 |
#include <iostream>
#include <vector>
using namespace std;
void clear_vector(vector <double> v)
{
int i;
for (i = 0; i < v.size(); i++) v[i] = 0;
}
main()
{
vector <double> a;
a.push_back(1);
clear_vector(a);
cout << a[0] << endl;
}
|
When you run it, it prints one, because clear_vector() doesn't do anything:
UNIX> q1 1 UNIX>To fix this, make v a pointer to a vector:
void clear_vector(vector <double> *v) |
Or worse, make it a reference parameter:
void clear_vector(vector <double> &v) |
|
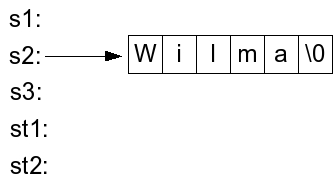 |
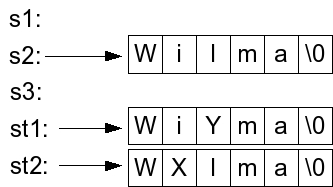
Now, the line "st1 = s2" makes a copy of "Wilma", and the line "st2 = st1" makes another copy of "Wilma". The next two lines set individual characters of each of these copies. Here's the state of the variables:
 |
Now, we set s1 to point to the characters in st1, and we set s3 to point to the second of these characters. The variables are:
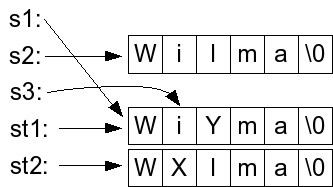 |
It should be clear that the output will be:
UNIX> q2 s1: WiYma s2: Wilma s3: iYma st1: WiYma st2: WXlma UNIX>If you want to test it yourself, the code is in q2.cpp.
 |
 1. Start |
 2. Insert 10 at the end of the array. |
 3. Since (10 < 60), percolate up. |
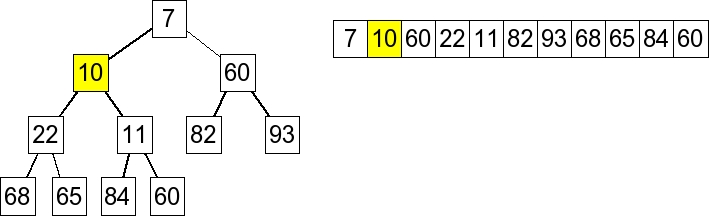 4. Since (10 < 11), percolate up. |
 |
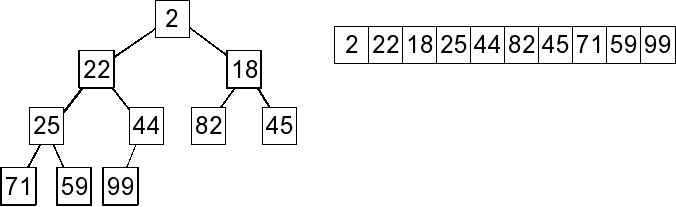 1. Start |
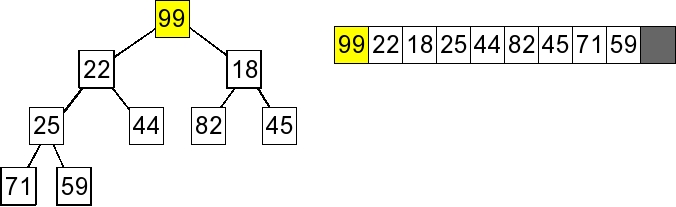 2. Remove the last value and move it to the root. |
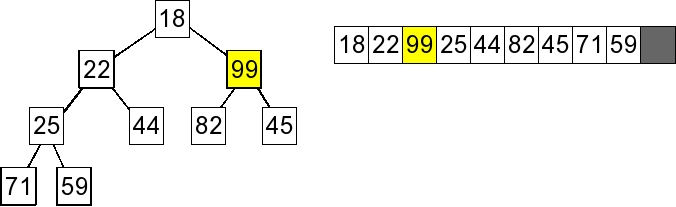 3. Percolate Down: Since 18 is the min child, swap 18 and 99. |
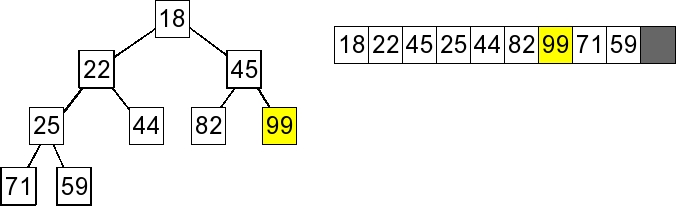 4. Percolate Down: Since 45 is the min child, swap 45 and 99. Since 99 has no children, We're done. |
 |
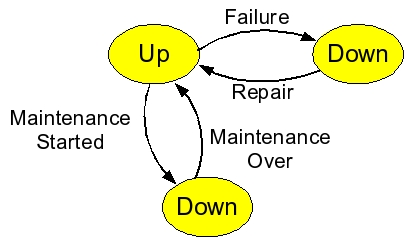 |
When our machines enter the Up state (either in the beginning of the simulation, after repair, or after maintenance), we generate the next Failure event for the future. When we process a Maint_Begin, the next Failure event should be deleted, because maintenance affects where the next failure will occur. In order to delete the next Failure event, we need a pointer to it, and this is what is stored in failure_ptr. This as an iterator into the Event-Queue map, and we can use it to delete.
