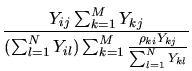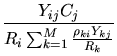Todd L. Graves* and Audris Mockus+
*National Institute of Statistical Sciences and *+Bell
Laboratories
The application which inspired the development of this algorithm arises in software engineering. It is desired to know what factors affect the effort required for a developer to make a change to the software: for instance, to identify difficult areas of the code, measure changes in the code difficulty through time, and evaluate the effectiveness of development tools. Unfortunately, measurements of effort for changes are not available in historical data. We model change effort using a developer's total monthly effort and information about which changes she worked on in each month. We produce measures of uncertainty in the estimated model coefficients using the jackknife by omitting one developer at a time. We illustrate a few specific applications of our tool, and present a simulation study which speaks well of the reliability of the results our algorithm produces. In short, this algorithm allows analysts to identify if and how much impact a promising software engineering tool or practice has on coding effort.
A particularly important quantity related to software is the cost of making a change to it. Large software systems are maintained using change management systems, which record information about all the changes programmers made to the software. These systems record a number of measurements on each change, such as its size and type, which one expects to be related to the effort required to make the change. In this paper we discuss the methodology and algorithms we have developed to assess the influence of these factors on software change effort.
Since change management data do not include measurements of the effort that was required to make a change, it is at first difficult to imagine estimating models for change effort. The effort estimates are often obtained for very large changes like new releases, but is important to study effort at the level of individual changes, because at coarser aggregation levels, qualities affecting the effort of individual changes are likely not to be estimable because of aggregation. Therefore, our methodology makes use of two types of known information: the total amount of effort that developer expends in a month, and the set of months during which a developer worked on a given change.
This gives rise to an ill-posed problem in which developers' monthly efforts represent the known column marginal totals of several two-way tables, and we also know which entries in these sparse tables are strictly positive. Also, we postulate the form of a model for the unobservable row marginal totals (amounts of effort for each change) as a function of several observed covariates. Our algorithm then iterates between improving the coefficients in the model for effort using imputed values of change effort, and adjusting the imputed values so that they are consistent with the known measurements of aggregated effort. We have called this algorithm MAIMED, for Model-Assisted Iterative Margin Estimation via Disaggregation. Uncertainty estimates for the model coefficients can then be obtained using the jackknife (Efron, 1982), in which each replication omits one of the two-way tables (developers). We anticipate that this methodology will be useful in other sorts of problems where individuals produce units of output, cost information is available only in units of time, and where the variables affecting productivity operate on the level of the output units.
This methodology has enormous potential for serving as a foundation for a variety of historical studies of software change effort. One example from this research is our finding that the code under study ``decayed'' in that changes to the code grew harder to make at a rate of 20% per year. We were also able to measure the extent to which changes which fix faults in software are more difficult than comparably sized additions of new functionality: fault fixes can be as much as 80% more difficult. (Difficulty of fixing bugs relative to new feature addition depends strongly on the software project under study, and the results from our analyses are consistent with the opinions of developers on those projects.) Other findings include evidence that a development tool makes developers more productive, and confirmation that a collection of subsystems believed to be more difficult than others in fact required measurably more effort to make an average change.
We present recommendations on using the estimation method in practice, discuss alternative approaches and present a simulation study to confirm accuracy, sensitivity to outliers, and convergence of the method.
The next section defines the estimation algorithm. §3 contains more detailed discussion of the data available in the software engineering context, and describes three sample data analyses using this algorithm. §4 describes our simulation study, §5 explains why more familiar approaches such as the EM algorithm were prohibitively difficult, §6 describes the software used to perform the estimation, and §7 gives our conclusions. We include an appendix §8 which describes some theoretical insight into the convergence properties of the algorithm.
In this section we discuss the procedure to estimate models for change
effort. Consider the data corresponding to a single developer d.
These data may be thought of as a non-negative two-way table,
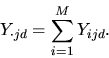
The estimation procedure is inspired by iterative proportional fitting (IPF; see Deming and Stephan, 1940), a technique for estimating cell values in a multi-way table of probabilities when marginal totals are known and a sample from the population is available. IPF alternates (in the two-way case) between rescaling the rows so that the cells sum to the correct row totals, and performing the same operation on the columns, until a normally rapid convergence. In our problem only one of the margins is known, we postulate a model for the quantities given by the other margin, and knowledge of the zero pattern takes the place of the sample. After generating initial guesses at the cell values in the table, our algorithm alternates between making the cell values consistent with the column sums, and fitting a model to the resultant row sums, then rescaling cell values to be consistent with the model's fitted values.
To be more precise, we first generate initial values for the cells in the
two-way tables. A natural approach is to divide each column total evenly
across all the nonzero entries in that column:
The following steps are then repeated until convergence.
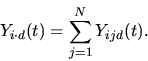
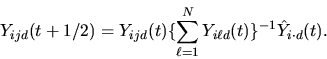
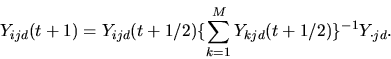
At convergence, the algorithm reports the coefficients estimated in the model fitting during the last iteration.
