2024 CS360 Midterm Exam - Answers and Grading
February 29, 2024
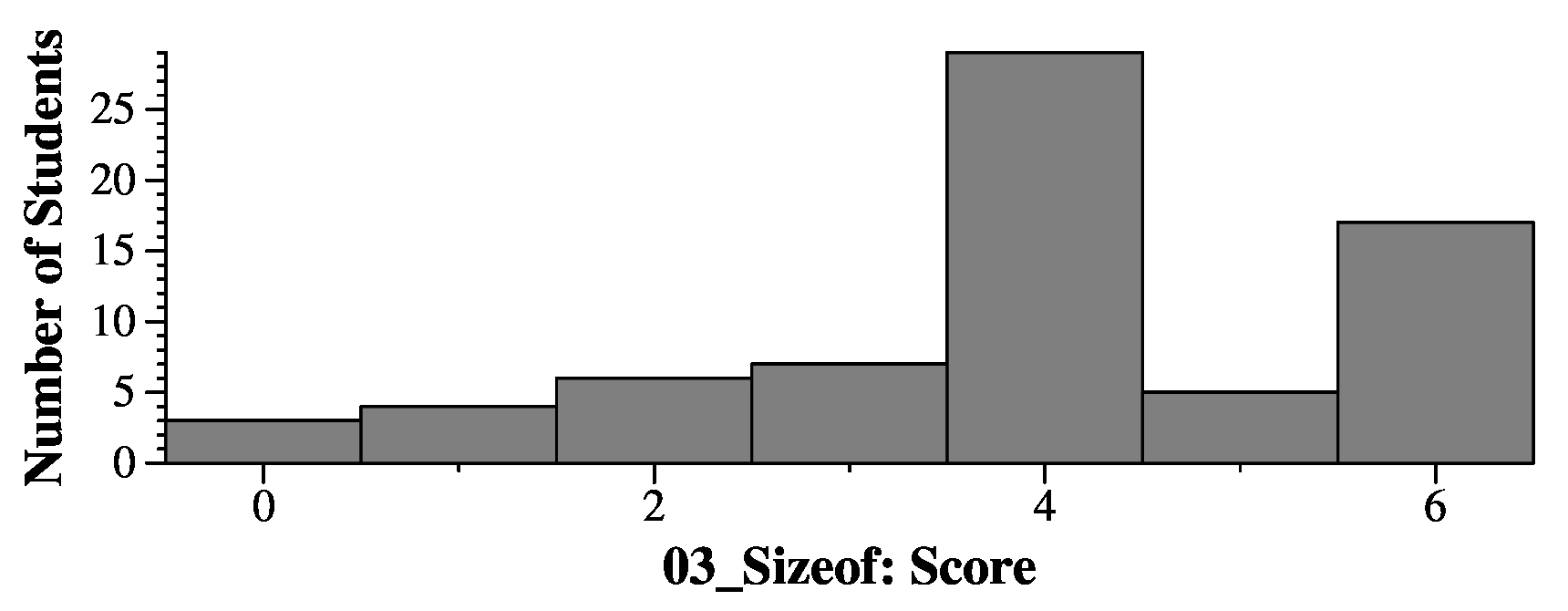
Question 3 - 6 Points
pebbles,
luigi,
scooby,
harvey, and
dontonio:
The answer is 24.
In order to make everything align on multiples of their sizes, you need the following
layout:
- Byte 0: x1
- Byte 1: padding
- Bytes 2-3: x2
- Bytes 4-7: x3
- Bytes 8-15: x4
- Bytes 16-19: v
- Bytes 20-23: Padding. If you don't have this padding, then x4 will not be aligned
when these are allocated in an array.
benton,
pluto,
peach,
bambam, and
fred:
The answer is 8.
In order to make everything align on multiples of their sizes, you need the following
layout:
- Byte 0: x1
- Bytes 1-3: padding
- Bytes 4-7: x2
bruno,
bluey,
babydaisy,
mario, and
wilma:
The answer is 8.