We set failure_ptr whenever we generate a failure event. In the simulation, this is in three places:
As stated above, we use failure_ptr to delete the next failure event when we begin maintenance.
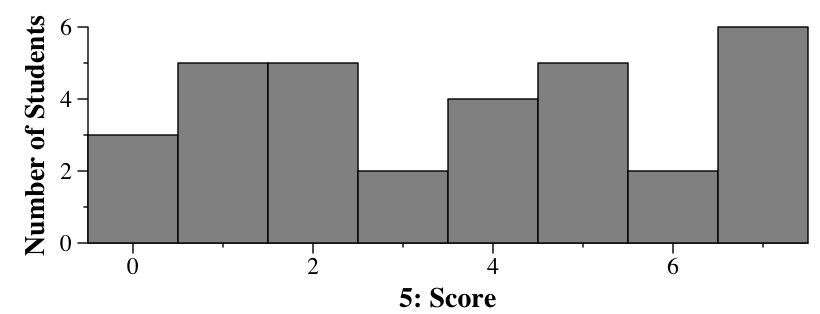 |
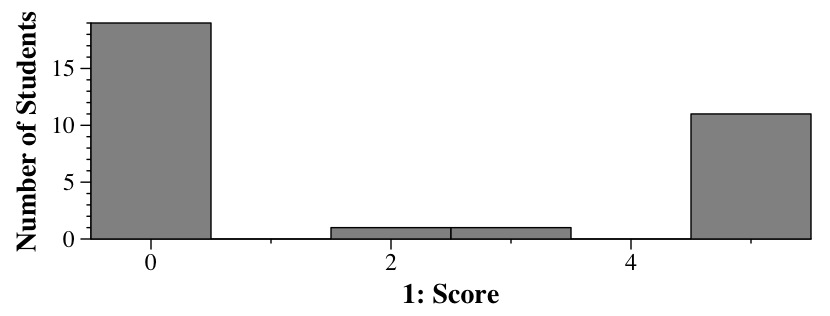
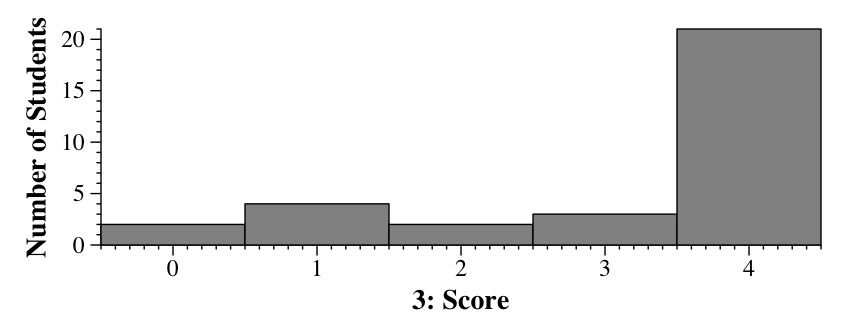
A CDF plot has x on the X-axis and CDF(x) on the Y-axis.
Barney's CDF is invalid because it increases and then decreases as x grows. That makes no sense. For example, CDF(0.15) is around 0.6, and CDF(0.5) is around 0.5. That's impossible -- if the probability of generating a number less than or equal to .15 is 0.6, then the probability of generating a number less than or equal to 0.5 must be at least 0.6.
Betty's CDF is invalid because it contains values greater than 1 on the y axis. Probabilities cannot be greater than one, and since the CDF represents a probability, that graph cannot be a valit CDF graph.
