this one deals with pointers to vectors. You can read the comments if you want, but I will also walk through the example with pictures after the code.
/* This is a program that mixes pointers and vectors. */
#include <vector>
#include <string>
#include <iostream>
#include <cstdio>
#include <cstdlib>
using namespace std;
class VP {
public:
vector <int> vec;
};
int main()
{
vector <int> iv; // Vector of integers
vector <int> *ivp; // Pointers to vector of integers
VP *vp; // Pointer to an instance of the VP class.
size_t i;
/* Set iv to be the first 10 multiples of 11, and print them out. */
for (i = 0; i < 10; i++) iv.push_back(11*i);
cout << endl << "Here is a vector of integers called iv:" << endl << endl;
for (i = 0; i < iv.size(); i++) printf("%2d ", iv[i]);
printf("\n");
/* Set ivp to point to iv -- as you can see, it prints out the same vector.
I like to use that at method here, because it looks I think, better than (*ivp)[i]. */
cout << endl << "Setting ivp to point to iv and printing it:" << endl << endl;
ivp = &iv;
for (i = 0; i < ivp->size(); i++) printf("%2d ", ivp->at(i));
printf("\n");
/* Resizing ivp also resizes iv -- because they are the same vector. */
cout << endl << "Resizing ivp is reflected by iv being resized." << endl << endl;
ivp->resize(4);
printf("iv: ");
for (i = 0; i < iv.size(); i++) printf("%2d ", iv[i]);
printf("\n");
printf("ivp: ");
for (i = 0; i < ivp->size(); i++) printf("%2d ", ivp->at(i));
printf("\n");
/* Changing an element of ivp changes that element in iv -- because they are the same vector. */
cout << endl << "Setting ivp->at(2) to 2." << endl << endl;
ivp->at(2) = 2;
printf("iv: ");
for (i = 0; i < iv.size(); i++) printf("%2d ", iv[i]);
printf("\n");
printf("ivp: ");
for (i = 0; i < ivp->size(); i++) printf("%2d ", ivp->at(i));
printf("\n");
/* I use new to allocate an instance of the VP class.
I use an arrow to get at vp's member variable. However, since that member
variable is a vector, and not a pointer to a vector, you access its methods
with "." and its elements with "[]": */
cout << endl << "This code demonstrates a pointer to a class whose member variable is a vector."
<< endl << endl;
vp = new VP;
for (i = 0; i < 10; i++) vp->vec.push_back(9*i);
for (i = 0; i < vp->vec.size(); i++) printf("%2d ", vp->vec[i]);
printf("\n");
return 0;
}
|
I'll illustrate again. First, we set iv to be a vector of the first 10 multiples of 11. Then we set ivp to point to iv and we print it out. I use the at() method instead of square brackets just because it looks better. Instead of ivp->at(i), I could have done (*ip)[i], but I don't like how that looks.
When you have a pointer p, then doing p->x is equivalent to doing (*p).x. It's easier to read.
Here is a vector of integers called iv: 0 11 22 33 44 55 66 77 88 99 Setting ivp to point to iv and printing it: 0 11 22 33 44 55 66 77 88 99  |
Next, I call ivp->resize(4). As you can see, that resizes the vector to which ivp points, which ends up resizing iv:
Resizing ivp is reflected by iv being resized. iv: 0 11 22 33 ivp: 0 11 22 33  |
And we set ivp->at(2) to 2, which again is reflected in iv and ivp, since they use the same vector:
Setting ivp->at(2) to 2. iv: 0 11 2 33 ivp: 0 11 2 33  |
The final piece of code involving vp shows how I like to handle pointers to vectors. I usually like to bundle them up in a class or struct, so that I don't have to use at() and it still looks nice.