In order to make everything align on multiples of their sizes, you need the following
layout:
- Bytes 0-3: x1
- Byte 4: x2
- Bytes 5-7: padding
Grading
Each part was 2 points. On the questions where the answer was 8, you got 0.5 points for 5.
On the questions where the answer was 24, you got 0.5 points for 20 and 28.
Question 4 - 14 Points
This is the answer to the example exam question.
- Part A: the memcpy() copies two bytes -- the 'K' and 'Y' -- from s to
bytes 3 and four of t. This turns t into "ABCKYFG".
- Part B: the strcpy() copies the last four characters of s - "ALXM" - and the
null character after the "HIJ" of t: "HIJALXM".
- Parts C, D, E, F: the for loop turns s into the following. I'll put
asterisks for null characters, and then I'll put pointers to every 7th byte:
012345678901234567890123
*YFGU*DIWZ*ERCO*STJQ*LXM*
^ ^ ^ ^
|
The answers are:
- Part G: this puts "OPQR" at the end of "YFGU", so the answer is "7-YFGUOPQR."
Here is a grid of correct answers, keyed on the first five characters of s:
DLTGB
1-ABCDLFG
2-HIJWMPK
3-
4-IHX
5-C
6-MPK
7-LTGBOPQR
|
JBASG
1-ABCJBFG
2-HIJNTYD
3-
4-IQC
5-W
6-TYD
7-BASGOPQR
|
KYFGU
1-ABCKYFG
2-HIJALXM
3-
4-IWZ
5-O
6-LXM
7-YFGUOPQR
|
SPMBI
1-ABCSPFG
2-HIJCNFT
3-
4-LDO
5-U
6-NFT
7-PMBIOPQR
|
TPGHC
1-ABCTPFG
2-HIJIUER
3-
4-XLV
5-S
6-UER
7-PGHCOPQR
|
Grading
Two points per part.
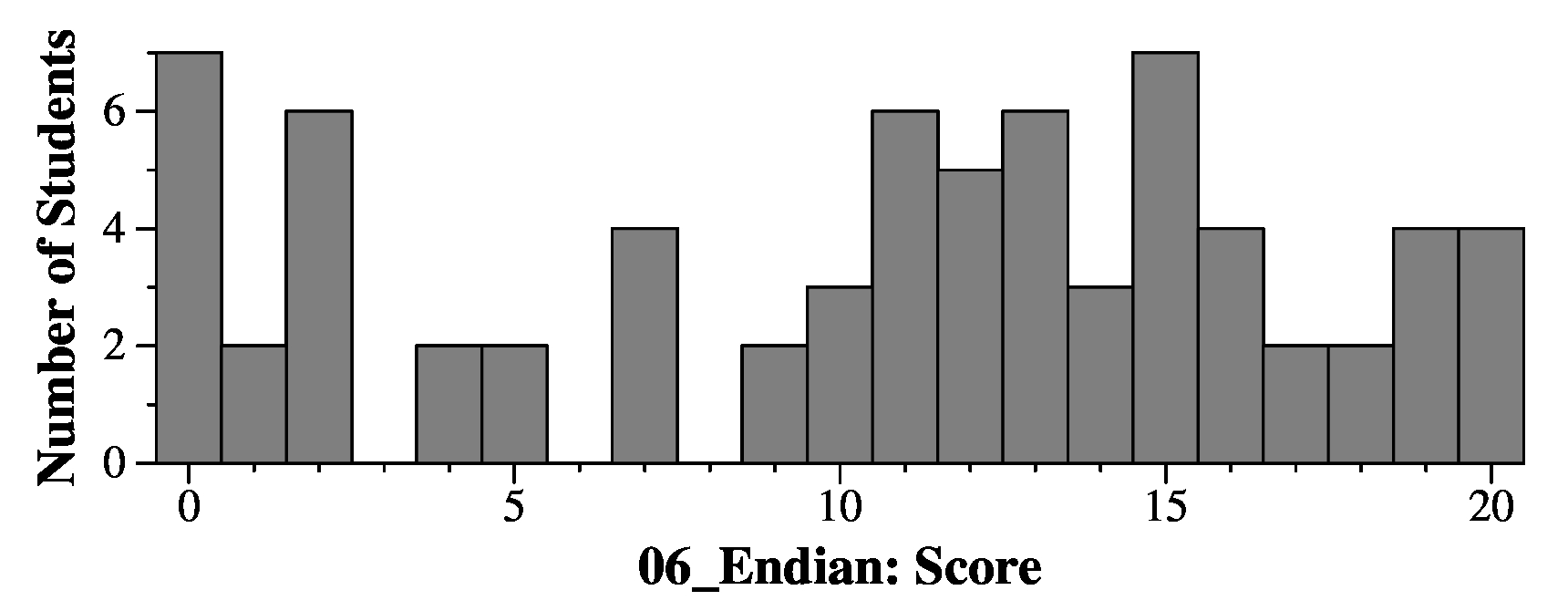
Question 6 - 20 points
Here are the 16 bytes, in both big and little endian, after the first for
loop.
Little Big
r, s 0x374a9a7c 7c 9a 4a 39
r+1, s+4 0x485bab8d 8d ab 5b 4a
r+2, s+8 0x596cbc9e 9e bc 6c 5b
r+3, s+12 0x6a7dcdaf af cd 7d 6c
|
The strcpy() changes five bytes to 0x42, 0x45, 0x41, 0x44 and 0x00.