Since these regression coefficients are obtained using an iterative
algorithm and a number of fitted regressions, it is necessary to
measure their uncertainties using a nonparametric method which takes
the estimation procedure into account. The jackknife (see, for
instance, Efron, 1982) supplies a method of estimating uncertainties
in estimated parameters by rerunning the estimation algorithm once for
each data point in the sample, each time leaving one of the data
points out. A collection of estimated parameters results, and the
degree of difference between these parameters is related to the
sampling variability in the overall estimate. For example, suppose
that the statistic of interest is denoted by
![]() ,
which was
computed from a dataset of size n. What is required is an estimate
of the standard error of
,
which was
computed from a dataset of size n. What is required is an estimate
of the standard error of
![]() .
For
.
For
![]() ,
compute
,
compute
![]() using the data set with the ith
observation deleted. Set
using the data set with the ith
observation deleted. Set
![]() .
The jackknife estimate of standard error of
.
The jackknife estimate of standard error of
![]() is
is
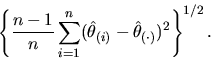
An alternative to the jackknife is the bootstrap (for which see Efron and Tibshirani, 1993, for example). Owing to the time-consuming iterative algorithm, we preferred the jackknife since it required only one additional run of the algorithm for each of the developers. For the purposes of resampling, we have only one datapoint for each developer, because omitting some of a developer's changes leaves some months in which the total effort of the changes is less than the observed monthly effort. Omitting some months will break up changes whose lifetimes span those months, making it impossible to define the total effort for such a change.
Change history is a promising new tool for measuring and analyzing software evolution (Mockus et al, 1999). Change histories are automatically recorded by source code control and change management systems (see 3.1). Every change to every part of the source code is recorded by the change control system, providing a repository of software modifications which is large, detailed, and uniform over time. Obtaining data for software engineering research relevant to an industrial environment can be difficult and costly; change management data are collected automatically.
In our studies, the data represent changes to the source code of 5ESS (Martersteck and Spencer, 1985), which is a large, distributed, high availability software product. The product was developed over two decades, has tens of millions of lines of source code, and has been changed several hundred thousand times. The source code is mostly written in the C programming language, augmented by the Specification and Description Language (SDL). Tools used to process and analyze software change data are described in Mockus et al, 1999.
The change management (CM) data include information on each change
made to the code, its size and content, submission time, and
developer. Also available are financial support system (FSS) data,
which record amounts of effort spent each month by each developer.
Because developers tend to work on multiple changes during most
months, and because 14 percent of changes start and end in different
months, it is impossible to recover effort measurements for individual
changes exactly from these FSS data. In fact, developers' monthly
efforts rarely stray far from their natural value of one month, so in
most applications we have used
![]() in place of the
FSS data, which in any case are not always available.
in place of the
FSS data, which in any case are not always available.
The extended change management system (ECMS; see, for example, Midha, 1997), and the source code control system (SCCS; Rochkind, 1975) were used to manage the source code. The ECMS groups atomic changes (``deltas'') recorded by SCCS into logical changes referred to as Maintenance Requests (MRs). The open time of the MR is recorded in ECMS. Also available are records of the MR completion time; we use the time of the last delta in that MR. We used the textual abstract that the developer wrote when working on an MR to infer that change's purpose (Mockus and Votta, 1998). In addition to the three primary reasons for changes (repairing faults, adding new functionality, and improving the structure of the code; see, for example, Swanson, 1976), we defined a class for changes that implement code inspection suggestions since this class was easy to separate from others and had distinct size and interval properties (Mockus and Votta, 1998).
The SCCS database records each delta as a tuple including the actual source code that was changed, login of the developer, MR number, date, time, numbers of lines added, deleted, and unchanged.
There a number of practical issues when modeling change effort. Some are typical to all statistical problems, some specific to software engineering, and some specific to the MAIMED fitting procedure. Here we omit the traditional validity checks in regression analysis such as collinearity among predictors and dwell mostly on issues related to software engineering and the MAIMED procedure. Two particularly important issues are including essential predictors in the model and choosing subsets of the data.
In our studies of software data, we have found that several variables should always be included in the regression models and that their effects on effort are always present. One can include other variables to test whether they have important effects.
First among variables that we recommend always including in the model is a developer effect. Other studies (for example, Curtis, 1981) have found substantial variation in developer productivity. Even when we have not found significant differences and even though we do not believe that estimated development coefficients constitute a reliable method of rating developers, we have left developer coefficients in the model. The interpretation of estimated developer effects is problematic. Not only could differences appear because of differing developer abilities, but the seemingly less productive developer could be the expert on a particularly difficult area of the code, or that developer could have more extensive duties outside of writing code.
Naturally, the size of a change has a strong effect on the effort required to implement it. A large number of measures are available which measure something closely related to size, and the analyst should generally include exactly one of these in the model. We have typically chosen the number of atomic changes (deltas) that were part of the MR as the measure of the size of an MR. This measure seems to be slightly better for this purpose than other size measures like the total number of lines added and deleted in the MR. Another useful measure of size is the span of the change, i.e., the number of files it touches. A large span tends to increase the effort for a change even if other measures of size are constant.