This code demonstrates a pointer to a class whose member variable is a vector. 0 9 18 27 36 45 54 63 72 81  |
Another example of pointers and vectors
Here's another example for you to try (in src/another_example.cpp). See if you can tell me the five lines of output:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
vector <int *> v1;
vector <int *> v2;
vector <int> v3;
vector <int> *v4;
vector <int *> *v5;
size_t i;
for (i = 0; i < 5; i++) {
v1.push_back(new int);
*v1[i] = i*10;
}
for (i = 0; i < 5; i++) v2.push_back(v1[5-i-1]);
for (i = 0; i < 5; i++) v3.push_back(*v1[i]);
v4 = &v3;
v5 = &v1;
for (i = 0; i < 5; i++) *v1[i] += 5;
v3[2] += 8;
*(v5->at(2)) += 50;
cout << "V1"; for (i = 0; i < 5; i++) cout << " " << *v1[i]; cout << endl;
cout << "V2"; for (i = 0; i < 5; i++) cout << " " << *v2[i]; cout << endl;
cout << "V3"; for (i = 0; i < 5; i++) cout << " " << v3[i]; cout << endl;
cout << "V4"; for (i = 0; i < 5; i++) cout << " " << (*v4)[i]; cout << endl;
cout << "V5"; for (i = 0; i < 5; i++) cout << " " << *((*v5)[i]); cout << endl;
return 0;
}
|
Let's work through it together. v1 is a vector of pointers to integers. We add five pointers to it in the for loop. Each pointer points to a separate integer, created with new. Here's the code, and what v1 looks like:
for (i = 0; i < 5; i++) {
v1.push_back(new int);
*v1[i] = i*10;
}
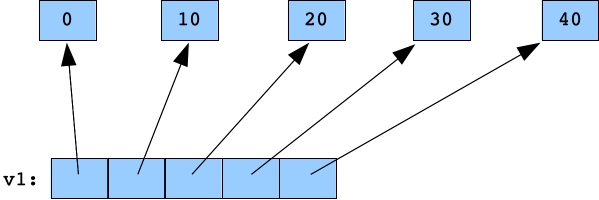 |
The vector v2 is also a vector of pointers to integers. The next for loop sets it to be the pointers of v1, but in reverse:
for (i = 0; i < 5; i++) v2.push_back(v1[5-i-1]); 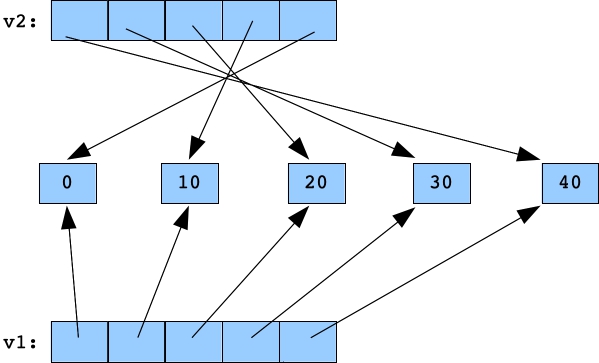 |
The vector v3 is a vector of integers -- no pointers at all. The next for loop sets element i to be *v1[i].
for (i = 0; i < 5; i++) v3.push_back(*v1[i]); 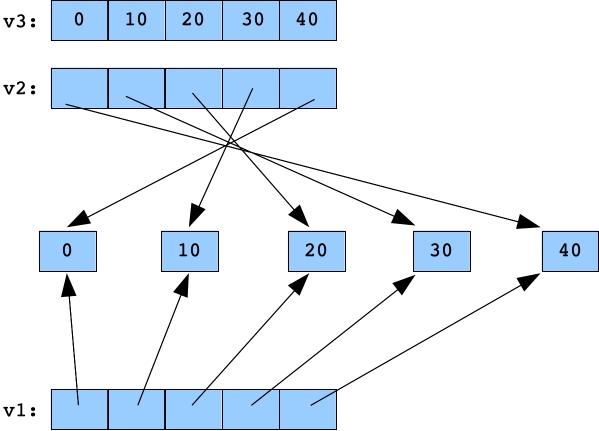 |