The easiest thing to do is to change the big-endian, and then copy those
changes to the little endian. I've colored that in red:
Little Big
r, s 0x374a9a7c 7c 9a 4a 39
r+1, s+4 0x44414542 42 45 41 44
r+2, s+8 0x596cbc00 00 bc 6c 5b
r+3, s+12 0x6a7dcdaf af cd 7d 6c
|
In lines 1-4, you print the little-endian, and in lines 5-9, you use the big endian
to find the correct byte to print. These answers:
Line 1: 0x374a9a7c
Line 2: 0x44414542
Line 3: 0x596cbc00
Line 4: 0x6a7dcdaf
Line 5: 0x7c
Line 6: 0xab
Line 7: 0x6c
Line 8: 0c6c
|
Now, for line 9, you copy the four bytes starting at s+10 to r. The easiest
way to do that is to use the big-endian representation, and then copy
the changed bytes to the little endian. That changes the
bytes to the following. I've colored the bytes that I copied in blue, and the
bytes that have changed in red:
Little Big
r, s 0xcdaf5b6c 6c 5b af cd
r+1, s+4 0x485bab8d 8d ab 5b 4a
r+2, s+8 0x596cbc9e 9e bc 6c 5b
r+3, s+12 0x6a7dcdaf af cd 7d 6c
|
The output is the little endian: 0xcdaf5b6c.
In the last line, I set x to be 20 bytes after r. Since that is five integers,
the answer is 5.
Below is a grid of correct answers keyed on the value of num:
374a9a7c
0x374a9a7c
0x44414542
0x596cbc00
0x6a7dcdaf
0x7c
0x45
0x6c
0x6a
0xcdaf596c
5
|
3b49583a
0x3b49583a
0x44414542
0x5d6b7a00
0x6e7c8b6d
0x3a
0x45
0x6b
0x6e
0x8b6d5d6b
5
|
589737b7
0x589737b7
0x44414542
0x7ab95900
0x8bca6aea
0xb7
0x45
0xb9
0x8b
0x6aea7ab9
5
|
6c3829a8
0x6c3829a8
0x44414542
0x8e5a4b00
0x9f6b5cdb
0xa8
0x45
0x5a
0x9f
0x5cdb8e5a
5
|
9a7a87a9
0x9a7a87a9
0x44414542
0xbc9ca900
0xcdadbadc
0xa9
0x45
0x9c
0xcd
0xbadcbc9c
5
|
Grading
2 points per question.