We found that the purpose of the change (as estimated using the techniques of Mockus and Votta, 1998) also has a strong effect on the effort required to make a change. In most of our studies, changes which fix bugs are more difficult than comparably sized additions of new code. Difficulty of changes classified as ``cleanup'' varies across different parts of the code, while implementing suggestions from code inspections is easy.
Another important problem when using MAIMED methodology is choosing a set of developers whose changes to include in the analysis. The 5ESSTMhas been changed by a large number of developers, and we recommend restricting attention to a subset of these, with the subset chosen in order to yield the sharpest possible estimates of the parameters of interest.
Variability in project size and developer capability and experience are the largest sources of variability in software development (see, for example, Curtis, 1981). The effects of tools and process are often smaller by an order of magnitude. To obtain the sharpest results on the effect of a given tool in the presence of developer variability, it is important to have observations of the same developer changing files both using the tool and performing the work without the aid of the tool.
To reduce inherently large naturally occurring inter-developer variability, it is important to select developers who make similar numbers of changes.
To avoid confounding tool effects (see §3.3.2) with developers, it is imperative to choose developers who make similar number of changes with and without the tool. When estimating code-base effects (see §3.3.3), it is important to select developers who make similar numbers of changes on each type of product.
Given the considerable size of the version history data available, both tasks are often easy: in the tool effect study we selected developers who made between 300 and 500 MRs in the six year period between 1990 and 1995 and had similar numbers (more than 40) of MRs done with and without the tool.
We used relatively large samples of MRs in all three examples below. When comparing subsystems, we used 6985 MRs over 72 months to estimate 18 developer coefficients and 6 additional parameters. When analyzing the tool benefits, we used 3438 MRs over 72 months for 9 developers and five additional parameters.
The specific model we fit in the modeling stage of the algorithm was a
generalized linear model (McCullagh and Nelder, 1989) of effort. MR
effort was modeled as having a Poisson distribution with mean given
below.1
Beyond developer, size, and type of change, another interesting
measurement on a change which we have found to be a significant
contributor to the change's difficulty is the date of the change
(Graves and Mockus, 1998). We were interested to see if there was
evidence that the code was getting harder to change, or
decaying, as discussed in Belady and Lehman (1976), Parnas
(1994), and Eick et al (1999). There was statistically
significant evidence of a decay effect: we estimated that in our data,
a change begun a year later than an otherwise similar change would
require 20% more effort than the earlier change. The fitted model
was:
Here the estimated developer coefficients, the ![]() 's, varied by a
factor of 2.7. The jackknife estimate of standard error (see
§2.2) indicated that there was no statistically
significant evidence that the developers were different from each
other. Although we sometimes find quotes in the
literature (Curtis, 1981)
regarding the maximal productivity ratio for developers
ranging from 10 times to 100 times, we were not surprised to see a
much smaller ratio in this situation.
For one thing, we selected developers in a way which helps ensure
that they are relatively uniform, by requiring that they completed
large numbers of changes.
One should also expect a great deal of variation in these ratios
across studies, because they are based on the extreme developers
in the studies and hence are subject to enormous variability.
Also, we believe that there are a number of tasks beyond coding
(requirements, inspections, architecture, project management) that
take substantial time from developers involved in such tasks.
Consequently, the coding productivity does not necessarily reflect
the total productivity or the overall value of the developer to an
organization.
's, varied by a
factor of 2.7. The jackknife estimate of standard error (see
§2.2) indicated that there was no statistically
significant evidence that the developers were different from each
other. Although we sometimes find quotes in the
literature (Curtis, 1981)
regarding the maximal productivity ratio for developers
ranging from 10 times to 100 times, we were not surprised to see a
much smaller ratio in this situation.
For one thing, we selected developers in a way which helps ensure
that they are relatively uniform, by requiring that they completed
large numbers of changes.
One should also expect a great deal of variation in these ratios
across studies, because they are based on the extreme developers
in the studies and hence are subject to enormous variability.
Also, we believe that there are a number of tasks beyond coding
(requirements, inspections, architecture, project management) that
take substantial time from developers involved in such tasks.
Consequently, the coding productivity does not necessarily reflect
the total productivity or the overall value of the developer to an
organization.
We defined
![]() ,
the coefficient for changes that add
new functionality, to be unity to make the problem identifiable, then
estimated the remaining type coefficients to be 1.8 for fault fixes,
1.4 for restructuring and cleanup work, and 0.8 for inspection rework.
,
the coefficient for changes that add
new functionality, to be unity to make the problem identifiable, then
estimated the remaining type coefficients to be 1.8 for fault fixes,
1.4 for restructuring and cleanup work, and 0.8 for inspection rework.
