 |
Let's first take a look at the unique nodes -- I did that in vi by copy/pasting. The first thing I did was convert all of the spaces to newlines, and piped the vi buffer to "sort -u". This revealed the following nodes:
10 11 12 13 15 19 51 52 91 92 93 94 95 |
Nice -- so there are only two nodes in question: 51 and 52. All of the nodes starting with '1' go to Bob, and all of the nodes starting with '9' go to Alice. I wrote the following script (script.sh) to turn the nodes into edges:
echo "10 51 93 52 13 51 94 52 51 52 12 52 10 52 15 51 92 51 93 52 19 51 91 51 92 52 12 51 95 52 11" | # Echo the nodes
sed 's/^/ /' | # Add a space to the front
sed 's/ 1./ 10/g' | # Turn 1x into 10
sed 's/ 9./ 90/g' | # Turn 9x into 90
awk '{ for (i = 2; i < NF; i++) { a = $i; b = $(i-1); print (a < b) ? a : b, (a < b) ? b : a }}' | # For each pair of nodes, print them in ascending order
sed 's/ /-/g' > tmp.txt # Turn the space into a dash and store in tmp.txt
for i in `sort -u tmp.txt` ; do # For each unique edge in tmp.txt
echo $i `grep $i tmp.txt | wc | awk '{ print $1 }'` # Count the number of occurrences in tmp.txt
done
|
We run it:
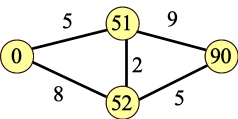
UNIX> sh script.sh 10-51 5 10-52 8 51-52 2 51-90 9 52-90 5 UNIX>Here's our graph:
|
Here's our cut:
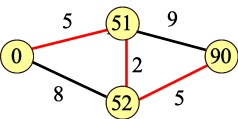 |
Alice gets 51, Bob gets 52.