CS560 Final Exam - May 4, 2005
Jim Plank
Answer to: Question 1 (9 Points)
A file allocation table is a way of implementing a linked index scheme for
files that has a number of advantages over storing a link at the end of
each block of a file. Specifically, the blocks on a disk are partitioned
into data blocks and link blocks. The link blocks are in the first blocks
of the disk, and are composed solely of links for the data blocks. The directory
entry for the file is simply a pointer to the first block of the file.
For example,
the first link in the first link block contains the link for the first data
block on the list. Thus, if a file is composed of multiple blocks, the link for
the file's first data block points to the second data block, and so on. Obviously,
the last block's link will contain a NULL pointer.
This scheme is preferable to storing links in the data blocks for two main
reasons. First, the block's size can be a power of two, which is often very
convenient. In other words, the block itself is not broken up into a data
portion and a metadata portion. Second, the link blocks themselves may be
cached in the operating system, and therefore finding the bytes in the middle
of a file does not require reading all of the previous data blocks from disk.
Instead, the cached links may be used without any extra reading of data
from disk.
The links also provide a nice way to identify free blocks -- instead of having
a NULL pointer or a pointer to another block, the link can have a different
sentinel value that flags it as a free block.
There are two kinds of caching in this system. The first is caching the link
blocks, as discussed above. The second is performing standard disk block
caching -- either LRU caching for frequently used blocks, or lookahead
caching to optimize the performance of serial file access.
Grading
- Variant of linked allocation scheme: 2 points
- Metadata holds links: 1 points
- All the metadata held in one set of blocks on disk; the rest have data: 2 points
- Can cache the index blocks to reduce disk overhead: 2 points
- Can have a flag in the link field to denote free blocks: 1 point
- Can have standard read caching: 1 point
Answer to Question 2 (11 points)
Ok -- before answering the question, what do we know? Since pages are 8K,
the offset part of an address will be the last 13 bits. Since there are
four segments, the first two bits will contain the segment number. Therefore,
the middle 17 bits will be the offset into the segment's page table.
Given that, we can now answer the individual questions:
- A: Since there are 17 bits to specify the offset into the segment's
page table, there may be 2^17 pages in a segment. That is 128K pages, or 0x20000
if you want to use hex.
- B: Since there are 128K pages, and each PTE is 4 bytes, the potential
size of a page table is 512K bytes. Divide that by 8K, and you get 64, so the
answer is that the potential size of a segment's page table is 64 pages. Note,
they'll have to be contiguous, since the page table is not paged.
- C:
Ok, the code will go in segment 0, the globals in segment 1, the heap in
segment 2 and the stack in segment 3. The first two bits of segment 0 will
be 00. The second two will be 01. The third two will be 10 and the last two
will be 11. Thus, code addresses will start with 0x0, globals addresses will
start with 0x4, heap addresses will start with 0x8, and stack addresses
will start with 0xc. A page is 0x2000 bytes. Thus, here is
how virtual memory is partitioned:
- Addresses 0x00000000 to 0x00001fff are invalid.
- Addresses 0x00002000 to 0x00033fff compose the code segement.
- Addresses 0x00034000 to 0x3fffffff are invalid (the end of segment 1).
- Addresses 0x40000000 to 0x40004fff compose the globals segment.
- Addresses 0x40005000 to 0x7fffffff are invalid (the end of segment 2)
- Addresses 0x80000000 to 0x807fffff compose the globals segment.
- Addresses 0x80800000 to 0xbfffffff compose the (the end of segment 3)
- Addresses 0xc0000000 to 0xc000ffff compose the globals segment.
- Addresses 0xc0010000 to 0xffffffff are invalid (the end of segment 4).
- D: A page will hold 2K worth of PTE's (8K divided by 4 bytes
per PTE).
The code will take 200/8 + 1 PTE's (the +1 is for the invalid
first page). That's 26 PTE's. Therefore, the code's page table will take
one page. The globals take 5 PTE's, and fit on one page. The heap consists
of 1K pages, and again all of its PTE's fit on one page. Ditto the stack.
Therefore, there will be a total of four pages of page tables for the process.
Grading
- Part A: 2 points. If you answered 2^12 because pointers are
27 bits, you got .75 points. There are 27 bits in the PTE, not on the machine.
- Part B: 2 points -- if you got part A wrong, but derived part
B correctly from your incorrect answer to part A, you still got the two
points. If you got the correct answer, but derived it incorrectly, then
you got zero points. If you got the correct number of bytes but answered
bytes rather than pages, you got 1.5 points.
- Part C: 5 points - 1 for invalid first page, 1 for code starting
and ending correctly, one for globals/heap, one for the stack, one for stating that
the rest of the address space is invalid (or will cause seg faults).