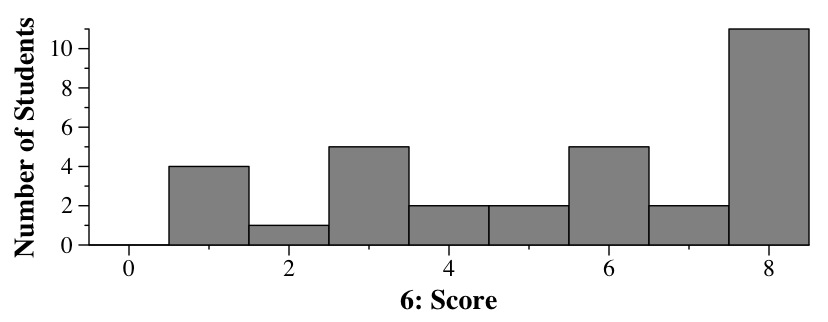 |
I've annotated the graph to show where these come from:
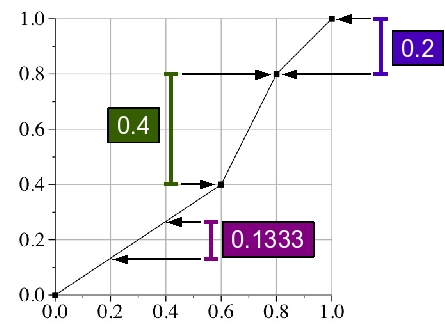 |
Therefore, the most probable one is 0.6 to 0.8.
double cdf_genrand()
{
double tmp;
tmp = drand48();
if (tmp < 0.4) return (tmp * 1.5);
if (tmp < 0.8) return (tmp - 0.4) / 2.0 + 0.6;
return tmp;
}
|
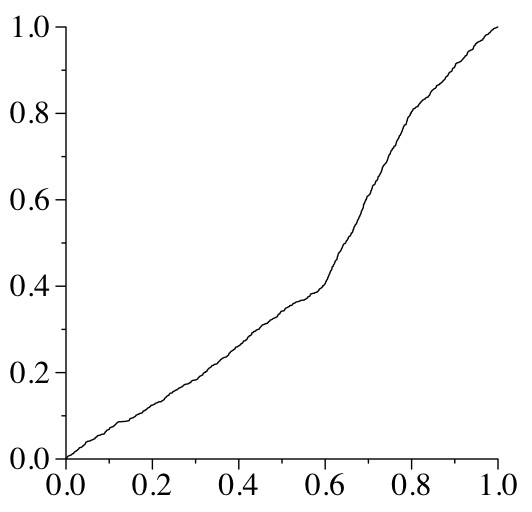
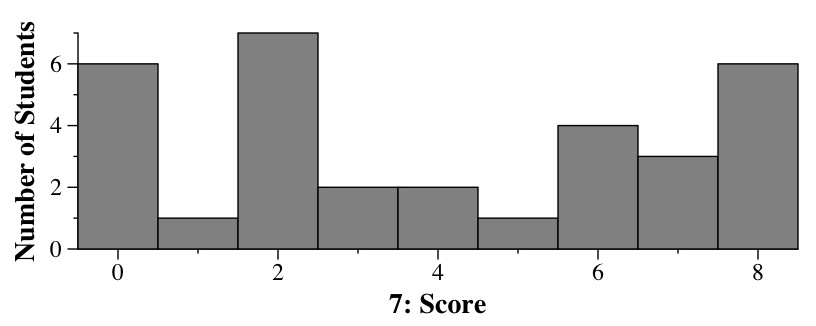
We can double-check ourselves by generating 1000 numbers (this is done in Q7.cpp), and converting them into something that looks like a CDF (as we did in class):
UNIX> Q7 | sort -n | cat -n | awk '{ print $2, $1/1000.0 }' > Q7-out.txt
When we plot Q7-out.txt, it looks like:
 |
In the code, you get 2 points for implementing each part of the CDF correctly. If you made overarching mistakes, they were deducted at the end.
 |
#include <iostream>
#include <string>
#include <map>
using namespace std;
typedef struct {
double total;
double n;
} Data;
main(int argc, char **argv)
{
map <string, Data *> all;
map <string, Data *>::iterator mit;
string tech;
double t;
double avg, bestavg;
Data *d;
// Read in the data, and create the map
while (!cin.fail()) {
cin >> tech >> t;
if (!cin.fail()) {
mit = all.find(tech);
if (mit == all.end()) {
d = new Data;
d->total = 0;
d->n = 0;
all.insert(make_pair(tech, d));
} else {
d = mit->second;
}
d->total += t;
d->n++;
}
}
// Traverse the map, computing the averages, and storing the best
// average in bestavg and the best technique in tech.
for (mit = all.begin(); mit != all.end(); mit++) {
d = mit->second;
avg = d->total / d->n;
if (mit == all.begin() || avg < bestavg) {
bestavg = avg;
tech = mit->first;
}
}
// Print out the best technique
cout << tech << endl;
}
|
 |