The value of ![]() ,
which is the power of the number of files
changed which affects effort, we estimated to be 0.26, and its
jackknife standard error estimate is 0.06. Since
,
which is the power of the number of files
changed which affects effort, we estimated to be 0.26, and its
jackknife standard error estimate is 0.06. Since ![]() ,
for
these data, the difficulty of a change increases sub-linearly with the
change's size. At first glance this may appear to conflict with
intuition and, for example, the COCOMO model for effort prediction
(Boehm, 1981) one expects that the effort for a change
should be very nearly proportional to the size of the change. This
expectation is reasonable in the context of large changes, such as
entire projects, which contain mixtures of small changes of various
types. When considering changes as small as MR's, a sublinear result
should not be surprising. Large changes are often additions of new
functionality and may be mostly straightforward, while small changes
and often bug fixes, which may require large initial investments of
time to find where to make the change.
,
for
these data, the difficulty of a change increases sub-linearly with the
change's size. At first glance this may appear to conflict with
intuition and, for example, the COCOMO model for effort prediction
(Boehm, 1981) one expects that the effort for a change
should be very nearly proportional to the size of the change. This
expectation is reasonable in the context of large changes, such as
entire projects, which contain mixtures of small changes of various
types. When considering changes as small as MR's, a sublinear result
should not be surprising. Large changes are often additions of new
functionality and may be mostly straightforward, while small changes
and often bug fixes, which may require large initial investments of
time to find where to make the change.
We estimated ![]() to be 1.21, and its natural logarithm had a
standard error of 0.07, so that a confidence interval for
to be 1.21, and its natural logarithm had a
standard error of 0.07, so that a confidence interval for ![]() calculated by taking two standard errors in each direction of the
estimated parameter is
calculated by taking two standard errors in each direction of the
estimated parameter is
![]() This implies that a similar change became 5% to 39% harder to make in
one year.
This implies that a similar change became 5% to 39% harder to make in
one year.
This section tests our hypothesis that the use of a tool reduces the effort needed to make a subset of changes. The tool in this study was the Version Editor, which was designed to make it easier to edit software which is simultaneously developed in several different versions. It does this by hiding all lines of code which belong to versions the developer is not currently working on (for details see Atkins et al (1999). There were three types of changes:
We fit the model (Equation 5, estimated standard errors using the jackknife method, and obtained the following results, as summarized in Table 1.
The penalty for failing to use the tool is the ratio of
![]() to
to
![]() ,
which indicates an increase of
about 36% in the effort required to complete an MR. (This
coefficient was statistically significant at the 5% level).
Restated, developers who used the tool to perform non-control
changes could perform 36% more changes than if they had used the
tool. At the same time, changes performed using the tool were of the same
difficulty (requiring a statistically insignificant 7% increase in
effort) as CONTROL changes (
,
which indicates an increase of
about 36% in the effort required to complete an MR. (This
coefficient was statistically significant at the 5% level).
Restated, developers who used the tool to perform non-control
changes could perform 36% more changes than if they had used the
tool. At the same time, changes performed using the tool were of the same
difficulty (requiring a statistically insignificant 7% increase in
effort) as CONTROL changes (
![]() versus
versus
![]() ).
).
The type of a change was a significant predictor of the effort required to make it, as bug fixes were 26% more difficult than comparably sized additions of new functionality. Improving the structure of the code, the third primary reason for change was of comparable difficulty to adding new code, as was a fourth class of changes, implementing code inspection suggestions.
The variable ![]() in Equation (3) was estimated to be
0.19. That is, the size of a change did not have a particularly strong
effect on the effort required to make it.
in Equation (3) was estimated to be
0.19. That is, the size of a change did not have a particularly strong
effect on the effort required to make it.
In the last example we considered the influence of code-base on effort. The 5ESS switch (the product under discussion) is broken into a number of relatively independent subsystems (each several million lines of code) that belong to and are changed by separate organizations. This product is updated by adding new features or capabilities that can then be sold to customers. An average feature contains tens to hundreds of MRs.
A development manager identified six subsystems that tend to have
higher cost per feature than another six similar sized subsystems. To
identify whether the effort was higher even at the MR level, we chose 18
developers who made similar numbers of changes to high- and low-cost
subsystems. We fit the model (6). The
estimates are summarized in Table 2.
Since
![]() ,
the results show that similar MRs take
about 28% more effort in the high cost subsystems.
,
the results show that similar MRs take
about 28% more effort in the high cost subsystems.
To provide confirmation that the effort modeling methodology gives adequate results, we conducted a simulation experiment. We simulated data from a specified model and measured to what extent the model coefficients are recoverable using the MAIMED algorithm. In particular, we study the influence of the initialization method, and the effect of incorrectly specified monthly efforts (§4.3). We also studied what happens to estimated coefficients when we fit models without one of the essential variables, or with an extra variable which does not itself affect effort but which is correlated with one of the predictor variables (§4.4).
The simulation is in part a bootstrap analysis of the data. It begins with a model fit to a set of data. We used the model from the tool usage exampleEquation 5 and the estimated coefficients from Table 1.
Each replication in the experiment consists of the following. We resample with replacement a set of developers. The set of developers in the simulated data consists of a random number of copies of each of the developers in the true data set. We then construct a collection of MRs for a synthetic developer by resampling MRs of the corresponding actual developer. More precisely, we do the following.
