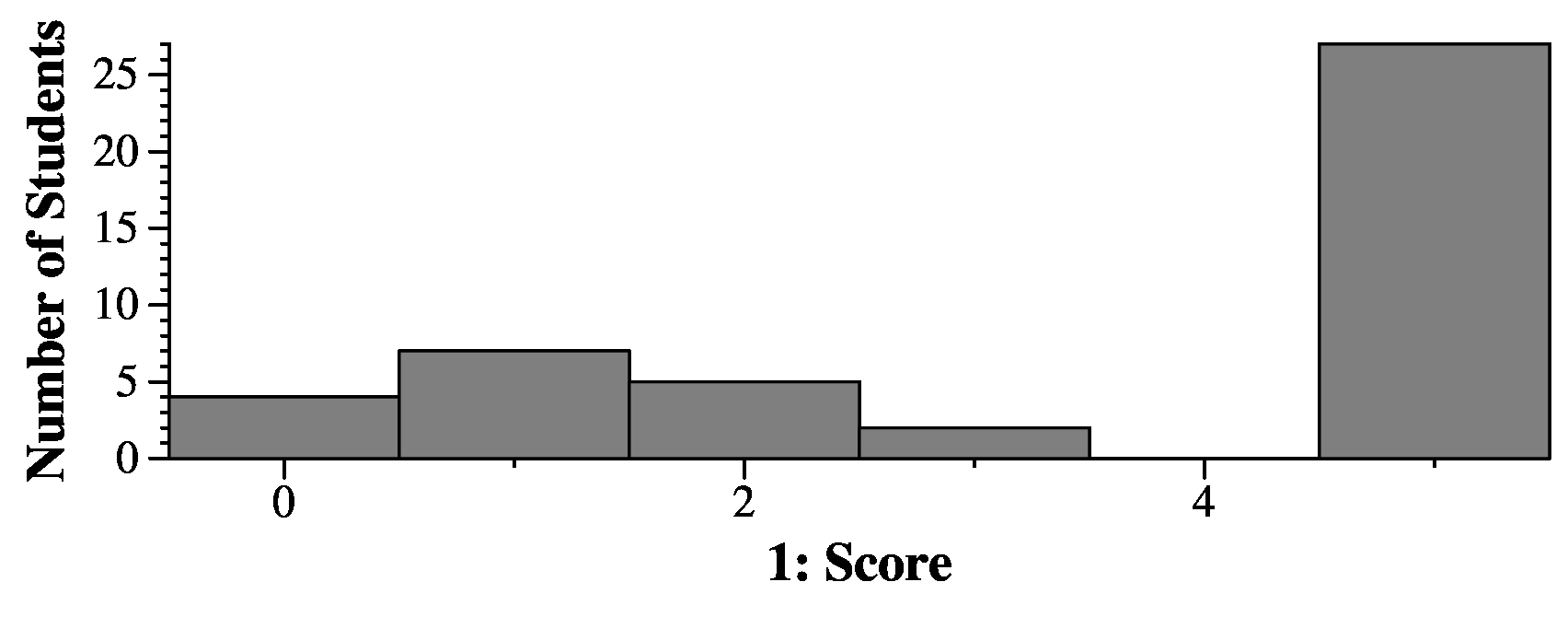
 |
|
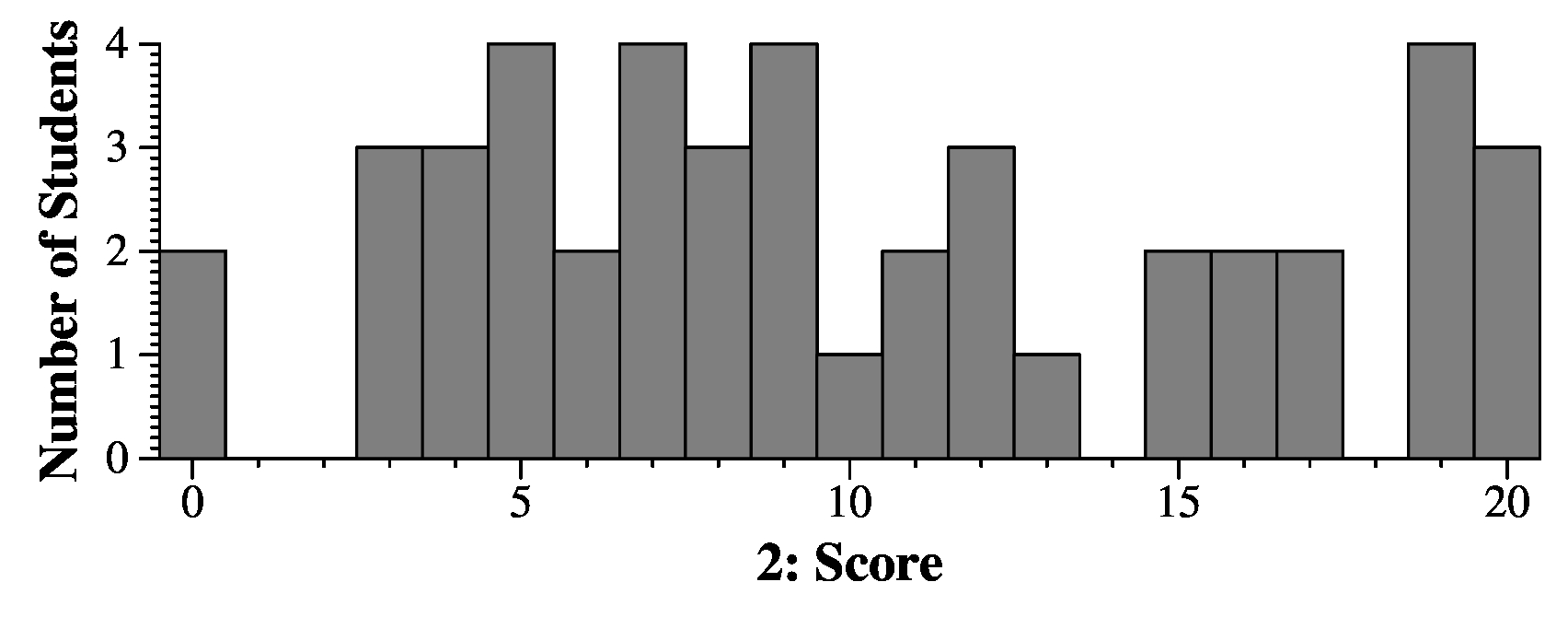 |
/* ndistinct.c from CS360 midterm exam on 3/9/2021. */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <dirent.h>
#include <sys/stat.h>
#include "jrb.h"
/* Since inodes are longs, you need to write your own comparison function. */
int compare(Jval v1, Jval v2)
{
if (v1.l < v2.l) return -1;
if (v1.l > v2.l) return 1;
return 0;
}
/* Use opendir() / readdir() to enumerate files.
Use stat to find each files' inode number.
Store the inodes in a red-black tree so that you can discover duplicates. */
int main()
{
JRB tree; /* The tree. */
DIR *d; /* The open directory. */
struct dirent *de; /* Each file in the directory. */