- Part D: 2 points
Answer to Question 3 (10 points)
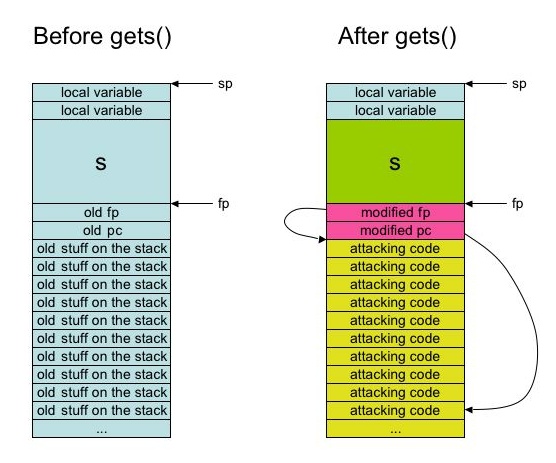
Since gets() does not check to see how big s is, it is
entirely possible that the bytes in memory following s get
overwritten. Suppose that s is on the stack. Then you can
write beyond s, and insert code below the frame pointer on the
stack. Finally, you modify the return pc just below the fp to point
to this new code. When the procedure calling gets() returns,
you will be executing the malicious code:
Grading
- Decent rough explanation: 3 points
- Getting the details right (such as stating that you modify the
return pc below the fp so that when the calling procedure returns
you are executing malicious code): 2 points
- Good rough picture: 3 points
- Having the sp and fp in the picture correctly: 1 point
- Having the modified pc pointing to new code: 1 point
Answer to Question 4 (6 points)
You use a special arithmetic called Galois Field arithmetic, so that
addition/multiplication/division are closed, and inverses exist.
You will use a 10 X 4 dispersal matrix, whose first 4 rows are the
identity matrix. The rest of the dispersal matrix is defined such that
the matrix that results when any six rows are deleted is still invertible.
The coding words are defined by the six bottom rows of the dispersal
matrix. Each word is created by taking the dot product of the corresponding
row of the dispersal matrix with the data words. Put another way,
if you multiply the dispersal matrix with the vector composed of the data
words, you will yield a vector of 10 elements containing the 4 data words
in the first 4 elements, and the 6 coding words in the remaining elements.
To decode, suppose you have any 4 of the collection of 10 data and coding
words. You create a 4 X 4 matrix B from the four rows of the dispersal
matrix that correspond to the 4 words that you have. You then invert B.
The product of B and the vector of the 4 words that you have will yield
the 4 data words.
Grading
Each of these is one point:
- You need a 10x4 dispersal matrix A, whose top four rows are the identity matrix.
- A*D = DC (data + coding words)
- To decode, generate B from the appropriate four rows of A.
- Invert B.
- B-1 * Downloaded = Data
- Arithmetic is special (Galois field)
Answer to Question 5 (15 points)
Part 1
The matrices are 800 bytes each. Thus, each fits into exactly
one page. So the answer is five: the page holding the stack, the page
holding the code, the page holding a, the page holding b,
and the page holding c.
Part 2
Each matrix is now 8MB. Each row fits into exactly one page, since
each row consists of 1K elements, and doubles are 8 bytes.
Loop 3 of course reads the code segment and reads/writes the stack
segments. It also modifies the page that holds c[i*n+j].
It reads all elements of row i of matrix a.
Those are all held in one page, bringing our total up to four.
Finally, it reads all elements in column j of matrix b.
Each of those elements is in a different page. Therefore, it reads
1024 pages of matrix b. This brings the grand total to 1028
pages.
Part 3
The answer here is 5 pages. The four pages holding the stack,
code, c[i*n+j] and row i of a all get touched
in every iteration. Therefore, the pages holding each element of
column j of b will be the ones selected for replacement.
If you were worried that the wrong page might get kicked out, an
answer of 6, or even 10 would be ok.
Part 4
FIFO is kind of a disaster to this program. The problem is that
even though the four pages holding holding the stack,
code, c[i*n+j] and row i of a are used in
every iteration, there is no preference given to them when selecting
a page to kick out. Thus, when a page holding an element of b
needs to be brought in, it may kick out one of these pages, which will
cause an extra page fault on the next iteration.
Thus, we need 1028 (or x of you didn't answer 1028) pages if
we want to limit the page faults to 1028.
Part 5
Yes, suppose you have five pages allocated to your process, and you keep a free
frame pool of a page, where you maintain the identity of the page in the
free frame pool. Then if you kick out one of the four pages that will be
used in the next iteration, and then you catch a page fault on that page,
it will cost nothing to bring it back for the process since it is there in
the free frame pool. This trick is described in the book.
Grading
- Part 1: 2 points
- Part 2: 2 points
- Part 3: Anything between 5 & 10 pages: 2 points. Good explanation: 2 points.
- Part 4: x: 2 points. Good explanantion: 2 points.
- Part 5: 3 points for a good explanation.