v4 is a pointer to a vector of integers. We set it to point to v3. And v5 is a pointer to a vector of pointers to integers. We set it to point to v1:
v4 = &v3; v5 = &v1; 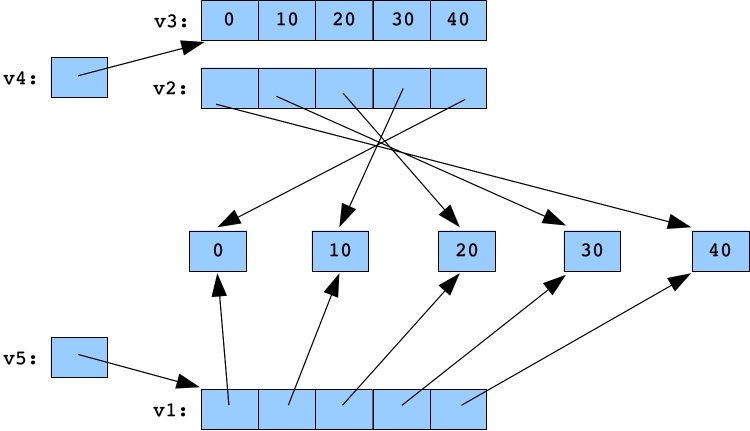 |
The next three lines make some changes. Five is added to every integer pointed to by v1; Eight is added to v3[2], and 50 is added to *(v5->at(2)) += 50. Here's the final picture before we print things out:
for (i = 0; i < 5; i++) *v1[i] += 5; v3[2] += 8; *(v5->at(2)) += 50; 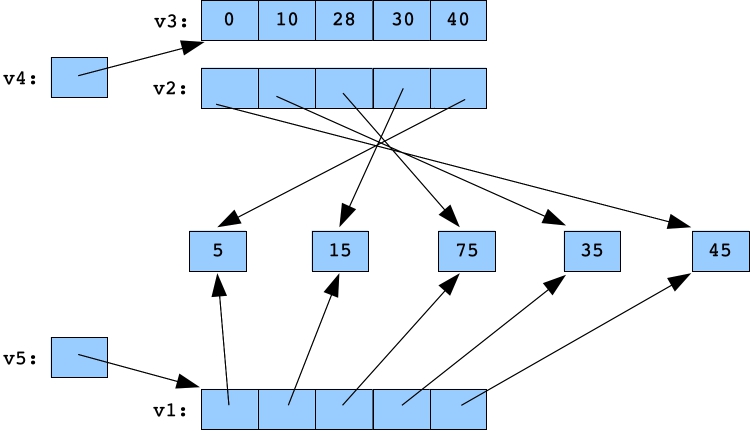 |
Armed with this knowledge, we can now predict the output:
UNIX> bin/another_example V1 5 15 75 35 45 V2 45 35 75 15 5 V3 0 10 28 30 40 V4 0 10 28 30 40 V5 5 15 75 35 45 UNIX>Make sure you understand this program and its output. Work through it as many times as it takes.
NULL and nullptr
NULL is a value to which you can set any pointer. You use it when you want to represent the fact that the pointer isn't pointing to anything. If you try to dereference a pointer whose value is NULL, you'll get a segmentation violation. That is a good thing, because it helps you find bugs. You can also test to see if a pointer is NULL, to make sure it's pointing to something.There is a second value, nullptr, which was introduced in C++11. To me, it's reminiscent of size_t, which was introduced for a good reason academically, but pragmatically it's kind of a nightmare. I'm not going to bore you with reasons why nullptr makes sense and NULL doesn't. In 99.99 percent of situations, they both work fine, so long as you remain consistent and don't try to intermix them. I tend to use NULL because I'm old, and it works identically in C and C++. However, you should be mentally ready to see and use nullptr, because others (e.g. Leetcode) will use it.