struct stat buf; /* The file's metadata. */
int ndistinct; /* The number of distinct files. */
/* Do initialization */
tree = make_jrb();
d = opendir(".");
if (d == NULL) { perror("."); exit(1); }
ndistinct = 0;
/* Enumerate the files and look up each inode in the tree.
Only insert an inode if it's not there already. */
for (de = readdir(d); de != NULL; de = readdir(d)) {
if (stat(de->d_name, &buf) != 0) { perror(de->d_name); exit(1); }
if (jrb_find_gen(tree, new_jval_l(buf.st_ino), compare) == NULL) {
ndistinct++;
jrb_insert_gen(tree, new_jval_l(buf.st_ino), new_jval_i(0), compare);
}
}
/* Print the final answer. I don't close the directory or free the tree,
because that is done automatically when the program ends. */
printf("%d\n", ndistinct);
return 0;
}
|
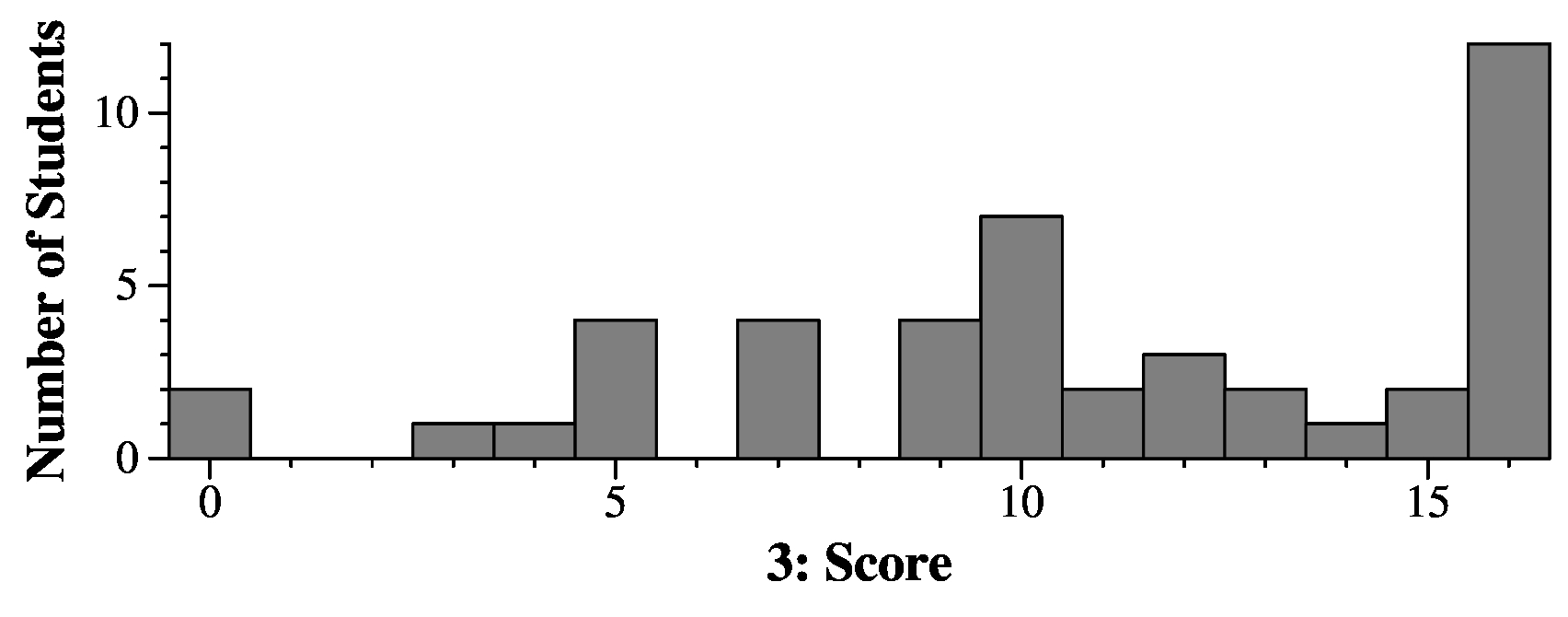 |
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char *nconcat(const char **str)
{
int length; /* For keeping track of the length of the strings. */
char *rv; /* The return string. */
int i;
/* First, calculate the length of the return string.
I add one for each string, to account for the spaces between strings,
and then for the final null character. */
length = 0;
for (i = 0; str[i] != NULL; i++) {
length += strlen(str[i]);
length++;
}
/* Allocate the return string. */
rv = (char *) malloc(sizeof(char) * length);
if (rv == NULL) { perror("malloc"); exit(1); }
/* Build the string incrementally, using the length so that
