 |
Part B: Context switches are expensive because they typically require a TLB invalidation. They are usually only a few instructions.
Part C: Mutual exclusion, hold and wait, no preemption, circular wait.
Part D: The heart of deadlock avoidance is keeping the system in a ``safe state,'' which is one where all processes can get their maximum resource needs without deadlock. To ensure that the system is in a safe state, the operating system sometimes has to deny a request, even though the resources is available. Granting the request would result in an unsafe state -- if all processes tried to get their maximum resource needs, the system would deadlock.
Part E: Belady's anomaly is when a page replacement algorithm results in more page faults on a page trace when its pool of pages is bigger. FIFO page replacement can exhibit Belady's anomaly. Certain algorithms, like LRU page replacement, do not exhibit Belady's anomaly, so if one observes the anomaly on an LRU implementation, one may assume that the implementation is buggy.
Part F: A working set is the set of pages touched within the last δ instructions of a process. It may be approximated using the reference bit. The operating system clears all the reference bits in a process' page table, and then after a certain period of time, defines the working set for that time interval to be the pages whose reference bits have been set by the hardware. Working sets are most useful in defining which pages should be loaded into memory when a non-resident process is made resident (this is called "prepaging.")
Part G: Contiguous. The files are all read-only, so they'll never change. The only real problem with contiguous allocation is that it doesn't handle changing file sizes and fragmentation. This installation will have neither.
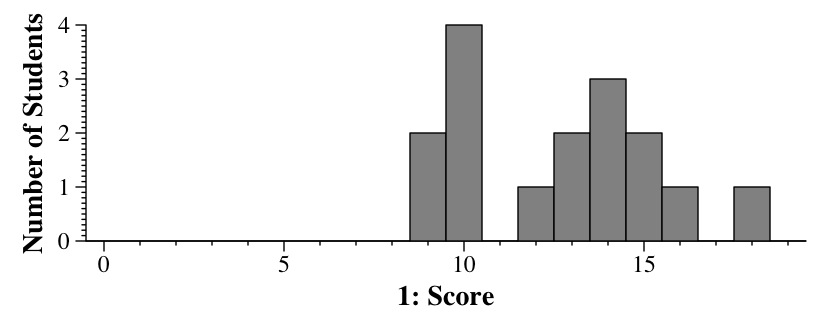
Grading:
|
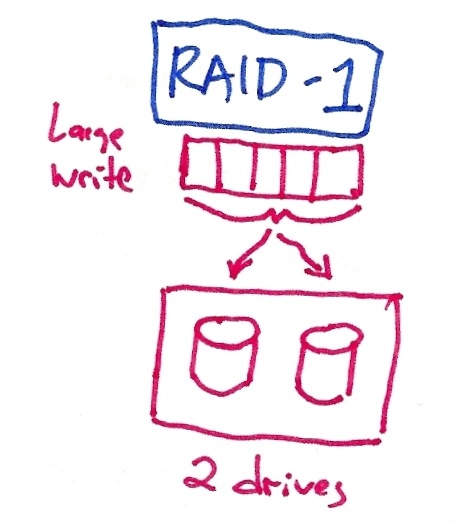
With RAID-1, we only have two disk drives, which are mirrored. The performance of a large write is equivalent to the performance on a single disk -- the controller will simply issue the write to two disks in parallel. RAID-1 can tolerate the failure of either disk. (Some of you said performance takes a hit with RAID-1 -- that's not true since both writes are issued in parallel. It's just more expensive).
