Question 1
Part 1
Since PTE's are 4 bytes each, you can fit 256 of them on a page. For that reason,
the two inner page table pointers are eight bits each.
- Offset: 10 bits
- Inner page pointer: 8 bits
- Middle page pointer: 8 bits
- Outer page pointer: the leftover bits: 6 bits.
Part 2
Ok -- there are going to be 12 valid user pages:
- The code: Four pages starting at address 0x1000. Since 0x1000 is the fourth page,
these are pages 4, 5, 6 and 7.
- The globals: One page starting at address 0x2000. Since 0x2000 is the 8th page,
this is page 8.
- The heap: Three pages starting at address 0x3000. Since 0x2000 is the 12th page,
these are pages 12, 13 and 14.
- The stack: Four pages starting at address 0xfffff000. To get the page number, look
at one plus the top address: 0x100000000. That divided by 0x400 is 0x400000.
Thus, these are pages 0x3ffffc, 0x3ffffd, 0x3ffffe and 0x3fffff.
We get to choose where these pages are mapped. We'll call them pages 0-11.
Now, build backwards.
- Page 12 will be the inner page table pointing to the beginning
of the user area -- this will take care of the mappings for the first 256 pages, which
means it takes care of the first 8 pages above.
- Page 13 will be the inner page table
pointing to the stack. It will have pointers for pages the last 256 pages, which
are pages 0x3fff00 to 0x3fffff. Only the last four of these will be valid.
- Page 14 will be the middle page table pointing to the beginning of the
user area. It will take care of the first 256*256 = 0x100*0x100 = 0x10000 pages.
These are addresses 0 through (256 * 256 * 1024)-1: addresses 0x0 through
0x3ffffff.
- Page 15 will be the middle page table pointing to the end of the stack.
This takes care of the last 0x10000 pages: pages 0x300000 to 0x3fffff.
(addresses 0xfc000000 to 0xffffffff).
- Page 16 will be the outer page table. Each PTE points to a middle page
table entry, which stands for 0x4000000 addresses. Thus there are 64
such PTE's (0x100000000 / 0x4000000) = 0x40 = 64.
Here's a high level picture with arrows. Physical frame numbers are
inside the boxes.
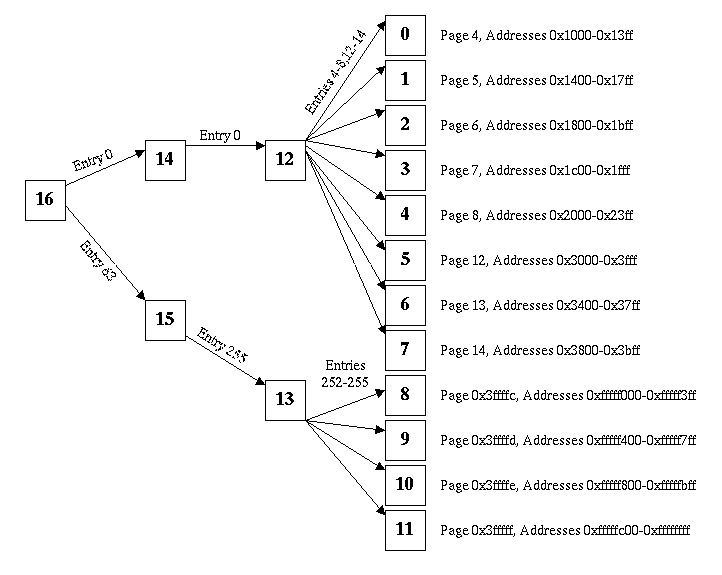 We'll do the final drawing using ASCII art. I'm not going to draw pages
0 through 11, since they are user pages. The PTBR contains the value
16, for the outer page table.
Here are the pages:
We'll do the final drawing using ASCII art. I'm not going to draw pages
0 through 11, since they are user pages. The PTBR contains the value
16, for the outer page table.
Here are the pages:
Page 12: Inner page table for addresses 0-0x40000
Frame v w x
|--------------------------|
| 0 0 0 0 | (Page 0 - invalid)
| 0 0 0 0 | (Page 1 - invalid)
| 0 0 0 0 | (Page 2 - invalid)
| 0 0 0 0 | (Page 3 - invalid)
| 0 1 0 1 | (Page 4 - code)
| 1 1 0 1 | (Page 5 - code)
| 2 1 0 1 | (Page 6 - code)
| 3 1 0 1 | (Page 7 - code)
| 4 1 1 0 | (Page 8 - globals)
| 0 0 0 0 | (Page 9 - invalid)
| 0 0 0 0 | (Page 10 - invalid)
| 0 0 0 0 | (Page 11 - invalid)
| 5 1 1 0 | (Page 12 - heap)
| 6 1 1 0 | (Page 13 - heap)
| 7 1 1 0 | (Page 14 - heap)
| 0 0 0 0 | (Page 15 - invalid)
....