This simulation procedure preserves the correlations between all the variables in the model, except for time. In the simulations, the covariates and effort for MRs are independent of the covariates and effort of the previous MRs. Since the actual MRs do overlap we also generated overlaps based on the actual MR overlap data (see §4.1).
We repeated this procedure to generate 100 synthetic data sets, and estimated parameters for the correct model with these data sets. We checked the sensitivity to initialization method and to incorrectly specified monthly efforts. Finally, we use our algorithm to fit models on these data when we misspecify the model by omitting an important variable or by adding an unnecessary variable.
(The reader may find it strange that we simulate exponential data, which have constant coefficient of variation, and model these data as if they were Poisson, which have constant variance to mean ratio. This is intentional; we believe from other studies that the true data have constant coefficient of variation, but the larger changes are not only more variable, but also more important to model correctly. We believe coefficients from a Gamma model are too dependent on the smaller observations.)
Overlap between MRs is an important component of the software
engineering problem. One third of actual MRs have the property that
they are closed after a subsequent MR is opened. To produce a
realistic simulation, we had to reproduce MR overlap. Number the MRs
for a single developer in order of their open times Oi so that for
all i,
![]() .
Let Ci be the closing time of MR
i. The overlap is defined as follows:
.
Let Ci be the closing time of MR
i. The overlap is defined as follows:
![\begin{displaymath}OVL_i \stackrel{\rm def}{=}\left\{
\begin{array}[h]{ccc}
O...
...C_{i}-O_{i}} & {\rm if} & O_{i+1} \le C_{i}
\end{array}\right.
\end{displaymath}](img51.gif) |
(7) |
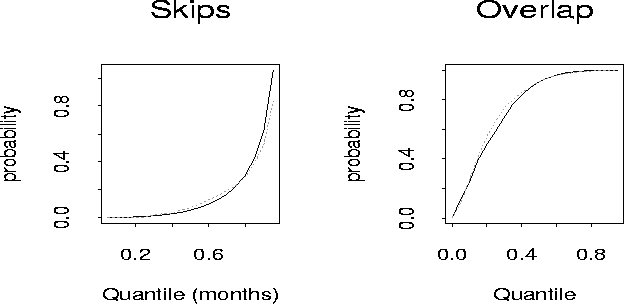 |
The overlap distribution indicates that when the overlap occurs, MRs are likely to be started at almost the same time. The skip distribution is fairly heavy tailed which is probably caused by vacation or other developer's activities not directly related to changing the code.
In all of the following the hundred data sets were simulated from
the model in Equation (5) with coefficients as in Table
1. Overlap of MRs was generated as described in
§4.1.
![]() are set to one (except in
Table 4) to reflect frequent situations in practice when
the actual monthly effort is not available or unreliable. The
algorithm in all cases is run for thirty iterations for each data
set.
are set to one (except in
Table 4) to reflect frequent situations in practice when
the actual monthly effort is not available or unreliable. The
algorithm in all cases is run for thirty iterations for each data
set.
Table 3 shows the means of the estimated coefficients and their standard deviations.
The estimates are biased because the monthly efforts are set to one to reflect practical situations when the actual monthly efforts are not known. Not surprisingly, setting all the monthly efforts to be equal causes all coefficients to be estimated to be closer to zero. Using unit monthly efforts is thus a conservative procedure which will generally err on the side of pronouncing too many factors to be unrelated to effort. In particular, the HAND coefficient is underestimated, suggesting that if the exact monthly efforts were known the effect of the tool usage would have been even larger.
First we check the sensitivity with respect to alternative initialization methods and with respect to variations in monthly effort.
The first initialization method in Equation (2)
divides monthly effort evenly among MRs open that month. We also
used an alternative initialization method which divides monthly
effort proportionally to the time each MR is open during that month:
The results are identical (up to two significant digits) to the results in Table 3, i.e., the initialization method does not affect the values of the estimated coefficients.
In the simulated data (more so than in practice) the monthly efforts
vary across months. In most cases monthly effort data is not
available, so we substitute unit effort. In other situations such
information is available (see, e.g., Graves and Mockus, 1998). In the
simulation we have the advantage of knowing the monthly MR efforts
exactly and can use this information in the initialization stage:
Typically such behavior would not cause a problem in practice (here, the cleanup and inspection coefficients were not significantly different from the new coefficient), because the uncertainty estimates will be large for coefficients estimated on the basis of a small number of such MRs. There were 15778 inspection and 30538 cleanup MRs (4.5% and 8.7% percent respectively) out of total 348204 MRs in the generated 100 samples. However, we recommend against using predictors that occur rarely in the data and which might be correlated with individual developers. Confounding helps explain the bias problem in this example, because the developer with the least productive coefficient has the smallest percentage, and the most productive developer has the highest percentage of inspection and cleanup MRs.
To test the behavior of the estimator under model misspecification we fitted the model omitting the size predictor and a set of models with correlated predictors.