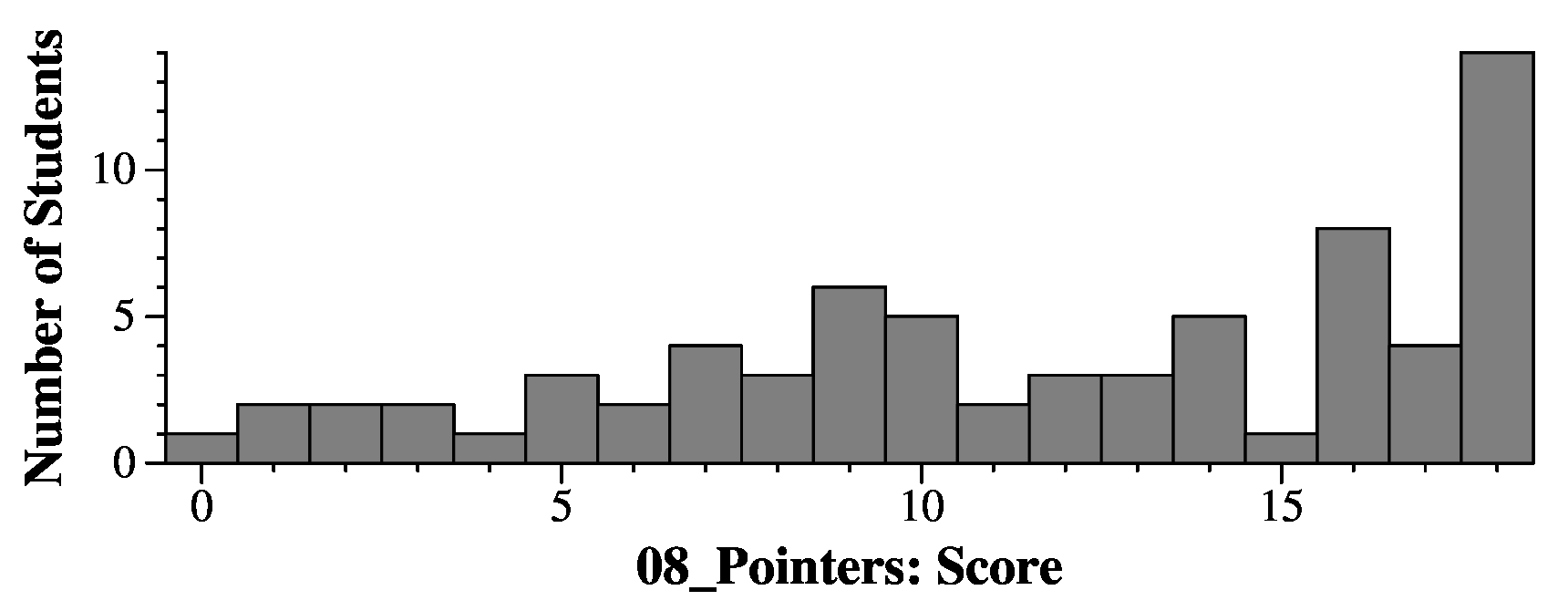
Question 8
- Line 1: f is 0x7685c1e8, so &(f->i) is also 0x7685c1e8. The
value of
(f->i) is therefore 0x7685c20c and the answer is 0x0c.
- Line 2: &(f->ip) is 0x7685c1ec, so
(f->ip) is 0x7685c21c and the answer is 0x1c.
- Line 3: *(f->ip) is what 0x7685c21c points to:
0x7685c1ec, so the answer is 0xec.
- Line 4: &(f->ipp) is 0x7685c1f0, so
(f->ipp) is 0x7685c208,
*(f->ipp) is 0x7685c230 and
**(f->ipp) is 0x7685c214. The answer is 0x14.
- Line 5: &(f->fp) is 0x7685c1f4, so
(f->fp) is 0x7685c224. That is also
amp;(f->fp->i).