Data Structures that Share Data using Pointers
Your friend Zark Muckerberg comes to you, saying he's got an idea for an app that will replace Facebook. It's called ``Bacefook'', and it's going to be a huge hit and he's going to make a ton of money with it and he's going to buy a great car and expensive clothes with the money and he'll start making friends with movie stars and pro athletes and his life will be AWESOME!!!! You're going to get some of that money too, because you're going to help him write the app.The way that many apps work is diagrammed below:
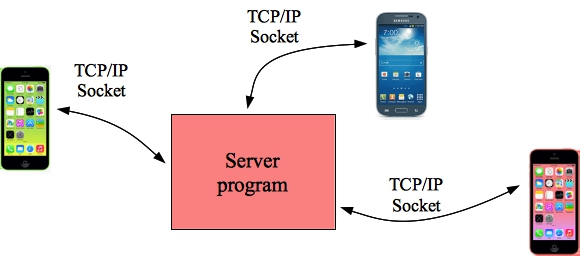 |
The app runs on people's phones, and then each app talks with a central server across the Internet (or via a cellular network) using a networking mechanism like TCP/IP sockets. You'll learn how to do that in CS360. The server contains all of the data that gets shared among the apps. When one app updates information, it is updated at the server so that the other apps may have access to it. It's a nice and simple way of getting everything to work.
The apps are written on the platform of the phone (e.g. IOS or Android). The server, though, is often a C++ program running on a Unix platform. Now, Zark is going to write the apps, and he wants you to write the server.
To start with, Bacefook is going to manage people, who have just four attributes:
- A name, which can be composed of any number of words.
- A mood, which can also be composed of any number of words. If a person's mood is unspecified, then it is "Neutral."
- Another person with whom they are in a relationship. This attribute doesn't have to be set, and it doesn't have be reciprocated.
- A list of friends.
You'd be surprised at how unsexy a server is -- very often, they read lines of text from their sockets, and write lines of text back to the sockets. And they store data in data structures that you'll learn about in this class.
What we're going to do is write a very primitive server for Zark's app. Instead of using TCP/IP sockets, it's going to read from standard input and write to standard output. We're just going to pretend that standard input comes from cell phones, and standard output goes to cell phones. Again, you'd be surprised at how close to reality this can be.
Our server is going to read lines of text. It will read a "key," and then more information in subsequent lines. Here are the keys that it processes:
- "NP" -- This must be followed by a line that contains the person's name.
The name can have any number of words.
This adds the new person to our server's database.
If that is successful, it will print "SUCCESSFUL" on standard output. If unsuccessful
(the person is in the database already), then it will print "UNSUCCESSFUL".
- "M" -- This is followed by two lines. The first contains a person's name, and
the second contains their mood. The server finds the person and updates his or her mood.
The server responds either "SUCCESSFUL" or "UNSUCCESSFUL".
- "R" -- This is followed by two lines, which are the names of two people
in the database. It registers the fact that the first person is in a relationship with the
second person.
Again, it will return "SUCCESSFUL" or "UNSUCCESSFUL".
- "F" -- This is identical to "R," except it adds the second person
to the first person's friend list.
- "Q" -- This is followed by a line of text, which is the name of a person.
The output will be either "UNSUCCESSFUL", or the following lines of text:
- "Q SUCCESSFUL"
- "NAME Name-or-person"
- "MOOD Mood"
- "RELATIONSHIP Name : Mood". It only prints this line if the person is in a relationship. The mood is the mood of the other person.
- "FRIEND Name : Mood" -- there is one of these for each friend.
- "END" - This makes it easy for Zark's program to know when the list of friends is over.
- "PHT" -- This prints the hash table, and is useful for debugging.
bacefook_server.cpp
Let's write this one together. The code is in bacefook_server.cpp, and it's pretty straightforward. The parts that I want you to pay attention to are the pointers.The two main data structures: A person, and the hash table
Each person is represented with an instance of the Person class, defined below:
class Person {
public:
string Name;
string Mood;
Person *InRelationship;
vector <Person *> Friends;
};
|
You'll note that InRelationship is a pointer to a person, and Friends is a vector of pointers to people. That allows you to access each person's data directly, and when it changes, you'll see the changes.
In reality, our "database" is a hash table that is accessed by names. We'll use djbhash as the hash function, and separate chaining to resolve collisions. Each vector in the hash table will hold pointers to instances of a Person class. When we first insert a person into the hash table, that's when we create the instance using new.