strcpy() always starts at the end of rv. */
strcpy(rv, "");
length = 0;
for (i = 0; str[i] != NULL; i++) {
if (i != 0) {
strcpy(rv+length, " ");
length++;
}
strcpy(rv+length, str[i]);
length += strlen(str[i]);
}
return rv;
}
int main(int argc, const char **argv)
{
printf("%s\n", nconcat(argv));
}
|
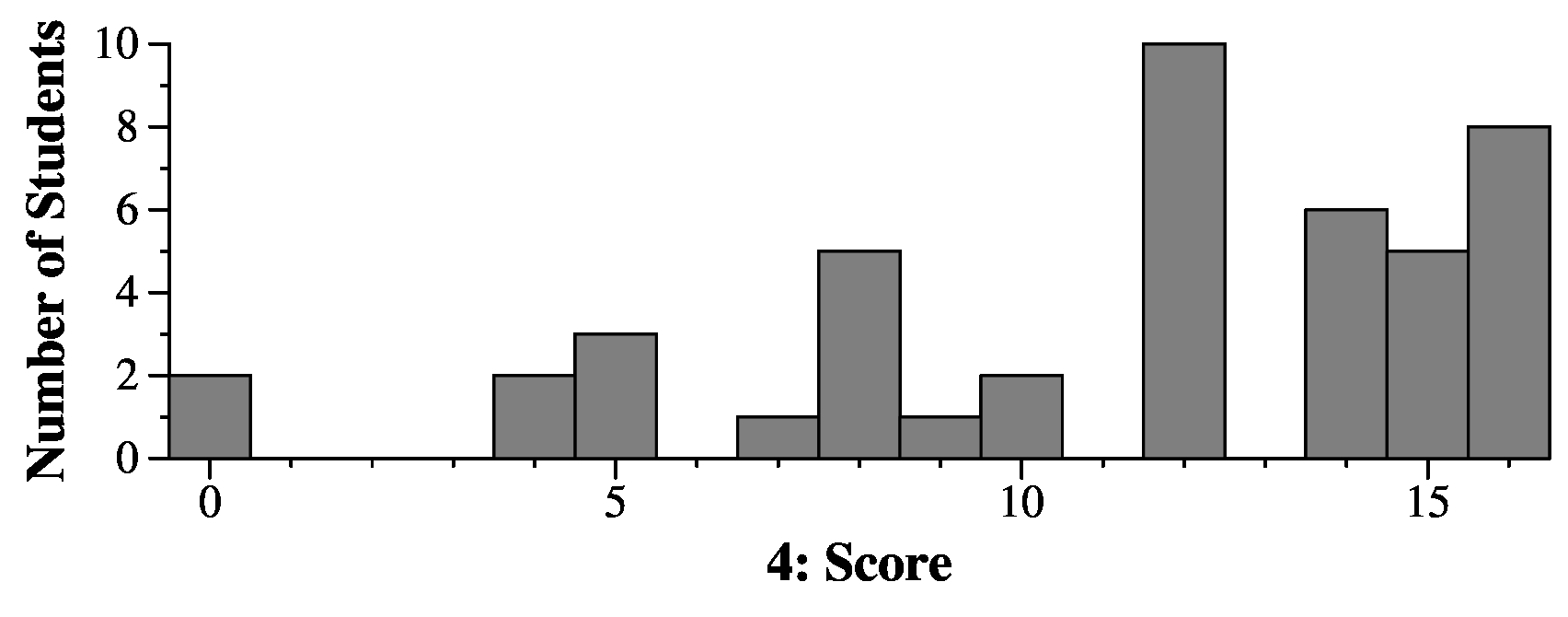 |
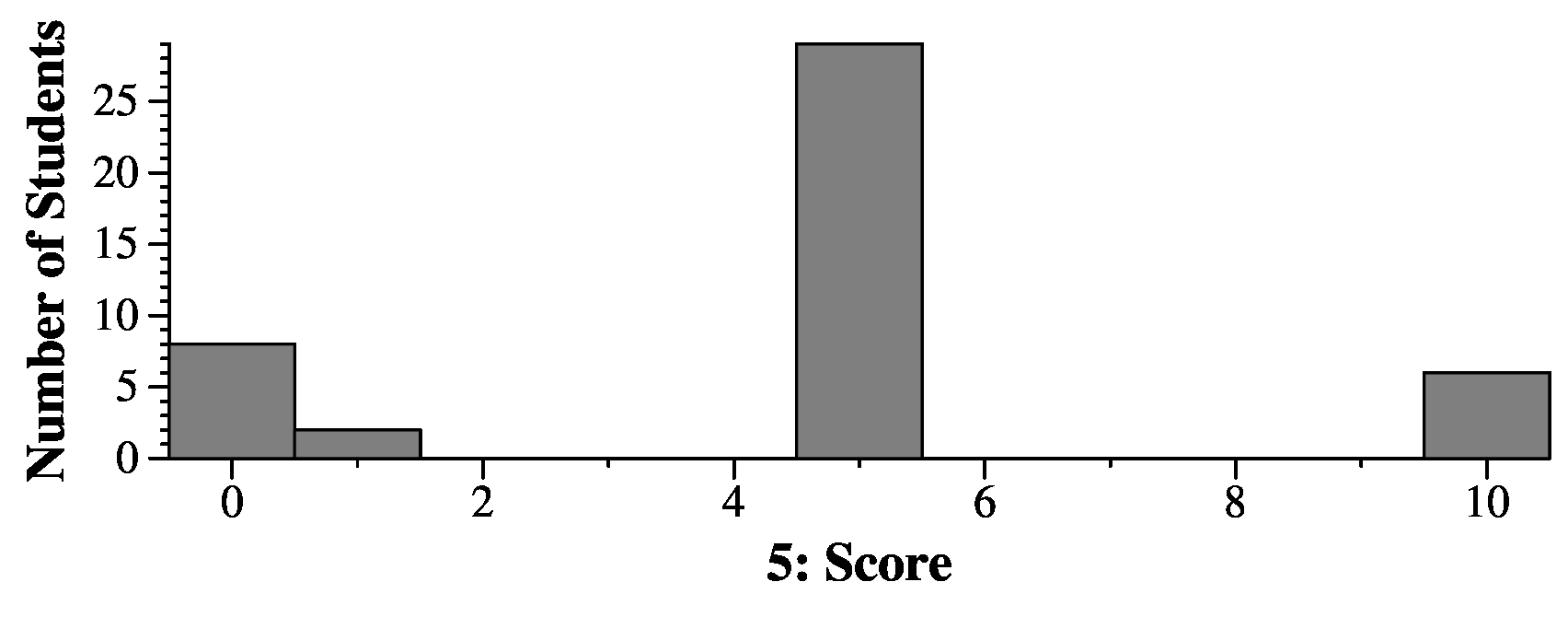
In fact, you can view read() as being slightly superior here. If we're using fread(), then we have to call fopen() on each file, which will allocate a 4K to 8K buffer, and then each fread() call will call read() to read 4K to 8K so that it performs buffering. That will be more expensive than read() simply reading 16 bytes and then closing the file.