Therefore,
(f->fp->i) is 0x7685c1e8. The answer is 0xe8.
- Line 6: &(f->fp) is 0x7685c1f4, so
(f->fp) is 0x7685c224.
amp;(f->fp->fp) is 12 bytes later: 0x7685c230. Its value
is 0x7685c214, so
(f->fp->fp->i) is 0x7685c1f4. The answer is 0xf4.
- Line 7: f[0] is composed of the 16 bytes starting at 0x7685c1e8.
Therefore, f[1] is composed of the 16 bytes starting at 0x7685c1f8.
So amp;(f[1].i) is 0x7685c1f8, and
f[1].i is also 0x7685c1f8 (the pointer and the value happen to be the
same). The answer is 0xf8.
- Line 8: f[2] is composed of the 16 bytes starting after f[1],
at address 0x7685c208.
So amp;(f[2].i) is 0x7685c208, and
f[2].i is 0x7685c230.
The answer is 0x30.
- Line 9: f[3] is composed of the 16 bytes starting after f[2],
at address 0x7685c218.
So amp;(f[3].fp) is 0x7685c224, and
f[3].fp is 0x7685c1e8.
That is also amp;(f[3].fp->i), whose value is 0x7685c20c. The answer is 0x0c.
Although the pointers were different from question to question, the last bytes were
all the same, so the answers were the same for each question.
Grading
2 points per line. I gave you half credit if you gave me the last byte for the
address rather than the value. (For example, you gave me 0xe8 in Line 1, instead
of 0x0c).
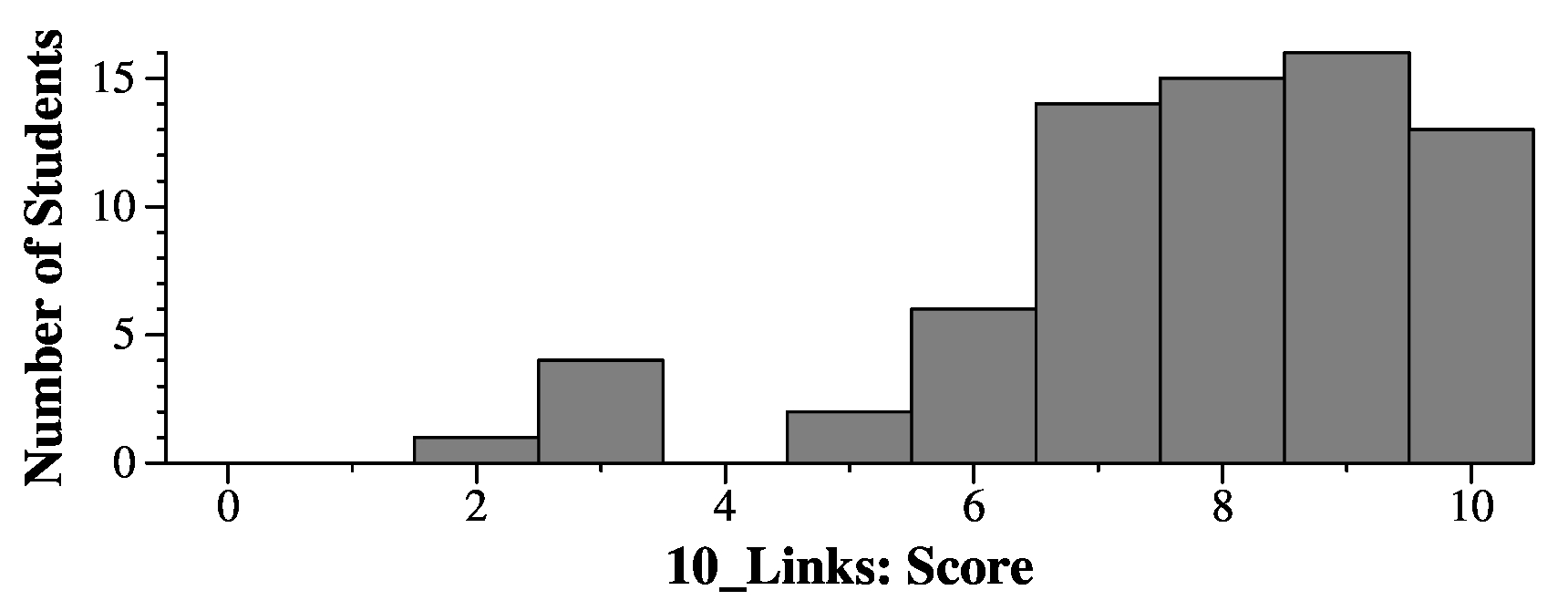
Question 10
The ln command adds a name/inode binding to dir1: It has added the
name f3.txt and bound it to the same inode as ./f1.txt.