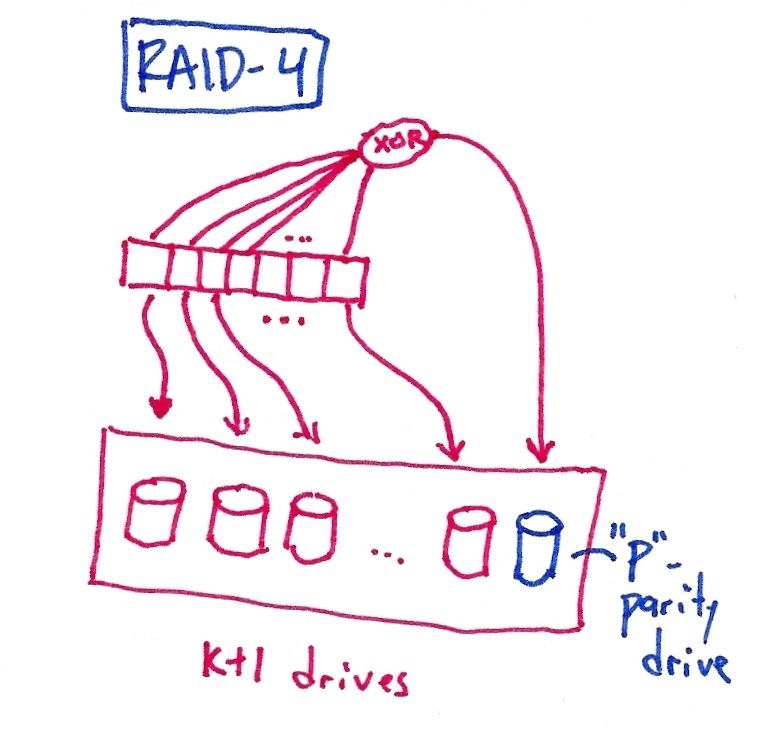
RAID-4 looks like RAID-0, but with one disk dedicated to parity. The performance of a large write is much like in RAID-0, except the contents of the parity drive must be calculated as well. Since XOR operations are a lot quicker than disk writes, this performance penalty is small. RAID-4 can tolerate the failure of any of the k+1 disks in the array.
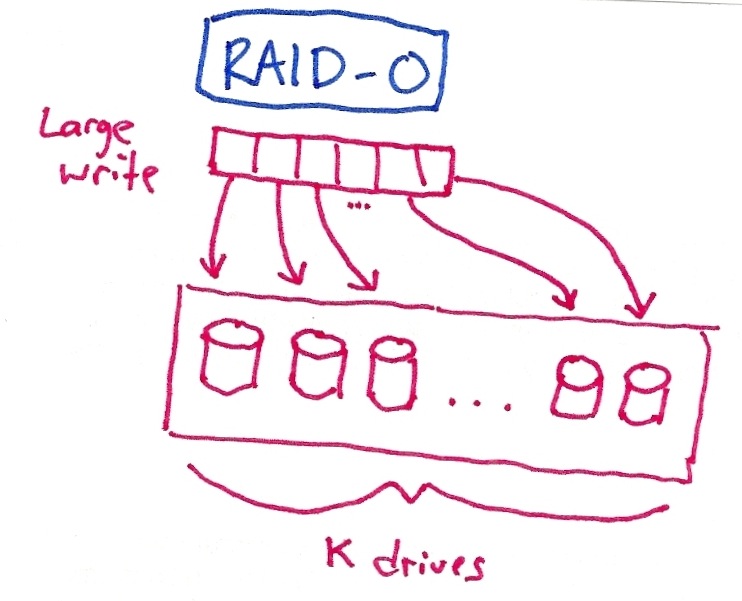
Low-budget pictures:
 |
 |
 |
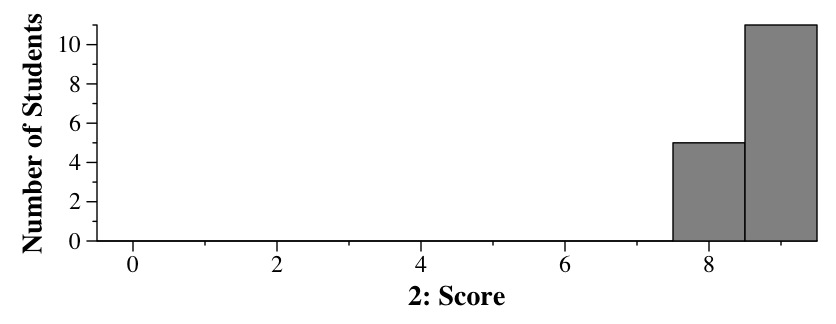
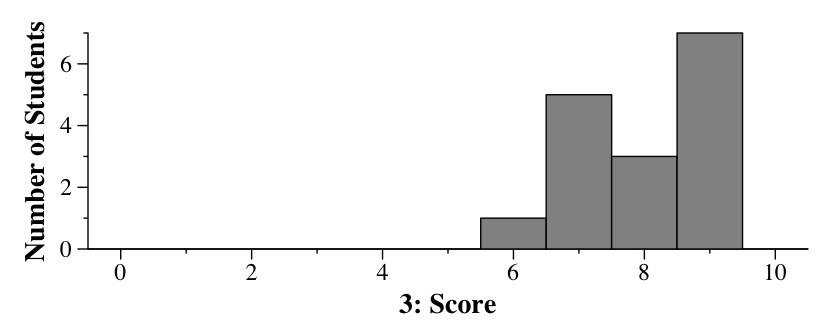
Grading: 9 points -- for each RAID, one point for the definition/picture, one for performance, one for fault-tolerance.
 |
 |
Part A: This asks for an address in the code segment. Any address from 0x100 to 0x2ff will do.