(Now, if you want to argue that you have to read 4K anyway, because your disk sector size will be on the order of 4K, that's also a fine argument.)
 |
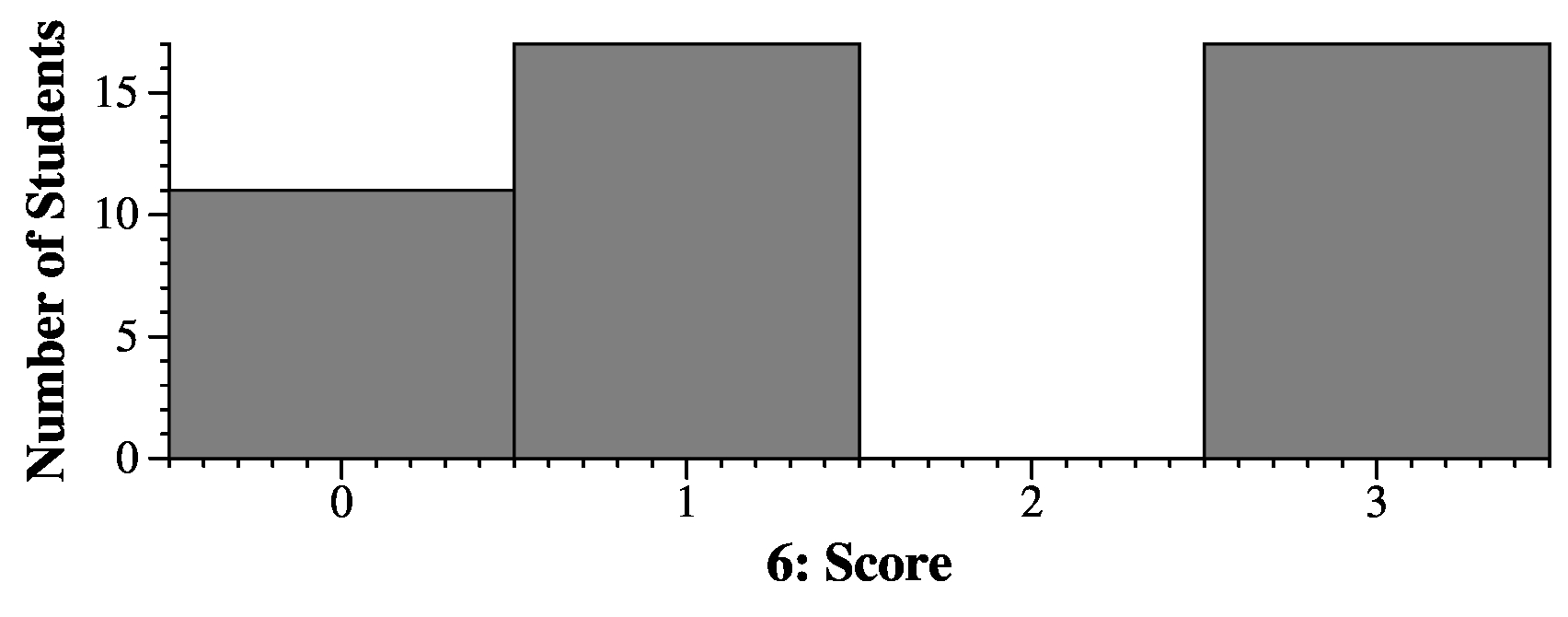
struct a194 {
char c0; /* Bytes 0-3: We need three bytes of padding after c0. */
int i0; /* Bytes 4-7. */
int i1; /* Bytes 8-11. */
int i2; /* Bytes 12-15. We don't need padding here, because this ends on an 8-byte boundary. */
double d0; /* Bytes 16-23. */
};
The answer here is 24.