This also changes the modification time of the inode for dir1. It may
change the size too, but sometimes not.
The echo command has added the line "fred" to f1.txt. It also
changes the size and modification time of f1.txt's inode. Although the
new line will be reflected in dir/f3.txt, we didn't add lines to two files --
just to one file that is linked to two names.
Question 11
I thought this would be a straightforward question. You need to:
- Open the current directory and traverse its entries.
- For each file, determine its size with stat().
- Then insert a combination of the size and filename into a red-black tree.
- When you're done traversing the directory, traverse the red-black tree and print.
You have choices when it comes to how to organize "combination of size
and filename" in the red-black tree:
- Create a data structure that has the size and name for each file, and insert it into
the tree with jrb_insert_gen().
- Make a two-level red-black tree, where the first level is sorted by the file's size,
and the second level is sorted by the file's name. The nice thing about this solution is
that you can traverse the first tree in reverse, and then traverse the second tree normally.
- Create a single string from each file, where sorting the string allows you to print
the files in the correct order. This is more of a pain than you might think, because you
have to sort the sizes in reverse. Something like:
key = (char *) malloc(15+strlen(de->d_name));
sprintf(key, " %010d %s", -((int) buf.st_size), de->d_name);
|
In my solution, I chose the two-level tree:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/stat.h>
#include <dirent.h>
#include "jrb.h"
int main()
{
DIR *d;
struct dirent *de;
JRB t1, tmp1;
JRB t2, tmp2;
struct stat buf;
/* Open the current directory and make the main red-black tree. */
d = opendir(".");
if (d == NULL) { perror("."); exit(1); }
t1 = make_jrb();
/* Traverse the directory and get the size of each file in the stat buf. */
for (de = readdir(d); de != NULL; de = readdir(d)) {
if (stat(de->d_name, &buf) != 0) { perror(de->d_name); exit(1); }
/* Look up the file size in the main tree. If it's not there, make an
entry for it with an empty red-black tree as the val. */
tmp1 = jrb_find_int(t1, buf.st_size);
if (tmp1 == NULL) {
tmp1 = jrb_insert_int(t1, buf.st_size, new_jval_v((void *) make_jrb()));
}
/* Set t2 to the red-black tree in the val and insert the filename there.
You have to strdup() this because opendir() might overwrite the dirent
pointer. */
t2 = (JRB) tmp1->val.v;
jrb_insert_str(t2, strdup(de->d_name), new_jval_i(0));
}
/* It's good form to close the directory here, since you're done with it. */
closedir(d);
/* Perform a nested traversal and print out the file names in the second-level trees. */
jrb_rtraverse(tmp1, t1) {
t2 = (JRB) tmp1->val.v;
jrb_traverse(tmp2, t2) printf("%s\n", tmp2->key.s);
}
/* If we weren't returning and killing the process, we'd have to free memory. However,
since the process is exiting, we can simply let the operating system clean up
the memory. */
return 0;
}
|
Grading
I split the grading into 6 parts:
- Getting the opendir() and readdir() calls right: 3 points
- Getting the stat() call right: 2 points
- Organizing your solution correctly (one of the three above): 3 points
- Getting details correct while creating your data structure: 3 points
- Getting details correct while printing your data structure: 3 points
- Memory management: 2 points.