| 0 0 0 0 | (Page 255 - invalid)
|--------------------------|
Page 13: Inner page table for addresses 0xfffc0000 to 0xffffffff
Frame v w x
|--------------------------|
| 0 0 0 0 | (Page 0x3ffc00 - invalid)
....
| 0 0 0 0 | (Page 0x3ffffb - invalid)
| 8 1 1 0 | (Page 0x3ffffc - stack)
| 9 1 1 0 | (Page 0x3ffffd - stack)
| 10 1 1 0 | (Page 0x3ffffe - stack)
| 11 1 1 0 | (Page 0x3fffff - stack)
|--------------------------|
Page 14: Middle page table for addresses 0-0x3ffffff
Frame v w x
|--------------------------|
| 12 1 1 1 | (PTE 0 - for pages 0-255)
| 0 0 0 0 | (PTE 1 - for pages 256-511)
...
| 0 0 0 0 | (PTE 255)
|--------------------------|
Page 15: Middle page table for addresses 0xfc000000-0xffffffff
Frame v w x
|--------------------------|
| 0 0 0 0 |
...
| 0 0 0 0 |
| 13 1 1 0 | (PTE for pages 0x3ffc00-0x3fffff)
|--------------------------|
Page 16: Outer page table
Frame v w x
|--------------------------|
| 14 1 1 1 | (PTE 0 for addresses 0x0 - 0x3ffffff)
| 0 0 0 0 | (PTE 1 for addresses 0x4000000 - 0x7ffffff)
...
| 0 0 0 0 | (PTE 62 for addresses 0xf8000000 - 0xfbffffff)
| 15 1 1 0 | (PTE 63 for addresses 0xfc000000 - 0xffffffff)
|--------------------------|
Part 3
So, this scheme uses 16 pages. Yes, page translation can take 3 memory
lookups, but this can be optimized away by a TLB with good locality.
In a single-level page table, you would have to have 0x400000
PTE's, since you need to access pages 4 through 0x3fffff. That means
0x1000 pages = 1M for the page table. Just for 12 user pages! Clearly,
the 3-level page table is far preferable.
Question 1: Grading: 15 points
- Part 1: 4 points. 1 for the 10-bit offset, 1 for the 6-bit outer PT,
1 for the 8-bit inner/middle PT's, and 1 for having the inner and middle PT
sizes match.
- Part 2: 9 points. 2 for the outer page table page,
2 for the middle page table pages,
2 for the inner page table pages,
2 for the protection bits,
1 for good use of numbers (instead of arrows).
- Part 3: 2 points.
Question 2
Since the cache is on physical addresses, you must do address translation
through the TLB:
Part 1
- Path 1: Page translation is in the TLB, data is in the cache -- very fast.
- Path 2: Page translation is in the TLB, but the data is not in the cache --
this is slower as it requires the word to be loaded from memory.
- Path 3: Page translation is not in the TLB. This is the slowest, because
the page translation has to be regenerated from all the page tables
(requiring three memory accesses), and the word has to be loaded
from memory. Thus, this requires 4 memory transactions.
Part 2
- The time for path 1 is H. Its probability is TC. So its contribution
is TCH.
- The time for path 2 is (M+W). Its probability is T(1-C). So its contribution
is T(1-C)(M+W).
- The time for path 3 is 4W. Its probability is (1-T). So its contribution
is (1-T)(4W).
- So, the total is
TCH + T(1-C)(M+W) + (1-T)(4W). Note, all those probabilities
add up to one.
Question 2: Grading: 9 points
- 1.5 points each for the three paths.
- 1.5 points each for the three terms contributing to the EMA time.
Question 3
Each user program, at any point in its execution, has a working set. This
is the set of all pages accessed within the last delta instructions.
Obviously, a program with lots of locality will have a smaller working set
than a program with little locality.
The medium term scheduler can use working sets as follows. If the system
can keep track of the working set size of all processes currently running,
then, whenever the sum of the sizes of all processes' working sets is
greater than the size of physical memory, the medium term scheduler can
select processes to swap out. Otherwise, by definition, the system
will thrash. Similarly, if the size of all resident processes' working
sets is much less than the size of physical memory, the medium term
scheduler can swap processes back in.
Question 3: Grading: 5 points
Three points for your definition of a working set, and two points for
how the medium-term scheduler uses it. Note, a working set is not
the last n pages touched. It is defined in terms of the last
delta executed instructions.