Table 5 shows the estimates obtained by omitting the size
predictor. The estimates are not significantly different from the ones
obtained using the correct model in Table 3.
We also ran a sequence of tests by adding a coefficient correlated with the size covariate. Since the logarithm of the size was used in the model, the collinear covariate was correlated with the the logarithm of size. Medium correlation of 0.5 and high correlations of 0.8 and 0.95 were used. The results are in Table 6.
The results are as expected -- the collinear coefficient is not significantly different from zero and the model coefficients are not significantly different from those in Table 3. The collinear predictor increases uncertainty of the size coefficient, but does not affect the other estimates.
It is possible to think of this problem as a missing data problem, tempting one to attack it with the EM algorithm or data augmentation (see Tanner, 1993, for either). These approaches have serious difficulties with this problem. Taking EM as an example, it is necessary to specify distributions of the monthly effort expended on changes in such a way that is practical to compute conditional expectations given row sums and the parameters that determine mean change effort. Our two rescaling steps have the feel of an expectation step, but it is unclear whether one could construct a set of distributions under which they would be. Data augmentation has similar problems.
The problem of estimating network traffic from edge counts, considered in Vardi (1996), has some similarities with the present problem. There, numbers of traversals of each edge in a network are available, but the traffic for complete paths (sequences of connected edges) is of interest. Both problems deal with nonnegative quantities, and in each case linear combinations of quantities of interest are observed, since edge traffic is the sum over all the paths that traverse that edge.
The effort problem adds another layer of difficulty to the network
problem, in which it is desired to recover a vector X given a vector
Y of sums of the elements of X, satisfying the equation
Y=AX, for some known matrix of zeroes and ones A.
The difficulty is in the fact that there are more X's than
Y's. In the effort estimation problem we seek a collection of sums
X=A1 of unobservable quantities A, given another set of sums
![]() and the zero pattern of the matrix A. Auxiliary modeling
information relates to the desired collection of sums, while in the
network problem, it is the unsummed values which can potentially be
modeled.
and the zero pattern of the matrix A. Auxiliary modeling
information relates to the desired collection of sums, while in the
network problem, it is the unsummed values which can potentially be
modeled.
Although the algorithm is fairly simple to implement, we describe a set of functions in S-PLUS that would help practitioners use the methodology more readily. The code contains five S-PLUS functions:
Following is a detailed example analysis with some practical considerations. First, we create a data frame data using information retrieved from change management database using, for example, the SoftChange system (Mockus et al, 1999). Each MR should occupy a row in this data frame with the following fields: name containing the developer's name or login; bug, containing 1 if the change is bug fix (otherwise 0); clean containing 1 if the change is perfective; new containing 1 if the change is adaptive; ndelta containing size of the change in number of deltas; open and close representing timestamp of the first and the last delta (or open and close time for an MR) in unix time format (seconds since 1970); and additional factors ToolA and ToolB that indicates whether tool A or/and B were used to complete this MR.
First we select only MRs done by developers that completed at least 20 MRs with and without the tool. This might be done in following way:
usage.table <- table(data$name,data$usedX); name.subset <- table(data$name)[usage.table[,1]>20 & usage.table[,2]>20]; data.new <- data[match(data$name, name.subset, nomatch=0)>0,];
Now the dataframe data.new contains only developers that worked with and without the tool and hence we will be able to make sharper comparisons. In the next step we transform the open and close fields into fractional months starting at zero:
data.new$open <- data.new$open/3600/2/365.25; data.new$close <- data.new$close/3600/2/365.25 - min(data.new$open); data.new$open <- data.new$open - min(data.new$open);
We may also transform the size of the change by a logarithm:
data.new$logndelta <- log(data.new$ndelta+1);
Finally we may run the maimed algorithm to estimate the
coefficients for several models. One of the models might be:
| = | |||
model <- maimed (data.new, formula=c("name","logndelta","bug","clean","ToolA","ToolB"))
Notice that since in this example the categorization had three types
of changes (bug, clean, new) we included only first two in the
model. The remaining type (new) is used the basis for comparison
with the first two. If all the indicators were included we would get
an over determined model.
Once we find a subset of interesting models we estimate the significance of the coefficients via jackknife:
model <- maimed (data.new, formula=c("name","logndelta","bug","clean","ToolA","ToolB"),jk=T)
The result contains n+1 estimates of coefficients obtained by
running maimed algorithm on the full dataset and by removing one of
the N different developers. The significance values may be
calculated as follows:
maimed.validate(model.jk)This command may produce following output:
estimate stdev t-statistic p-value
lognumdelta 0.69179651 0.12414385 5.5725394 2.736186e-05
bug 0.63789480 0.18284625 3.4886950 2.621708e-03
clean -0.32523246 0.57564448 -0.5649884 5.790559e-01
ToolA -1.40700987 0.19134298 -7.3533393 7.966553e-07
ToolB 0.03172900 0.17362807 0.1827412 8.570436e-01
Developer1 -2.81395695 0.20994002 -13.4036235 8.338685e-11
Developer2 -2.08035974 0.18109041 -11.4879622 1.014959e-09
Developer3 -2.85884880 0.11088977 -25.7809968 1.110223e-15
Developer4 -2.85802540 0.17252158 -16.5661905 2.419842e-12
Developer5 -2.84639737 0.21325331 -13.3474946 8.934120e-11
Developer6 -2.58167088 0.19006092 -13.5833860 6.696665e-11
Developer7 -2.64266728 0.21459470 -12.3146901 3.322902e-10
We see that bug fixes are significantly harder than new code, and
tool A significantly reduces the change effort. Cleanup
(perfective) changes are not significantly easier than new code
chnages and Tool B is not significantly increasing change effort.