Some random comments:
- If you didn't have one of the right organizations, you could only get two points
for each of bullets 4 and 5 above.
- Which means that if you used one tree, keyed on size, with the filenames in the vals,
and everything else was done right, you got 12 points.
- The "memory management" was specific to making sure you store copies of the filenames
in the trees. If you didn't store the names anywhere, you got a zero for this.
Please Read This for Future Exams
First piece of advice: Please read the question and look at the example. In particular:
- a.out wasn't given command line arguments, so don't read from argc/argv.
- The writeup has "." and ".." in the output. So don't exclude them.
- The writeup has "dir1" in the output, so don't exclude directories.
- The output printed a filename on each line. So don't print "File: aaa.txt, Size: 1570".
- When I say a file cannot exceed 230 bytes, you don't have to worry about
the fact that buf.st_size is a long. It will fit in an int.
Second, if you have to sort things, you cannot use an n-squared data structure or
algorithm. Similarly, if you have to do storage and lookup, you also cannot use an n-squared
data structure or algorithm. This is regardless of your language. So, if you're uncomfortable
with maps and unordered_maps in C++, dictionaries in Python, red-black trees in CS360, or
whatever the proper data structures are in your other languages of choice,
then you need to put some time in so that you are comfortable with them. Using them properly
should be like breathing. On this question, it was exceptionally
disheartening for me to see dllists in your implementation and O(n2)
loops.
Question 12
The problem with this implementation is the write() call, which writes 16 bytes at
a time. Since write() is a system call, it is slow, and you speed this program up
drastically by adding a buffer to Logfile, and then only performing write()
when the bufer is full, and when you close the logfile.
Of course, if you had access to the C stdio library, you'd just call fopen(),
fclose() and fwrite(), and call it a day. But you don't have that luxury.
I fully intended for you to copy/paste the "bad" implementation into your answer and then
update it. That's what I did below -- there is a comment by each of my changes:
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include "logfile.h"
typedef struct {
int fd;
char buffer[16*256]; /* I add a 4K buffer. */
int nfull; /* This says how many entries there are: [0-256] */
} Logfile;
void *open_logfile(const char *filename)
{
int fd;
Logfile *l;
fd = open(filename, O_WRONLY | O_CREAT | O_APPEND, 0666);
if (fd < 0) return NULL;
l = (Logfile *) malloc(sizeof(Logfile)); /* Allocate the buffer. */
l->fd = fd;
l->nfull = 0; /* Set the entries to zero. */
return (void *) l;
}
void write_logentry(void *logfile, void *logentry)
{
Logfile *l;
l = (Logfile *) logfile;
if (l->nfull == 256) { /* Flush the buffer and reset nfull if the */
write(l->fd, l->buffer, 16*256); /* buffer is full. */
l->nfull = 0;
}
memcpy(l->buffer+(l->nfull * 16), logentry, 16); /* Copy the entry to the buffer. */
l->nfull++; /* Increment the number of entries. */
}
void close_logfile(void *logfile)
{
Logfile *l;
l = (Logfile *) logfile;
if (l->nfull != 0) write(l->fd, l->buffer, l->nfull*16); /* Do a final flush if necessary. */
close(l->fd);
free(l); /* Remember to free the buffer. */
}
|
I used the following rubric as a guide, but often simply assigned a grade after seeing how
you approached the problem, since your approach often didn't fit the rubric exactly.
- Add a buffer and some form of counter to the log file: 2 points
- Allocate it in open_logfile and set the counter to zero: 2 points
- Check and flush in write_logentry: 4 points
- Copy the entry and increment #entries: 4 points
- Do a final flush in close_logfile: 3 points
- Free the buffer: 1 point