Question 4
A capability is a pointer to a resource. Typically a capability is presented
to whatever system is managing the resource, and the contents of the capability
are used to determine whether the resource may be used by the owner of the
capability. For this reason, capabilities are often called keys,
since the ownership of the key is sufficient to unlock the resource. This
is as opposed to an access list approach to protection, where the identity
of the user is typically employed to determine whether he/she may use the
resource. Capabilities may be seen as caches of authentication information,
because in order to get a capability, the user must be authenticated and
authorized to obtain the capability. Typically, this is a time-consuming
process. Once the user has the capability, authenticating the capability
is typically quick. Thus, the capability may be seen as a cache of the
authentication and authorization. As an example, consider a Unix file
descriptor. You get a file descriptor via an open() call, which
does the authentication/authorization, often requiring a disk read. After that,
file operations use
the file descriptor so that they don't have to re-preform the authorization
at every step.
Question 4: Grading: 5 points
Three points for your definition of a capability, and two points for
why it can be seen as a cache.
Question 5
Here's the easy code. It goes through the following steps:
- Try to read the block from the proper disk into the buffer.
- If that is successful, then return.
- If that is unsuccessful, then zero out the buffer, and then
sequentially read all other disks from that stripe, and XOR them on top of
the buffer. This will recreate the failed block.
Use the disk_start_sems to make sure that only one call
to start_disk_read() is outstanding per disk.
void read_disk_block(int block, char *buffer)
{
int real_disk;
int real_block;
int i;
char temp[4096];
real_disk = block % 4;
real_block = block / 4;
P(disk_start_sems[real_disk]); /* Wait for other start_disk_read calls */
start_disk_read(real_disk, real_block, buffer);
P(disk_end_sems[real_disk]); /* Wait for the read to complete */
V(disk_start_sems[real_disk]); /* Allow for other start_disk_read calls */
if (disk_errors[real_disk] == 0) return; /* If successful, return */
for (i = 0; i < 4096; i++) buffer[i] = 0; /* Zero the buffer */
for (d = 0; d < 5; d++) {
if (d != real_disk) {
P(disk_start_sems[d]); /* Read block from the stripe */
start_disk_read(d, real_block, temp);
P(disk_end_sems[d]);
V(disk_start_sems[d]);
if (disk_errors[d] != 0) panic();
for (i = 0; i < 4096; i++) { /* XOR it in */
buffer[i] = buffer[i] ^ temp[i];
}
}
}
}
Now the extra credit code. Here if you have failure, you want to read all the
other disks simultaneously. However, which disks are free and which ones aren't?
And which ones will finish quickly? You don't have to care -- just fork off
a separate thread for each read, and use a mutex to protect the buffer:
typedef struct {
int disk;
int block
char *buffer;
kt_sem lock;
void *thread;
} info;
void read_parity_block(void *arg)
{
info *in;
char temp[4096];
int i;
in = (info *) arg;
P(disk_start_sems[in->disk]); /* Wait for other start_disk_read calls */
start_disk_read(in->disk, in->block, temp);
P(disk_end_sems[in->disk]);
V(disk_start_sems[in->disk]);
if (disk_errors[in->disk] != 0) panic();
P(in->lock);
for (i = 0; i < 4096; i++) in->buffer[i] = in->buffer[i] ^ temp[i];
V(in->lock);
return;
}
void read_disk_block(int block, char *buffer)
{
int real_disk;
int real_block;
int i;
info in[5];
real_disk = block % 4;
real_block = block / 4;
P(disk_start_sems[real_disk]); /* Wait for other start_disk_read calls */
start_disk_read(real_disk, real_block, buffer);
P(disk_end_sems[real_disk]); /* Wait for the read to complete */
V(disk_start_sems[real_disk]); /* Allow for other start_disk_read calls */
if (disk_errors[real_disk] == 0) return; /* If successful, return */
for (i = 0; i < 4096; i++) buffer[i] = 0; /* Zero the buffer */
lock = make_kt_sem(1);
for (d = 0; d < 5; d++) { /* Fork off the threads */
if (d != real_disk) {
in[d].disk = d;
in[d].block = real_block;
in[d].buffer = buffer;
in[d].lock = lock;
in[d].thread = kt_fork(read_parity_block, (void *) (in+d));
}
}
for (d = 0; d < 5; d++) kt_join(in[d].thread); /* Wait for the result */
kill_kt_sem(lock);
}
Question 5: Grading: 13 points
- Reading the right block from the right disk: 2 points
- Using disk_start_sems properly: 2 points
- Using disk_end_sems properly: 2 points
- Returning correctly on success: 1 point
- Zeroing a buffer (or correctly not having to zero a buffer): 1 point
- Reading properly from the remaining disks: 2 points
- Panicing properly on a multiple disk failure: 1 point
- Doing correct parity operations: 1 point
- Returning properly after calculating parity (including freeing used
memory and threads).
- You received extra credit for having all disks doing their parity reads
at the same time (but not for having all 5 disks going at one time).