 |
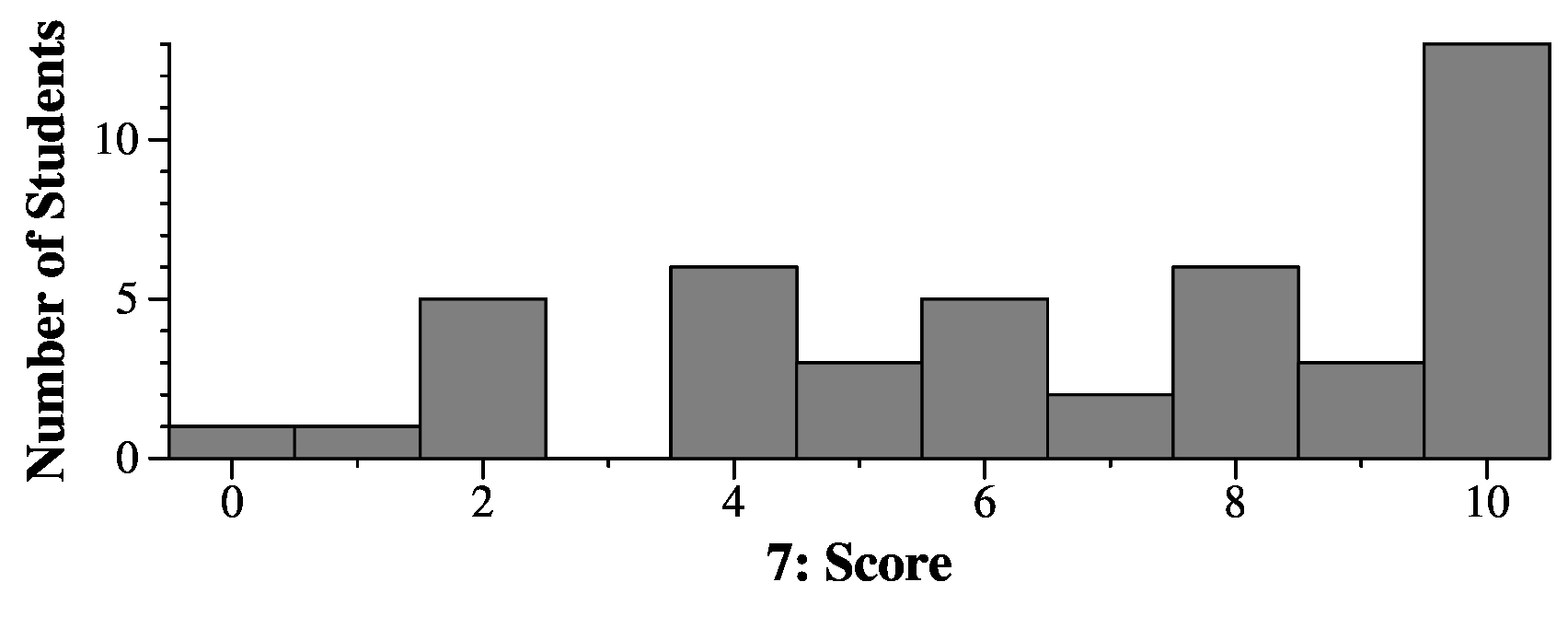
Byte 0 1 2 3 4 5 6 7 8 9 10 11 Value-in-hex 0 41 42 45 46 0 0 0 0 0 0 0 Value-in-chars \0 A B E F \0 \0 \0 \0 \0 \0 \0 |
1. 0x45424100 2. 0x46
Byte 0 1 2 3 4 5 6 7 8 9 10 11 Value-in-hex 43 41 42 45 46 44 0 0 0 0 0 0 Value-in-chars C A B E F D \0 \0 \0 \0 \0 \0 |
So the last line is:
3. CABEFD
 |