Hence for practical purposes the model may be rewritten using the
estimates above as
| = |
The constant multiplier is included with all developer coefficients. The ratio of the highest and the lowest coefficient is around two e-2.08/e-2.86=2.18.
This paper introduced a method for quantifying the extent to which properties of changes to software affect the effort necessary to implement them. The problem is difficult because measurements of the response variable, effort, are available only at an aggregated level. To solve this difficulty we propose an algorithm which imputes disaggregated values of effort, which can be improved by using a statistical model. The method may be applied to the problem of estimating a model for the row sums given only the column sums and zero pattern of an arbitrary sparse non-negative table.
We provided three examples of data analyses in which we used the new algorithm to address important questions in software engineering: monitoring degradation of the code as manifested by increased effort, quantifying the benefits of a development tool, and identifying subsystems of code which are especially difficult.
We explored the properties of the algorithm through simulation. The simulations demonstrated that given enough data, the algorithm can recover the parameters of a true model, and that the algorithm still performs well when an important variable is left out of the analysis or when an extra variable correlated with one of the true predictors is included in the model. Also, the algorithm is conservative in the frequent practical situation in which aggregated effort values must be assumed to be one unit of effort per month. Further justification for the algorithm of a theoretical nature appears in the appendix.
We also described how to use software which implements the algorithm (it is available for download) for the benefit of practitioners.
Each iteration of the method represents a nonlinear transformation of
the entries in the tables, of the row sums and of the fitted
coefficients. Without loss of generality assume that all rows
(changes) and all columns (months) have at least one positive entry.
In the notation that follows we will omit the dependence on the
developer d. We will often suppress the dependence on the iteration
t as well. For example, recall that
![]() denote entries for the i-th row and
j-th column at iteration t. Let
denote entries for the i-th row and
j-th column at iteration t. Let
![]() be
model predicted row sums (fitted values), based on the current row
sums
be
model predicted row sums (fitted values), based on the current row
sums
![]() .
Denote column sums as
.
Denote column sums as
![]() .
Then in the next iteration the entries
will be as follows:
.
Then in the next iteration the entries
will be as follows:
It is of interest when the algorithm stops.
Proof: It is easy to see that the algorithm does not modify entries where
Yij=0 or
Yij=Cj. Consider
subtables defined by connected rows. Without loss of generality
consider only one such subtable.
We will first prove the ``if'' part. Since the ratios
![]() ,
Equation (10) simplifies to
,
Equation (10) simplifies to
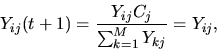
Denote transformation on rows performed by an algorithm as
![]() .
Denote the deviance defined by row values Ri, the MLE
estimate of the model
.
Denote the deviance defined by row values Ri, the MLE
estimate of the model ![]() given row values
given row values
![]() ,
and the
log-likelihood of the model
,
and the
log-likelihood of the model
![]() to be
to be
![]() .
With regard
to stability of a fixed point it is true that:
.
With regard
to stability of a fixed point it is true that:
Proof: Note that the constraints of the problem require
![]() .
Take
.
Take ![]() to be
small enough so that the perturbed table with cells
to be
small enough so that the perturbed table with cells
![]() where
where
![]() is valid (
is valid (
![]() ,
,
![]() )
and connected.
Denote the fitted values as
)
and connected.
Denote the fitted values as ![]() .
We denote the inner product between two vectors
.
We denote the inner product between two vectors
![]() by
by
![]() ,
and we will write
,
and we will write
![]() as
as
![]() .
We need to prove that
.
We need to prove that
To proceed further, we need the first order term of the transformation
Q. Denote
![]() to be deviation from the fixed point
value Yij in row i and column j (
to be deviation from the fixed point
value Yij in row i and column j (
![]() to
preserve monthly efforts and
to
preserve monthly efforts and
![]() .)
.)
| = | ![$\displaystyle \delta_i+\sum_j Y_{ij}\left[ \frac{(P\delta)_i}{(PR)_i} - \frac{\...
...lta_k}{R_k^2}-\frac{(PR)_k \delta_{kj}+Y_{kj}(P\delta)_{k}}{R_k}\right\}\right]$](img126.gif) |
||
| = | ![$\displaystyle \delta_i+ \sum_j Y_{ij}\left[ \frac{(P\delta)_i}{(PR)_i} - \frac{...