Take a look at the function find_person(). It takes a name and a hash table, and finds the person with that name in the hash table. If the person is there, it returns a pointer to the person. If the person is not there, then it looks at the add parameter. If that parameter is true, it creates a new person (with new), and inserts it into the hash table. The person's Mood is "Neutral", and its InRelationship pointer is set to NULL. That is a special pointer value that points to "nothing." If you try to dereference NULL, you'll get a segmentation violation. The person's friend list is empty automatically. The person is returned.
If add is false, then find_person() simply returns NULL.
// This is our one and only hash table function. It finds a person with the
// given name in the hash table. If the person is found, then it returns a
// pointer to the person. Otherwise, if "add" is true, it creates the person
// and adds it to the hash table. If "add" is false, then it simpy returns NULL.
Person *find_person(const string &name, vector < vector <Person*> > &HT, bool add)
{
int h;
size_t i;
Person *p;
// Look up the person in the hash table.
h = djb_hash(name) % HT.size();
for (i = 0; i < HT[h].size(); i++) {
if (HT[h][i]->Name == name) return HT[h][i];
}
// If we're here in the code, we didn't find the person in the hash table.
if (add) {
p = new Person;
p->Name = name;
p->Mood = "Neutral";
p->InRelationship = NULL;
HT[h].push_back(p);
return p;
} else {
return NULL;
}
}
|
The basics of main()
The main() routine takes the size of the hash table on the command line. Then it sets up the hash table, and goes into an infinite loop reading lines of text from standard input:
int main(int argc, char **argv)
{
istringstream iss; // For processing argv[1]
string n1, n2, mood; // For reading in names and moods
Person *p, *p2; // Pointers to people, that we manipulate or print.
int Table_Size; // The table size is read from the command line.
vector < vector <Person*> > Hash_Table; // The hash table.
// Entries are vectors because we use separate chaining
size_t i; // Temporary variable
string s; // Temporary variable
// --------------------------------------------------
// Process the command line and create the hash table.
try {
if (argc != 2) throw((string) "usage: bacefook_server table-size");
iss.clear();
iss.str(argv[1]);
if (!(iss >> Table_Size) || Table_Size <= 0) throw ("bad table-size");
} catch (const string s) {
cerr << s << endl;
exit(1);
}
Hash_Table.resize(Table_Size);
// --------------------------------------------------
// Process the input from standard input.
while (getline(cin, s)) {
|
Now we process standard input. Let's start with "NP". You'll note, when standard input ends, we simply exit the program. When we read the person's name, we call find_person() to look the person up in the hash table. We set add to false, so that if the person is not there, find_person() returns NULL, and we can print "UNSUCCESSFUL." Otherwise, we call find_person() with add set to true to create the person and put him/her into the table:
// --------------------------------------------------------
// NP. If the person is already in the hash table,
// then it is an error.
if (s == "NP") {
if (!getline(cin, n1)) exit(1);
p = find_person(n1, Hash_Table, false);
if (p != NULL) {
printf("UNSUCCESSFUL\n");
} else {
p = find_person(n1, Hash_Table, true);
printf("SUCCESSFUL\n");
}
|
Let's test what we've done so far. At the very least, we should be able to add people to the hash table, and if we try to add the same person twice, we'll be unsuccessful.
UNIX> bin/bacefook_server 100 NP Scarlett O'Hara SUCCESSFUL NP Rhett Butler SUCCESSFUL NP Rhett Butler UNSUCCESSFUL <CNTL-D> UNIX>Let's set moods. This is straightforward. To test it, let's write the part of "Q" that prints out the name and mood:
// --------------------------------------------------------
// M. Find the name and set the mood.