Part B: The offset is 9 bits, and since each page can fit 512/4 = 128 PTE's, the inner page pointer will be 7 bits. The outer page pointer will be the remaining 16 bits. So: 0xdb9658 = 1101 1011 1001 0110 0101 1000. Let's rewrite that: 11011011 1001011 001011000. So pouter = 0xdb, pinner = 0x4b and offset = 0x58.
Part C: Address zero will have pouter = 0, pinner = 0 and offset = 0. There will be a PTE for the inner page table block 0, and its valid bit will be set, because there are valid pages in that inner page table. The PTE in the inner page table for 0 exists, but its valid bit will equal zero. That is where the segmentation violation occurs.
Part D: The code, globals and heap will all be in segment 00. Since the segment is paged, there will be a page table for each segment. That page table will be in page-sized units, since the STLR contains "the number of pages consumed by the segment's page table." Thus, each page of the page table will hold 128 PTE's. Since segment 00 only needs to have 6 valid PTE's, its page table's size will be one page. PTE's 6 through 127 will have their valid bits set to 0, and STLR-00 will equal 1. Thus, the first address on virtual page 128 will cause a segmentation violation when the hardware checks STLR-00. That address is 00 + 0x80 + 0 = (00)(000000000000010000000)(000000000) = 0000 0000 0000 0001 0000 0000 0000 0000 = 0x10000.
Grading: Two points per part.
 |
Now, let's think about the process life-cycle. Here is a picture:
 |
The big subtletly is how one deals with preemption. I thought I had a sentence on the writeup that said "When process i preempts process j (e.g. due to an interrupt)," then the module of the operating system that handles this calls { job_ready(j); job_ready(i); j = next_job(); }" Proofreading, I don't see that on the exam, which made the question much more difficult. You had to assume the following: let j be the most recent job returned from next_job(). If j is preempted, then job_ready(j) will be called before the next call to next_job().
Given that, you only need four global variables to implement your MLFQ:
static list <Job *> Queues[3];
static int counter;
static int last_job_queue;
static Job *last_job;
void scheduler_setup()
{
last_job_queue = 0;
counter = 0;
last_job = NULL;
}
|
Now, let's think about job_ready(j). If j was the last job that I returned from next_job(), then it should go on the queue specified by last_job_queue. Otherwise, it should go on the top queue:
void job_ready(Job *j)
{
int q;
q = (j == last_job) ? last_job_queue : 0;
Queues[q].push_back(j);
}
|
The next procedure to implement is next_job(). This performs the straightfoward processing of the three queues until a job is found. When the job is found, it is removed from the queue, last_job_queue and last_job are set, counter is cleared and the job is returned:
Job *next_job()
{
list <Job *>::iterator qit;
for (last_job_queue = 0; last_job_queue < 3; last_job_queue++) {
if (!Queues[last_job_queue].empty()) {
qit = Queues[last_job_queue].begin();
last_job = *qit;
Queues[last_job_queue].erase(qit);
counter = 0;
return last_job;
}
}
last_job = NULL;
return NULL;
}
|
Finally, do_i_switch() uses the last_job_queue and the ticks for that queue to determine when to put the job on the next queue and switch. When the time quantum for the bottom queue expires, I put it back on the bottom queue to implement time-slicing with a large quantum.
Again, if you wanted, you could have had the quantum for queue 1 be 30 ticks and no quantum for queue 2.
int do_i_switch(Job *j)
{
int ticks[3] = { 30, 60, 300 };
counter++;
if (counter == ticks[last_job_queue]) {
last_job_queue++;
if (last_job_queue > 2) last_job_queue = 2;
Queues[last_job_queue].push_back(j);
last_job = NULL;
return 1;
} else {
return 0;
}
}
|
Grading: Obviously, I didn't expect you to have the exact same structure as my code. However, here are the things I did want:
 |