...m_kY_{kj}\left\{ \frac{\delta_k}{R_k}-\frac{(P\delta)_k}{(PR)_k}\right\}\right]$](img127.gif) |
||
| = | ![$\displaystyle \delta_i+ \sum_j Y_{ij}\left[ - \frac{\delta_i}{R_i} + \frac{1}{C_j}\sum_kY_{kj}\frac{\delta_k}{R_k}\right]$](img128.gif) |
||
| = | 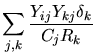 |
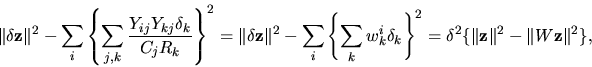
Let
![]() be the (orthonormal)
eigenvectors of W, with
be the (orthonormal)
eigenvectors of W, with
![]() the corresponding
eigenvalues, sorted in decreasing order of absolute value. Then
the corresponding
eigenvalues, sorted in decreasing order of absolute value. Then
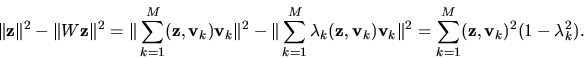
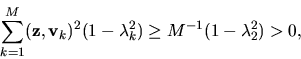
Because Q has a bounded third derivative, it is possible to choose
![]() small enough so for any
small enough so for any
![]() ,
the third order term in
(12) is smaller in absolute value than
,
the third order term in
(12) is smaller in absolute value than
![]() ,
which shows that (12) is strictly positive for all
,
which shows that (12) is strictly positive for all
![]() and for any
and for any
![]() .
.
![]()
Although the conditions of the theorem are restrictive, we believe they may be relaxed substantially. In particular, the result should be true for an arbitrary Gaussian or Poisson model and also for disconnected tables.
We thank George Schmidt, Janis Sharpless, Harvey Siy, Mark Ardis, David Weiss, Alan Karr, Iris Dowden, and interview subjects for their help and valuable suggestions. This research was supported in part by NSF grants SBR-9529926 and DMS-9208758 to the National Institute of Statistical Sciences.
L. A. Belady and M. M. Lehman, ``A model of large program development,'' IBM Systems Journal, pp. 225-252, 1976.
B. Boehm, Software Engineering Economics.
Prentice-Hall, 1981.
B. Curtis, ``Substantiating programmer variability,'' Proceedings of the IEEE, vol. 69, p. 846, July 1981.
W. E. Deming and F. F. Stephan, ``On a least-squares adjustment of a sampled frequency table when the expected marginal totals are known,'' Annals of Mathematical Statistics, vol. 11, pp. 427-444, 1940.
B. Efron, The Jackknife, the Bootstrap and Other Resampling Plans.
Philadelphia, PA: Society for Industrial and Applied Mathematics,
1982.
B. Efron and R. J. Tibshirani, An Introduction to the Bootstrap.
New York: Chapman and Hall, 1993.
S. G. Eick, T. L. Graves, A. F. Karr, J. S. Marron, and A. Mockus, ``Does code
decay? assessing the evidence from change management data,'' IEEE
Trans. Soft. Engrg., 1998.
To appear.
T. L. Graves and A. Mockus, ``Inferring change effort from configuration management data,'' in Metrics 98: Fifth International Symposium on Software Metrics, (Bethesda, Maryland), pp. 267-273, November 1998.
S. Karlin and H. M. Taylor, A First Course in Stochastic
Processes, 2nd Edition.
New York: Academic Press, 1975.
K. Martersteck and A. Spencer, ``Introduction to the 5ESS(TM) switching system,'' AT&T Technical Journal, vol. 64, pp. 1305-1314, July-August 1985.
P. McCullagh and J. A. Nelder, Generalized Linear Models, 2nd ed.
New York: Chapman and Hall, 1989.
A. K. Midha, ``Software configuration management for the 21st century,'' Bell Labs Technical Journal, vol. 2, no. 1, Winter 1997.
A. Mockus, S. G. Eick, T. Graves, and A. F. Karr, ``On measurement and analysis of software changes,'' tech. rep., Bell Labs, Lucent Technologies, 1999.
A. Mockus and L. G. Votta, ``Identifying reasons for software changes using
historic databases,''
Submitted to ACM Transactions on Software Engineering and
Methodology.
D. L. Parnas, ``Software aging,'' in Proceedings 16th International Conference On Software Engineering, (Los Alamitos, California), pp. 279-287, IEEE Computer Society Press, 16 May 1994.
M. Rochkind, ``The source code control system,'' IEEE Trans. on Software Engineering, vol. 1, no. 4, pp. 364-370, 1975.
G. Seber, Linear Regression Analysis.
New York: Wiley, 1977.
E. B. Swanson, ``The dimensions of maintenance,'' in 2nd Conf. on Software Engineering, (San Francisco, California), pp. 492-497, 1976.
M. A. Tanner, Tools for Statistical Inference.
New York, Berlin, Heidelberg: Springer-Verlag, 1993.
Y. Vardi, ``Network tomography: Estimating source destination traffic intensities from link data,'' JASA, vol. 91, no. 433, pp. 365-377, 1996.