} else if (s == "M") {
if (!getline(cin, n1)) exit(1);
if (!getline(cin, mood)) exit(1);
p = find_person(n1, Hash_Table, false);
if (p == NULL) {
printf("UNSUCCESSFUL\n");
} else {
p->Mood = mood;
printf("SUCCESSFUL\n");
}
} else if (s == "Q") {
if (!getline(cin, n1)) exit(1);
p = find_person(n1, Hash_Table, false);
if (p == NULL) {
printf("UNSUCCESSFUL\n");
} else {
printf("SUCCESSFUL\n");
printf("NAME %s\n", p->Name.c_str());
printf("MOOD %s\n", p->Mood.c_str());
printf("END\n");
}
|
Here we'll change Scarlett's mood:
UNIX> bin/bacefook_server 100 NP Scarlett O'Hara SUCCESSFUL Q Scarlett O'Hara SUCCESSFUL NAME Scarlett O'Hara MOOD Neutral END M Scarlett O'Hara Impetuous SUCCESSFUL Q Scarlett O'Hara SUCCESSFUL NAME Scarlett O'Hara MOOD Impetuous END <CNTL-D> UNIX>Alright -- time for "R". Here, we get pointers to the two people, and we set p->InRelationship to p2. This is where it is important to have a pointer. If we didn't use pointers in the hash table, and if p->InRelationship were a Person instead of a pointer to a Person, then setting p->InRelationship would make a copy of whatever is in the hash table.
Here's the code.
// ---------------------------------------------------------------
// R. Now, you have to successfully find both
// names. Note how we set the pointer of p->InRelationship to p2.
} else if (s == "R") {
if (!getline(cin, n1)) exit(1);
if (!getline(cin, n2)) exit(1);
p = find_person(n1, Hash_Table, false);
p2 = find_person(n2, Hash_Table, false);
if (p == NULL || p2 == NULL) {
printf("UNSUCCESSFUL\n");
} else {
p->InRelationship = p2;
printf("SUCCESSFUL\n");
}
|
And here's the relevant line of "Q" -- note how we test p->InRelationship to make sure that we only print out the relationship when it has been explicitly set:
if (p->InRelationship != NULL) {
printf("RELATIONSHIP %s : %s\n", p->InRelationship->Name.c_str(),
p->InRelationship->Mood.c_str());
}
|
To test this, let's change Scarlett's mood after Rhett has set his InRelationship. Because we are using pointers, you see the mood change when you query Rhett:
UNIX> bin/bacefook_server 100 NP Scarlett O'Hara SUCCESSFUL NP Rhett Butler SUCCESSFUL R Rhett Butler Scarlett O'Hara SUCCESSFUL Q Rhett Butler SUCCESSFUL NAME Rhett Butler MOOD Neutral RELATIONSHIP Scarlett O'Hara : Neutral END M Scarlett O'Hara Impetuous SUCCESSFUL Q Rhett Butler SUCCESSFUL NAME Rhett Butler MOOD Neutral RELATIONSHIP Scarlett O'Hara : Impetuous END <CNTL-D> UNIX>Finally, let's add friends. The code for this is very similar to "R":
// ---------------------------------------------------------------
// F. This is pretty much identical to R,
// except you are adding p2 to the Friends vector, rather than just
// setting a pointer.
} else if (s == "F") {
if (!getline(cin, n1)) exit(1);
if (!getline(cin, n2)) exit(1);
p = find_person(n1, Hash_Table, false);
p2 = find_person(n2, Hash_Table, false);
if (p == NULL || p2 == NULL) {
printf("UNSUCCESSFUL\n");
} else {
p->Friends.push_back(p2);
printf("SUCCESSFUL\n");
}
|
And here's the code to print out friends in "Q":
for (i = 0; i < p->Friends.size(); i++) {
printf("FRIEND %s : %s\n", p->Friends[i]->Name.c_str(),
p->Friends[i]->Mood.c_str());
|
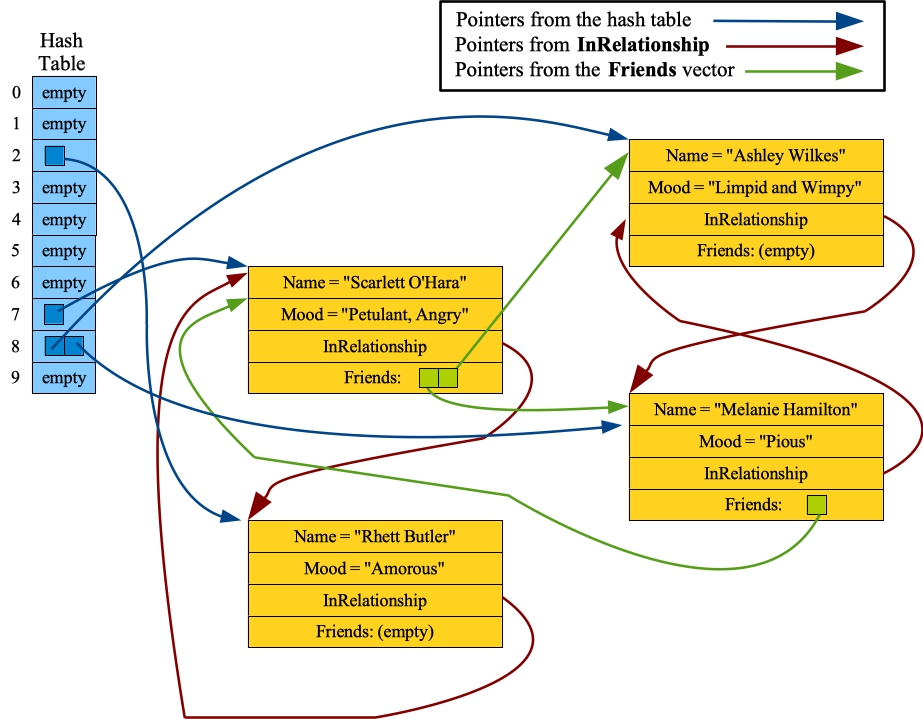
Let's test this. I'm going to do a moderate-sized example of Margaret Mitchell's famous love triangle from Gone With The Wind. Afterwards, we're going to take a very detailed look at how memory and the various data structures are laid out. I'm using a small hash table, because I want to be able to look at everything in my pictures.
Go ahead and cut-and-paste the following into bacefook_server 10 (it's in the file files/gwtw-1.txt, but you can also just copy-paste from below):
NP Scarlett O'Hara NP Rhett Butler NP Ashley Wilkes NP Melanie Hamilton | F Scarlett O'Hara Melanie Hamilton F Scarlett O'Hara Ashley Wilkes F Melanie Hamilton Scarlett O'Hara | R Rhett Butler Scarlett O'Hara R Scarlett O'Hara Rhett Butler R Ashley Wilkes Melanie Hamilton R Melanie Hamilton Ashley Wilkes | M Rhett Butler Amorous M Scarlett O'Hara Petulant, Angry M Ashley Wilkes Limpid and Wimpy M Melanie Hamilton Pious |
If we do some queries on this state, we see all of those inter-relationships:
Q Scarlett O'Hara SUCCESSFUL NAME Scarlett O'Hara MOOD Petulant, Angry RELATIONSHIP Rhett Butler : Amorous FRIEND Melanie Hamilton : Pious FRIEND Ashley Wilkes : Limpid and Wimpy END Q Rhett Butler SUCCESSFUL NAME Rhett Butler MOOD Amorous RELATIONSHIP Scarlett O'Hara : Petulant, Angry END Q Ashley Wilkes SUCCESSFUL NAME Ashley Wilkes MOOD Limpid and Wimpy RELATIONSHIP Melanie Hamilton : Pious END Q Melanie Hamilton SUCCESSFUL NAME Melanie Hamilton MOOD Pious RELATIONSHIP Ashley Wilkes : Limpid and Wimpy FRIEND Scarlett O'Hara : Petulant, Angry END |
Now, suppose we want to see how all of these structures look in memory. First, open another window and run djbhash from the hashing lecture notes:
UNIX> bin/djbhash Scarlett O'Hara 1585424537 Rhett Butler 3831887322 Ashley Wilkes 2242265818 Melanie Hamilton 1839425308 <CNTL-D> UNIX>That means that "Scarlett O'Hara" goes into hash table entry 7, "Rhett Butler" goes into hash table entry 2, and both "Ashley Wilkes" and "Melanie Hamilton" go into hash table entry 8. Armed with that knowledge, take a look at the hash table, the four Person class instances, and all of their pointers. There are three places where pointers are used:
- From the hash table
- From InRelationship
- From the Friends vectors
 |
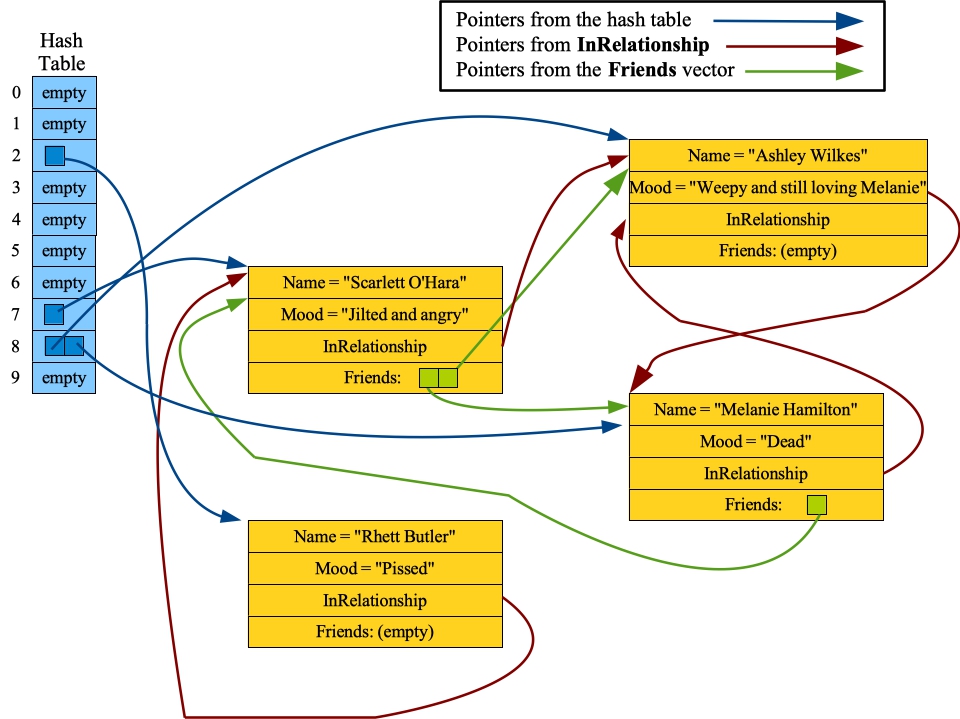
Now, let's go back to the bacefook_server program, and change some things. We'll reflect what happens at the end of "Gone with the Wind" -- Melanie dies, Scarlett professes her love to Ashley, Ashley dissolves into a weepy mess while he pronounces his everlasting love for Melanie, thus angering the jilted Scarlett. And Rhett gets pissed:
M Melanie Hamilton Dead R Scarlett O'Hara Ashley Wilkes M Ashley Wilkes Weepy and still loving Melanie M Scarlett O'Hara Jilted and angry M Rhett Butler PissedIf you query them, you'll see all of those changes reflected. Here's what the data structures look like now. Again, you should double-check them.
 |
Summary
- A pointer is a special data type which provides a level of indirection.
It "points" to memory, which may be shared with some other variables, or may be the exclusive
purview of the pointer.
- You can set a pointer to point to another variable by putting an ampersand in front
of the variable.
- You "dereference" a pointer by putting an asterisk in front of it. That allows you to access
or set what the pointer is pointing to.
- If a pointer p is to an instance of a class,
then you can get at the methods and variables of
the class with "p->". That is cleaner than doing "(*p).".
- The new command asks for memory, and returns a pointer that points to it.
This memory will last until the program is over, or until delete is called on the pointer.
- A "memory leak," is where you change a pointer, and don't record its old value. If it was
pointing to memory allocated with new, and there's no record of it anywhere, then it
simply wastes space. You want to avoid memory leaks.
- When you call delete, the memory does not go away, but it is marked for reuse by
subsequent new calls. This can cause horrific bugs when you forget that a pointer
has been deleted.
- One main reason why we use pointers is because we have data that we want to access in a variety of ways. The "Bacefook" example shows how we have multiple pointers to People, for example, in the Inrelationship pointer, and the Friends pointers.